チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
前のステップ
次のステップ
Step 5: T-SQLを使用したモデルのトレーニングと保存
このステップでは、Pythonパッケージであるscikit-learnとrevoscalepyを使用して、機械学習モデルをトレーニングする方法を学習します。これらのPythonパッケージは既にSQL Server Machine Learning Servicesと共にインストールされているため、モジュールをロードしてストアドプロシージャ内から必要な関数を呼び出すことができます。作成したデータ特徴を使用してモデルをトレーニングし、訓練されたモデルをSQL Serverのテーブルに保存します。
ストアドプロシージャTrainTestSplitでサンプルデータをトレーニングセットとテストセットに分割する
ストアドプロシージャTrainTestSplitはStep 2: PowerShellを使用したSQL Serverへのデータインポートを通じてSQL Serverに定義されています。
-
Management Studioのオブジェクトエクスプローラで、[プログラミング]、[ストアドプロシージャ]の順に展開します。
-
TrainTestSplitを右クリックし、[変更] を選択して新しいクエリウィンドウでTransact-SQLスクリプトを開きます。TrainTestSplitはnyctaxi_sampleテーブルのデータをnyctaxi_sample_trainingとnyctaxi_sample_testingの2つのテーブルに分割します。TrainTestSplitCREATE PROCEDURE [dbo].[TrainTestSplit] (@pct int) AS DROP TABLE IF EXISTS dbo.nyctaxi_sample_training SELECT * into nyctaxi_sample_training FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) < @pct DROP TABLE IF EXISTS dbo.nyctaxi_sample_testing SELECT * into nyctaxi_sample_testing FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) > @pct GO -
ストアドプロシージャを実行し、トレーニングセットに割り当てる割合を表す整数を入力します。たとえば、次の文は、トレーニングセットにデータの60%を割り当てます。トレーニングとテストのデータは、2つの別々のテーブルに格納されます。
EXEC TrainTestSplit 60 GO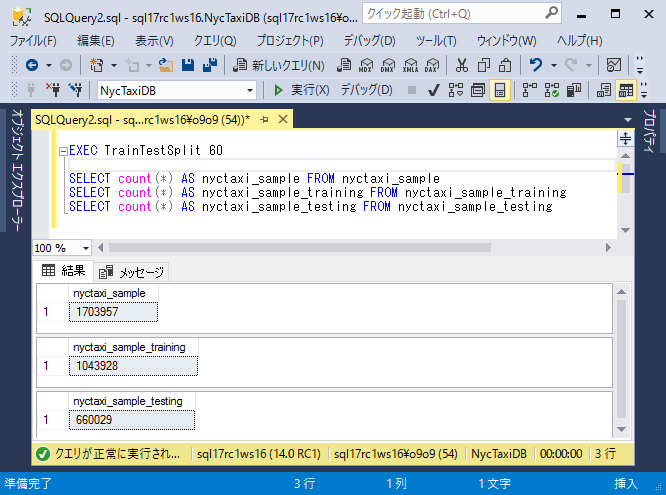
scikit-learnを使ってロジスティック回帰モデルを構築する
このセクションでは、作成したトレーニングデータを使用してモデルをトレーニングするストアドプロシージャを作成します。このストアドプロシージャはロジスティック回帰モデルをトレーニングするためにscikit-learn関数を使用します。これはシステムストアドプロシージャsp_execute_external_scriptを使用して、SQL ServerとともにインストールされたPythonランタイムを呼び出すことで実装しています。
新しいトレーニングデータをパラメータとして定義しシステムストアドプロシージャsp_execute_exernal_scriptの呼び出しをラップするストアドプロシージャを作成することで、モデルの再トレーニングを容易にしています。
ストアドプロシージャTrainTipPredictionModelSciKitPyはStep 2: PowerShellを使用したSQL Serverへのデータインポートを通じてSQL Serverに定義されています。
