チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
前のステップ
Step 5: T-SQLを使用したモデルのトレーニングと保存
Step 6: モデルの利用
このステップでは、前の手順で訓練したモデルを利用する方法を学びます。ここでの"利用"とは、「スコアリングのためにモデルを本番環境に展開する」ことを意味しています。これはPythonコードがストアドプロシージャに含まれているために簡単に展開できます。アプリケーションから新しい観測値の予測を行うためにはストアドプロシージャを呼び出すだけです。
ストアドプロシージャからPythonモデルを呼び出すには、次の2つの方法があります。
- バッチスコアリングモード:複数の行のデータを提供するためにSELECTクエリを使用します。ストアドプロシージャは入力に対応する観測値のテーブルを戻します
- 個々のスコアリングモード:個々のパラメータ値のセットを入力として渡します。ストアドプロシージャは単一のレコードまたは値を返します。
scikit-learnモデルを使用したスコアリング
ストアドプロシージャPredictTipSciKitPyは、scikit-learnモデルを使用します。
ストアドプロシージャPredictTipSciKitPyはStep 2: PowerShellを使用したSQL Serverへのデータインポートを通じてSQL Serverに定義されています。
-
Management Studioのオブジェクトエクスプローラで、[プログラミング]、[ストアドプロシージャ]の順に展開します。
-
PredictTipSciKitPyを右クリックし、[変更] を選択して新しいクエリウィンドウでTransact-SQLスクリプトを開きます。PredictTipSciKitPyDROP PROCEDURE IF EXISTS PredictTipSciKitPy; GO CREATE PROCEDURE [dbo].[PredictTipSciKitPy] (@model varchar(50), @inquery nvarchar(max)) AS BEGIN DECLARE @lmodel2 varbinary(max) = (select model from nyc_taxi_models where name = @model); EXEC sp_execute_external_script @language = N'Python', @script = N' import pickle import numpy # import pandas from sklearn import metrics mod = pickle.loads(lmodel2) X = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] y = numpy.ravel(InputDataSet[["tipped"]]) prob_array = mod.predict_proba(X) prob_list = [item[1] for item in prob_array] prob_array = numpy.asarray(prob_list) fpr, tpr, thresholds = metrics.roc_curve(y, prob_array) auc_result = metrics.auc(fpr, tpr) print("AUC on testing data is:", auc_result) OutputDataSet = pandas.DataFrame(data=prob_list, columns=["predictions"]) ', @input_data_1 = @inquery, @input_data_1_name = N'InputDataSet', @params = N'@lmodel2 varbinary(max)', @lmodel2 = @lmodel2 WITH RESULT SETS ((Score float)); END GO- 使用するモデル名をストアドプロシージャの入力パラメータで指定します。
- 指定されたモデル名を元にnyc_taxi_modelsテーブルからシリアライズされたモデルを取り出します。
- シリアライズされたモデルはPython変数
modに格納します。 - スコアリングした新しいケースは
@input_data_1で指定されたTransact-SQLクエリから取得します。このクエリ結果はデフォルトのデータフレームInputDat aSetに保存されます。 - このデータフレームはscikit-learnモデルを使用して作成されたロジスティック回帰モデル
modの関数predict_probaに渡されます。 - 関数
predict_probaは任意の額のチップを受け取る確率を示すfloat値を戻します。 - さらに、精度メトリック
AUC(area under curve)を計算します。AUCなどの精度メトリックは説明変数に加えて目的変数(すなわちtipped列)も指定した場合にのみ生成されます。予測には目的変数(変数Y)を必要としませんが、精度メトリックの計算には必要です。したがって、スコアリングするデータに目的変数がない場合は、ソースコードからAUC計算ブロックを削除し、単純に説明変数(変数X)によってチップを受け取る確率を返すようにストアドプロシージャを変更します。
revoscalepyモデルを使用したスコアリング
ストアドプロシージャPredictTipRxPyは、revoscalepyライブラリを使用して作成されたモデルを使用します。これはプロシージャPredictTipSciKitPyとほぼ同じように機能しますが、revoscalepy関数にはいくつかの変更が加えられています。
ストアドプロシージャPredictTipRxPyはStep 2: PowerShellを使用したSQL Serverへのデータインポートを通じてSQL Serverに定義されています。
-
Management Studioのオブジェクトエクスプローラで、[プログラミング]、[ストアドプロシージャ]の順に展開します。
-
PredictTipRxPyを右クリックし、[変更] を選択して新しいクエリウィンドウでTransact-SQLスクリプトを開きます。PredictTipRxPyDROP PROCEDURE IF EXISTS PredictTipRxPy; GO CREATE PROCEDURE [dbo].[PredictTipRxPy] (@model varchar(50), @inquery nvarchar(max)) AS BEGIN DECLARE @lmodel2 varbinary(max) = (select model from nyc_taxi_models where name = @model); EXEC sp_execute_external_script @language = N'Python', @script = N' import pickle import numpy # import pandas