チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
前のステップ
Step 2: PowerShellを使用したSQL Serverへのデータインポート
次のステップ
Step 3: データの探索と可視化
データサイエンスソリューション開発には、通常、集中的なデータの探索とデータの可視化が含まれます。このステップでは、サンプルデータを探索しいくつかのプロットを生成します。さらに、Pythonでグラフィックスオブジェクトをシリアライズする方法、およびデシリアライズしてプロットを作成する方法を学習します。
[!NOTE]
このチュートリアルでは二項分類モデルのみを示します。回帰分類や多項分類などほかのモデルを構築することも可能です。
データの確認
元のデータセットにはタクシー識別子と運転記録が別々のファイルで提供されていますが、サンプルデータを使いやすくするために_medallion_、hack_license、_pickup_datetime_をキーにジョインしています。また使用するレコードは、元のレコード数の1%でサンプリングしています。サンプリングされたデータセットは1,703,957の行と23の列を持っています。
タクシー識別子
- medallion列はタクシーの一意なID番号を示します。
- hack_license列は運転手の匿名化された運転免許証番号を示します。
運転記録および運賃記録
-
各運転記録には、乗車と降車の場所と時間、および運転距離が含まれます。
-
各運賃記録には、支払タイプ、合計支払い額、チップ金額などの支払情報が含まれます。
-
最後の3つの列は、さまざまな機械学習タスクに使用できます。
- tip_amount列は連続した数値が含まれ、回帰分析のためのラベル列(目的変数)として使用できます。
- tipped列は yes / no 値のみがあり、二項分類のためのラベル列(目的変数)として使用できます。
- tip_class列は複数のクラスラベルがあり、多項分類のためのラベル列(目的変数)として使用できます。
-
ラベル列として使用される値はtip_amount列に基づいています。
列 ルール tipped If tip_amount > 0, tipped = 1, otherwise tipped = 0 tip_class Class 0: tip_amount = 0ドル
Class 1: tip_amount > 0ドル and tip_amount <= 5ドル
Class 2: tip_amount > 5ドル and tip_amount <= 10ドル
Class 3: tip_amount > 10ドル and tip_amount <= 20ドル
Class 4: tip_amount > 20ドル
T-SQL内のPythonでプロットを作成する
可視化はデータと異常値の分布を理解するために重要で、Pythonにはデータ可視化のための多くのパッケージが提供されています。matplotlibモジュールは、ヒストグラム、散布図、箱ひげ図、およびその他のデータ探索グラフを作成するための多くの機能を含みます。
このセクションでは、ストアドプロシージャを使用してプロットを操作する方法を学習します。ここではプロットをvarbinary型のデータとして扱っています。
プロットをvarbinaryデータ型として格納する
SQL Server 2017 Machine Learning Servicesに含まれるPythonライブラリのRevoScalePyパッケージは、RライブラリのRevoScaleRパッケージに相当します。この例ではrxHistogramを使用し、Transact-SQLクエリの結果データに基づいたヒストグラムをプロットします。利用を簡単にするためにPlotHistogramストアドプロシージャでラップします。
このストアドプロシージャはシリアライズされたPython描画オブジェクトをvarbinaryデータのストリームとして返します。バイナリデータは直接表示することはできませんが、クライアント上でPythonコードを使用してバイナリデータをデシリアライズし、その画像ファイルをクライアントコンピュータに保存します。