-
Management Studioのオブジェクトエクスプローラで、[プログラミング]、[ストアドプロシージャ]の順に展開します。
-
TrainTipPredictionModelSciKitPyを右クリックし、[変更] を選択して新しいクエリウィンドウでTransact-SQLスクリプトを開きます。TrainTipPredictionModelSciKitPyDROP PROCEDURE IF EXISTS TrainTipPredictionModelSciKitPy; GO CREATE PROCEDURE [dbo].[TrainTipPredictionModelSciKitPy] (@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle # import pandas from sklearn.linear_model import LogisticRegression ##Create SciKit-Learn logistic regression model X = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] y = numpy.ravel(InputDataSet[["tipped"]]) SKLalgo = LogisticRegression() logitObj = SKLalgo.fit(X, y) ##Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO -
次のSQL文を実行して、トレーニングされたモデルをnyc_taxi_modelsテーブルに登録します。
T-SQLDECLARE @model VARBINARY(MAX); EXEC TrainTipPredictionModelSciKitPy @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('SciKit_model', @model);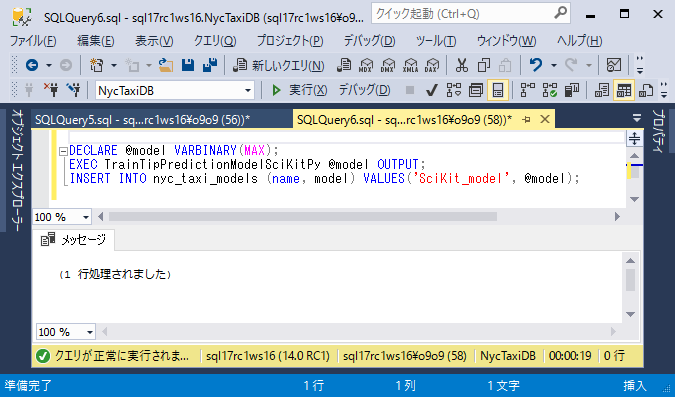
-
nyc_taxi_modelsテーブルに新しいレコードが1つ追加され、シリアライズされたモデルが登録されていることを確認します。
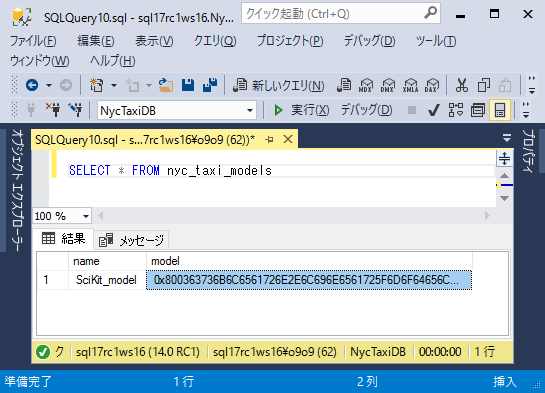
revoscalepyパッケージを使用してロジスティック回帰モデルを構築する
次に、新しいリリースとなるRevoScalePyパッケージを使用したストアドプロシージャTrainTipPredictionModelRxPyによってロジスティック回帰モデルをトレーニングします。Python のRevoScalePyパッケージには、RのRevoScaleRパッケージで提供されるものと同様のオブジェクト定義やデータ加工処理、機械学習のためのアルゴリズムが含まれています。このライブラリによって、ロジスティックや線形回帰、デシジョンツリーなどの一般的なアルゴリズムを使用した予測モデルのトレーニングや、計算コンテキストの作成、計算コンテキスト間のデータ移動、データ加工処理ができます。RevoScalePyの詳細はIntroducing RevoScalePyを確認してください。
ストアドプロシージャTrainTipPredictionModelRxPyはStep 2: PowerShellを使用したSQL Serverへのデータインポートを通じてSQL Serverに定義されています。
-
Management Studioのオブジェクトエクスプローラで、[プログラミング]、[ストアドプロシージャ]の順に展開します。
-
