チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
前のステップ
次のステップ
Step 2: PowerShellを使用したSQL Serverへのデータインポート
このステップでは、ダウンロードしたスクリプトRunSQL_SQL_Walkthrough.ps1を実行して、チュートリアルに必要なデータベースオブジェクトを作成とサンプルデータのインポートを行います。
オブジェクト作成とデータロード
ダウンロードしたファイル群の中のPowerShellスクリプトRunSQL_SQL_Walkthrough.ps1を実行し、チュートリアル環境を準備します。このスクリプトは次のアクションを実行します:
-
SQL Native ClientおよびSQLコマンドラインユーティリティがインストールされていない場合はインストールします。これらは、bcpを使用してデータをバルクロードするために必要です。
-
SQL Serverインスタンスにデータベースとテーブルを作成し、そこへデータをバルクロードします。
-
さらに複数の関数とストアドプロシージャを作成します。
スクリプトの実行
-
管理者としてPowerShellコマンドプロンプトを開き、次のコマンドを実行します。
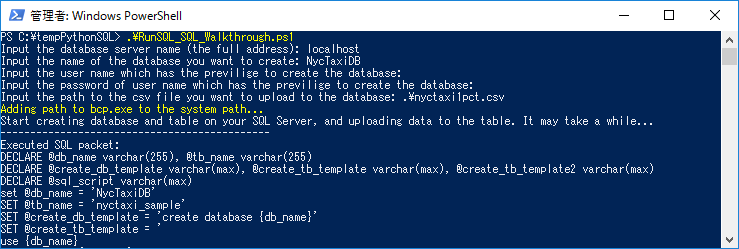
PowerShell.\RunSQL_SQL_Walkthrough.ps1次の情報を入力するよう求められます。
- Machine Learning Services(Python)がインストールされているサーバ名またはアドレス。
- 作成するデータベースの名前
- 対象のSQL Serverのユーザー名とパスワード。このユーザは、データベース、テーブル、ストアドプロシージャ、関数の作成権限、およびテーブルへのデータロード権限が必要です。ユーザー名とパスワードを省略した場合は現在のWindowsユーザによってログインします。
- ダウンロードしたファイル群の中のサンプルデータファイル
nyctaxi1pct.csvのパス。例えば、C:\tempPythonSQL\nyctaxi1pct.csvです。
-
上記手順の一環で指定したデータベース名とユーザー名をプレースホルダに置き換えるように、すべてのT-SQLスクリプトが変更されています。
-
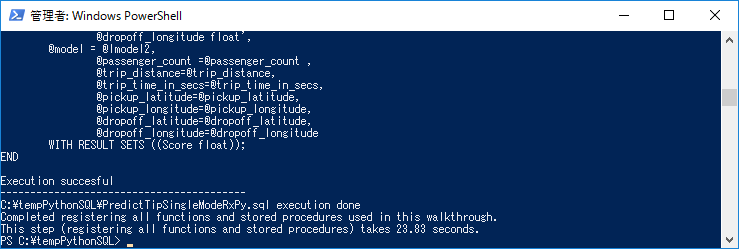
T-SQLスクリプトによって作成されるストアドプロシージャと関数がデータベース内に作成されていることを確認します。
T-SQLスクリプトファイル ストアドプロシージャ/関数 create-db-tb-upload-data.sql データベースと4つのテーブルを作成します。
テーブルnyctaxi_sample: メインとなるNYC Taxiデータセットが登録されます。ロードされるデータはNYC Taxiデータセットの1%のサンプルです。クラスタ化カラムストアインデックスの定義によってストレージ効率とクエリパフォーマンスを向上させています。
テーブルnyc_taxi_models: 訓練された高度な分析モデルが登録されます。
テーブルnyctaxi_sample_training:モデルのトレーニングに使用するデータセットが登録されます。
テーブルnyctaxi_sample_testing: モデルのテストに使用するデータセットが登録されます。fnCalculateDistance.sql 乗車位置と降車位置の間の直接距離を計算するスカラー値関数 fnCalculateDistanceを作成します。fnEngineerFeatures.sql モデルトレーニング用の特徴値セットを返すテーブル値関数 fnEngineerFeaturesを作成します。TrainingTestingSplit.sql nyctaxi_sampleテーブルのデータを、nyctaxi_sample_trainingとnyctaxi_sample_testingの2つに分割するプロシージャ TrainingTestingSplitを作成します。