from sklearn import metrics from revoscalepy.functions.RxPredict import rx_predict mod = pickle.loads(lmodel2) X = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] y = numpy.ravel(InputDataSet[["tipped"]]) prob_array = rx_predict(mod, X) prob_list = prob_array["tipped_Pred"].values prob_array = numpy.asarray(prob_list) fpr, tpr, thresholds = metrics.roc_curve(y, prob_array) auc_result = metrics.auc(fpr, tpr) print("AUC on testing data is:", auc_result) OutputDataSet = pandas.DataFrame(data=prob_list, columns=["predictions"]) ', @input_data_1 = @inquery, @input_data_1_name = N'InputDataSet', @params = N'@lmodel2 varbinary(max)', @lmodel2 = @lmodel2 WITH RESULT SETS ((Score float)); END GO
バッチスコアリングの実行
ストアドプロシージャPredictTipSciKitPyおよびPredictTipRxPyには、2つの入力パラメータが必要です。
- スコアリング対象とするデータを抽出するクエリ
- スコアリングに使用する訓練済みモデルの識別子
このセクションでは、これらの引数をストアドプロシージャに渡して、スコアリングに使用するモデルとデータの両方を簡単に変更する方法を学習します。
-
入力データを定義し、次のようにスコアリングのためにストアドプロシージャを呼び出します。この例では、スコアリングにストアドプロシージャ
PredictTipSciKitPyを使用し、モデルの名前とクエリ文字列を渡しますT-SQLDECLARE @query_string nvarchar(max) -- Specify input query SET @query_string=' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_testing' EXEC [dbo].[PredictTipSciKitPy] 'SciKit_model', @query_string;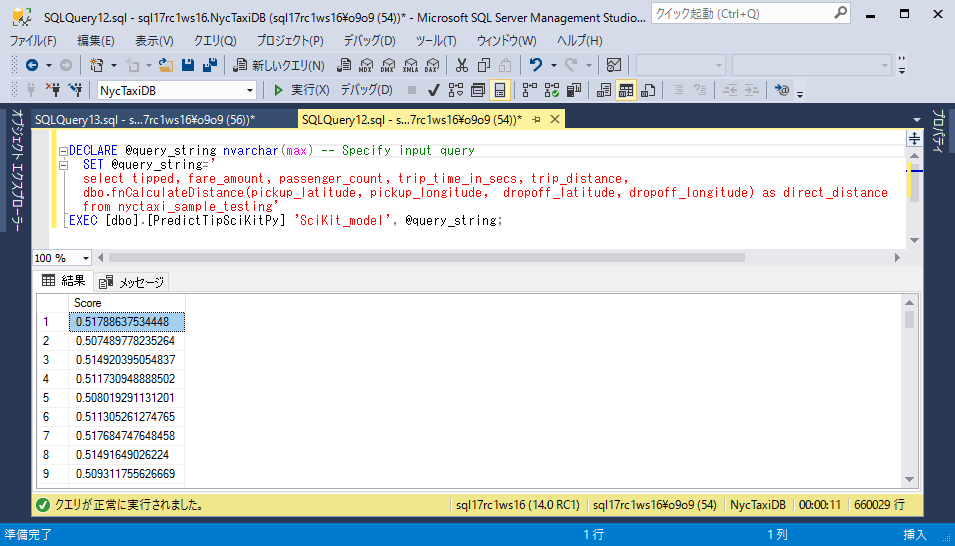
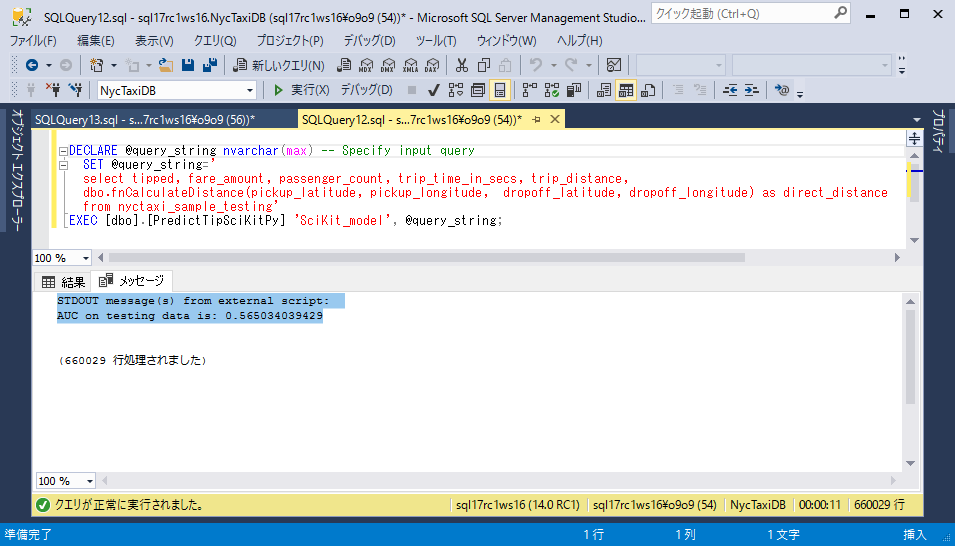
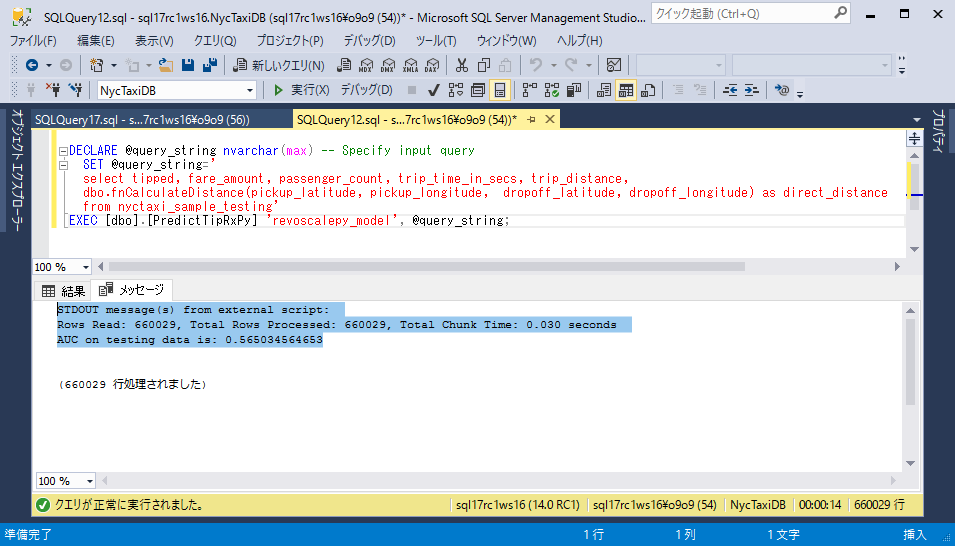
ストアドプロシージャは、入力クエリの一部として渡された各運転記録に対してのチップを受け取る確率の予測値を返します。予測値はManagement Studioの結果ペインに表示されます。またメッセージペインには精度メトリック
AUC(曲線下面積)が出力されます。 -
revoscalepyモデルをスコアリングに使用するには、ストアドプロシージャPredictTipRxPyを呼び出します。