TrainTipPredictionModelRxPyを右クリックし、[変更] を選択して新しいクエリウィンドウでTransact-SQLスクリプトを開きます。TrainTipPredictionModelRxPyDROP PROCEDURE IF EXISTS TrainTipPredictionModelRxPy; GO CREATE PROCEDURE [dbo].[TrainTipPredictionModelRxPy] (@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle # import pandas from revoscalepy.functions.RxLogit import rx_logit ## Create a logistic regression model using rx_logit function from revoscalepy package logitObj = rx_logit("tipped ~ passenger_count + trip_distance + trip_time_in_secs + direct_distance", data = InputDataSet); ## Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO- SELECTクエリはカスタムスカラ関数fnCalculateDistanceを使用して、乗車位置と降車位置の間の直接距離を計算します。クエリの結果はデフォルトのPython入力変数
InputDatasetに格納されます。 - Pythonスクリプトは、Machine Learning Servicesに含まれているrevoscalepyのLogisticRegression関数を呼び出して、ロジスティック回帰モデルを作成します。
- tippedを目的変数(label)に、passenger_count、trip_distance、trip_time_in_secs、およびdirect_distanceを説明変数(feature)としてモデルを作成します。
- Python変数
logitObjで示される訓練済みモデルはシリアライズされ出力パラメータとして返ります。この出力をnyc_taxi_modelsテーブルに登録することで、将来の予測に繰り返し使用することができます。
- SELECTクエリはカスタムスカラ関数fnCalculateDistanceを使用して、乗車位置と降車位置の間の直接距離を計算します。クエリの結果はデフォルトのPython入力変数
-
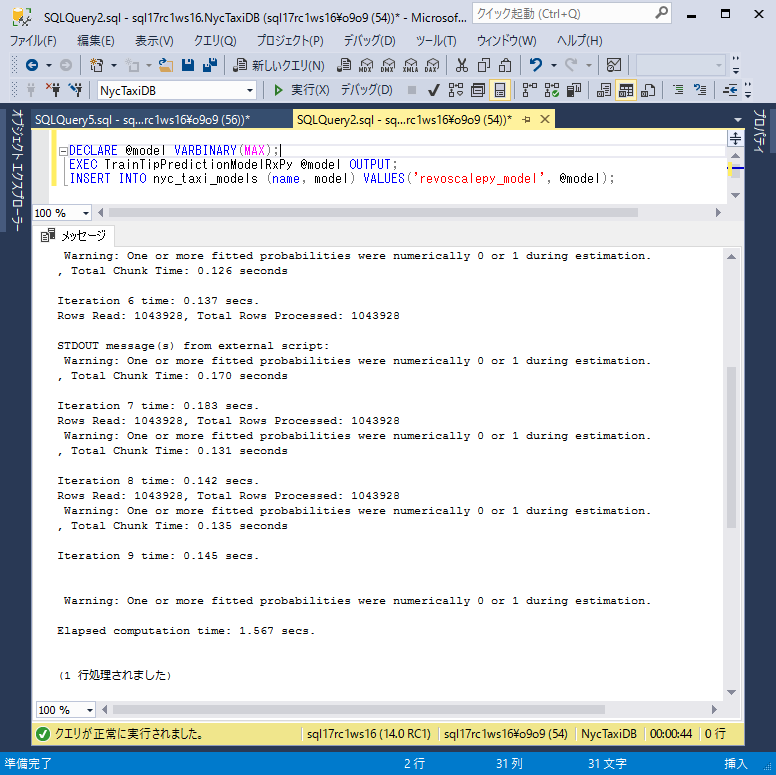
次のSQL文を実行して、トレーニングされたモデルをnyc_taxi_modelsテーブルに登録します。
T-SQLDECLARE @model VARBINARY(MAX); EXEC TrainTipPredictionModelRxPy @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('revoscalepy_model', @model);データ処理とモデルのフィッティングには数分かかります。Pythonのstdoutストリームにパイプされるメッセージは、Management Studioのメッセージウィンドウに表示されます。
-
nyc_taxi_modelsテーブルに新しいレコードが1つ追加され、シリアライズされたモデルが登録されていることを確認します。
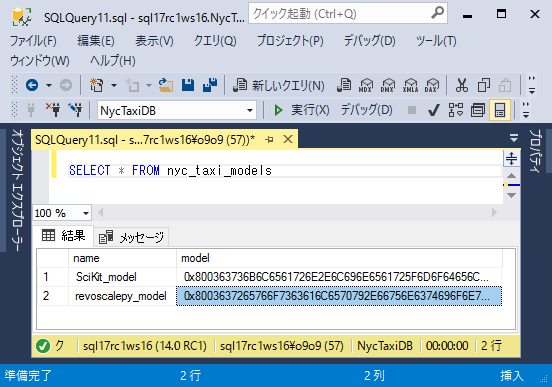
次のステップでは、訓練されたモデルを使用して予測を作成します。
リンク
次のステップ
前のステップ
チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
出典
Step 5: Train and save a model using T-SQL