PredictTipSciKitPy.sql モデルを使用した予測のために、scikit-learnで作成した訓練されたモデルを呼び出すプロシージャ PredictTipSciKitPyを作成します。プロシージャは、入力パラメータとしてクエリを受け入れ、入力行に対するスコアを含む数値の列を戻します。PredictTipRxPy.sql モデルを使用した予測のために、RevoScalePyで作成した訓練されたモデルを呼び出すプロシージャ PredictTipRxPyを作成します。プロシージャは、入力パラメータとしてクエリを受け入れ、入力行に対するスコアを含む数値の列を戻します。PredictTipSingleModeSciKitPy.sql モデルを使用した予測のために、scikit-learnで作成した訓練されたモデルを呼び出すプロシージャ PredictTipSingleModeSciKitPyを作成します。このストアドプロシージャは新しい観測値を入力として、個々の特徴値はインラインパラメータとして受け取り、新しい観測値に対する予測値を返します。PredictTipSingleModeRxPy.sql モデルを使用した予測のために、scikit-learnで作成した訓練されたモデルを呼び出すプロシージャ PredictTipSingleModeRxPyを作成します。このストアドプロシージャは新しい観測値を入力として、個々の特徴値はインラインパラメータとして受け取り、新しい観測値に対する予測値を返します。SerializePlots.sql データ探索用のプロシージャ SerializePlotsを作成します。このストアドプロシージャは、Pythonを使用してグラフィックを作成し、グラフオブジェクトをシリアライズします。TrainTipPredictionModelSciKitPy.sql scikit-learnによるロジスティック回帰モデルを訓練するプロシージャ TrainTipPredictionModelSciKitPyを作成します。このモデルはランダムに選択された60%のデータを使用して訓練され、tipped値(チップをもらうか否か)を予測します。ストアドプロシージャの出力は訓練されたモデルであり、テーブルnyc_taxi_modelsに登録されます。TrainTipPredictionModelRxPy.sql RevoScalePyによるロジスティック回帰モデルを訓練するプロシージャ TrainTipPredictionModelRxPyを作成します。このモデルはランダムに選択された60%のデータを使用して訓練され、tipped値(チップをもらうか否か)を予測します。ストアドプロシージャの出力は訓練されたモデルであり、テーブルnyc_taxi_modelsに登録されます。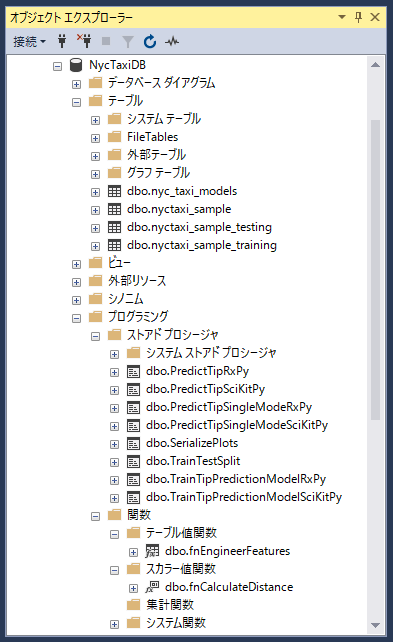
[!NOTE]
T-SQLスクリプトはデータベースオブジェクトを再作成しないため、すでに存在する場合にはデータが重複して登録されます。そのため、スクリプトを再実行する場合は事前に既存オブジェクトを削除してください。
重要:一部オブジェクトの再定義
上記の手順を実行後、以下のSQLを実行し一部のオブジェクトを再定義します。
SQL Server 2017 CTP から SQL Server 2017 RC にバージョンアップした際にRevoScalePyの仕様が変更されたため、その仕様変更に対応させることがこの再定義の主な理由です。
- TrainTipPredictionModelSciKitPy
- TrainTipPredictionModelRxPy
- PredictTipSciKitPy
- PredictTipRxPy
- PredictTipSingleModeSciKitPy
- PredictTipSingleModeRxPy
リンク
次のステップ
前のステップ
チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
出典
Step 2: Import Data to SQL Server using PowerShell