SerializePlotsストアドプロシージャを定義する
ストアドプロシージャSerializePlotsはStep 2: PowerShellを使用したSQL Serverへのデータインポートを通じてSQL Serverに定義されています。
-
Management Studioのオブジェクトエクスプローラで、[プログラミング]、[ストアドプロシージャ]の順に展開します。
-
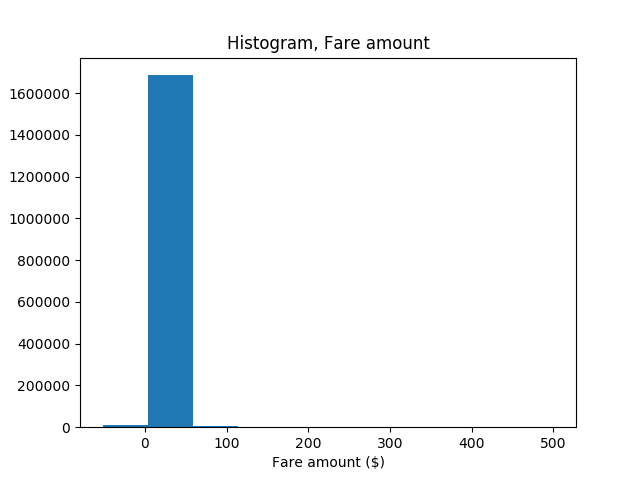
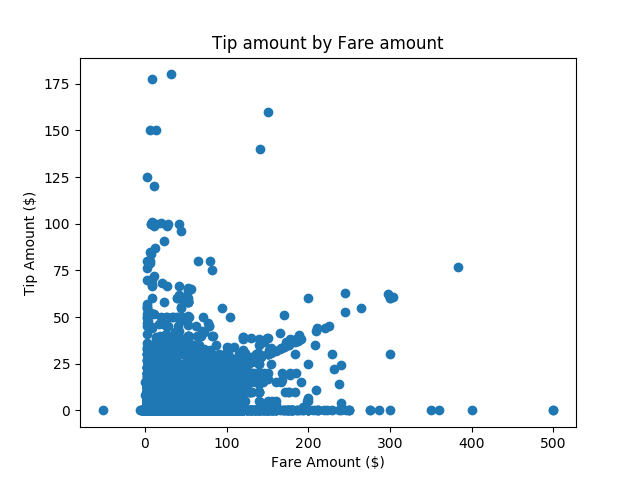
SerializePlotsを右クリックし、[変更] を選択して新しいクエリウィンドウでTransact-SQLスクリプトを開きます。SerializePlotsCREATE PROCEDURE [dbo].[SerializePlots] AS BEGIN SET NOCOUNT ON; DECLARE @query nvarchar(max) = N'SELECT cast(tipped as int) as tipped, tip_amount, fare_amount FROM [dbo].[nyctaxi_sample]' EXECUTE sp_execute_external_script @language = N'Python', @script = N' import matplotlib matplotlib.use("Agg") import matplotlib.pyplot as plt import pandas as pd import pickle fig_handle = plt.figure() plt.hist(InputDataSet.tipped) plt.xlabel("Tipped") plt.ylabel("Counts") plt.title("Histogram, Tipped") plot0 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns =["plot"]) plt.clf() plt.hist(InputDataSet.tip_amount) plt.xlabel("Tip amount ($)") plt.ylabel("Counts") plt.title("Histogram, Tip amount") plot1 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns =["plot"]) plt.clf() plt.hist(InputDataSet.fare_amount) plt.xlabel("Fare amount ($)") plt.ylabel("Counts") plt.title("Histogram, Fare amount") plot2 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns =["plot"]) plt.clf() plt.scatter( InputDataSet.fare_amount, InputDataSet.tip_amount) plt.xlabel("Fare Amount ($)") plt.ylabel("Tip Amount ($)") plt.title("Tip amount by Fare amount") plot3 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns =["plot"]) plt.clf() OutputDataSet = plot0.append(plot1, ignore_index=True).append(plot2, ignore_index=True).append(plot3, ignore_index=True) ', @input_data_1 = @query WITH RESULT SETS ((plot varbinary(max))) END GO- 変数
@queryは、Pythonコードブロックへのインプット@input_data_1として渡されるクエリテキストを定義しています。 -
matplotlibライブラリの
figureによってヒストグラムと散布図を作成し、これらのオブジェクトをpickleライブラリを使用してシリアライズしています。 - Python描画オブジェクトはアウトプットのためにpandasデータフレームへシリアライズされます。
- 変数
varbinaryデータを画像ファイルとして出力する
-
Management Studioで以下のクエリを実行します。
EXEC [dbo].[SerializePlots]
-
ダウンロードしたファイル群の中のPythonスクリプト
DeserializeSavePlots.py内の接続文字列を環境に合わせて変更した後、実行します。SQL Server 認証の場合
DeserializeSavePlotsimport pyodbc import pickle import os cnxn = pyodbc.connect('DRIVER={SQL Server};SERVER={SERVER_NAME};DATABASE={DB_NAME};UID={USER_NAME};PWD={PASSOWRD}') cursor = cnxn.cursor() cursor.execute("EXECUTE [dbo].[SerializePlots]") tables = cursor.fetchall() for i in range(0, len(tables)): fig = pickle.loads(tables[i][0]) fig.savefig(str(i)+'.png') print("The plots are saved in directory: ",os.getcwd())Windows認証の場合
DeserializeSavePlots.pyimport pyodbc import pickle import os cnxn = pyodbc.connect('DRIVER={SQL Server};SERVER={SERVER_NAME};DATABASE={DB_NAME};Trusted_Connection=yes;') cursor = cnxn.cursor() cursor.execute("EXECUTE [dbo].[SerializePlots]") tables = cursor.fetchall() for i in range(0, len(tables)): fig = pickle.loads(tables[i][0]) fig.savefig(str(i)+'.png') print("The plots are saved in directory: ",os.getcwd())[!NOTE]
Pythonのランタイムのバージョンをサーバとクライアントで合わせてください。またクライアントで使用するmatplotlibなどPythonライブラリのバージョンはサーバと合わせるもしくは上位のバージョンとしてください。 -
接続が成功すると、以下の結果が表示されます。
-
4つのファイルがPythonの作業ディレクトリに作成されます。
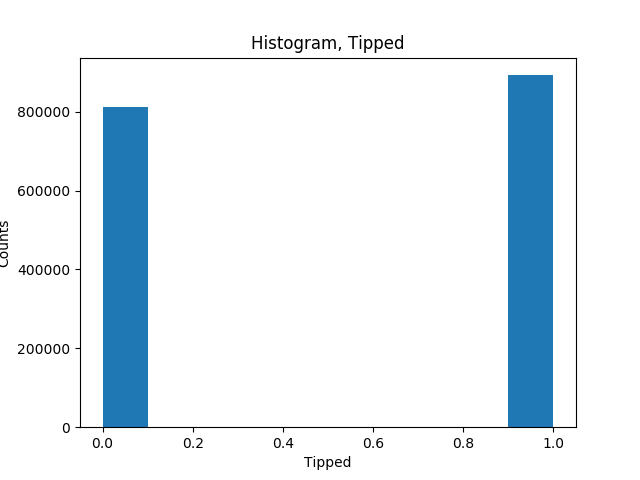
チップが得られた数と得られなかった数を示します。
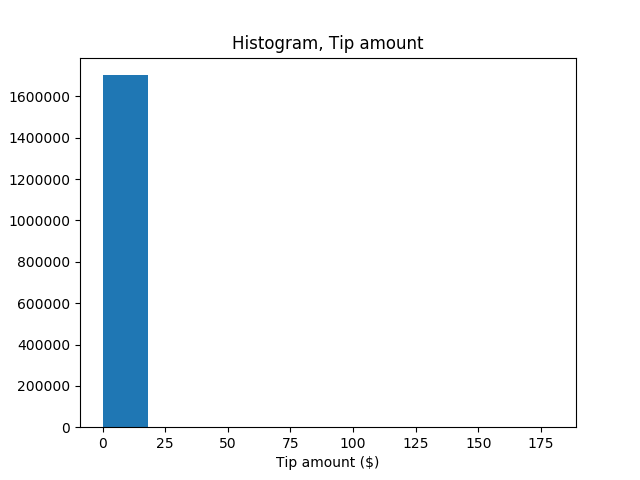
チップ金額の分布を示します。
運賃の分布を示します。
x軸上に運賃、y軸上にチップ金額とした散布図です。
リンク
次のステップ
前のステップ
Step 2: PowerShellを使用したSQL Serverへのデータインポート
チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
出典
Step 3: Explore and Visualize the Data