DECLARE @query_string nvarchar(max) -- Specify input query SET @query_string=' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_testing' EXEC [dbo].[PredictTipRxPy] 'revoscalepy_model', @query_string;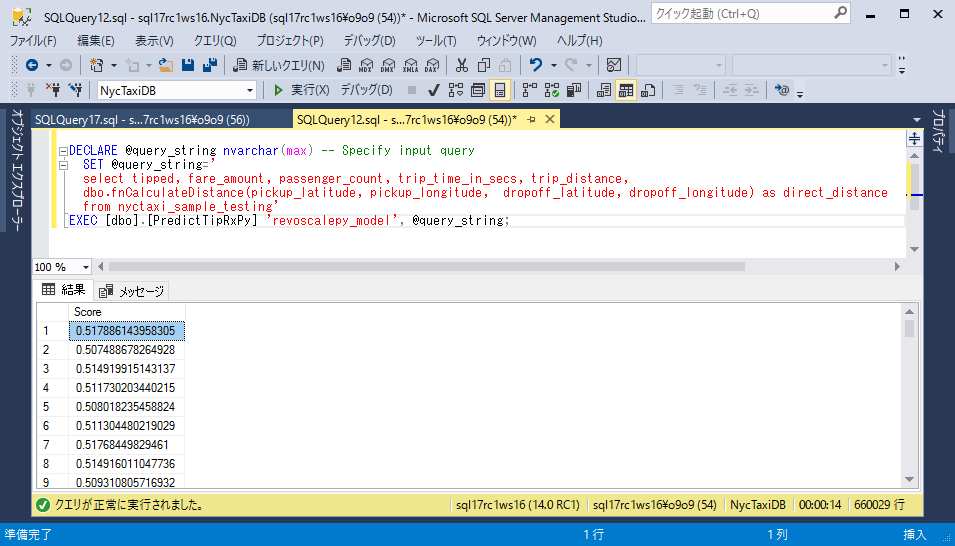
個々のスコアリングの実行
バッチスコアリングの代わりに、単一のケースを渡し、その値に基づいた単一の結果を得たいケースもあります。たとえば、Excelワークシート、Webアプリケーション、またはReporting Servicesレポートにおいてユーザからの入力に基づいてストアドプロシージャを呼び出すよう構成します。
このセクションでは、ストアドプロシージャPredictTipSingleModeSciKitPyとPredictTipSingleModeRxPyを呼び出して単一の予測を作成する方法を学習します。
ストアドプロシージャPredictTipSingleModeSciKitPyとPredictTipSingleModeRxPyはStep 2: PowerShellを使用したSQL Serverへのデータインポートを通じてSQL Serverに定義されています。
-
Management Studioのオブジェクトエクスプローラで、[プログラミング]、[ストアドプロシージャ]の順に展開します。
-
PredictTipSingleModeSciKitPyもしくはPredictTipSingleModeRxPyを右クリックし、[変更] を選択して新しいクエリウィンドウでTransact-SQLスクリプトを開きます。これらのストアドプロシージャは、scikit-learnおよびrevoscalepyモデルを使用し、次のようにスコアリングを実行します。
- モデルの名前と複数の単一値が入力として提供されます。これらの入力には、客数、運転距離などが含まれます。
- テーブル値関数
fnEngineerFeaturesは緯度と経度を入力で受け取り直接距離に変換します。 - 外部アプリケーションからストアドプロシージャを呼び出す場合は、入力データがPythonモデルの必要な入力機能と一致することを確認してください。これには、入力データをPythonデータ型にキャストすることやデータ型、データ長を検証することが含まれます。
- ストアドプロシージャは、格納されているPythonモデルに基づいてスコアを作成します。
以下はscikit-learnモデルを使用してスコアリングを実行するストアドプロシージャ
PredictTipSingleModeSciKitPyです。PredictTipSingleModeSciKitPyCREATE PROCEDURE [dbo].[PredictTipSingleModeSciKitPy] (@model varchar(50), @passenger_count int = 0, @trip_distance float = 0, @trip_time_in_secs int = 0, @pickup_latitude float = 0, @pickup_longitude float = 0, @dropoff_latitude float = 0, @dropoff_longitude float = 0) AS BEGIN DECLARE @inquery nvarchar(max) = N' SELECT * FROM [dbo].[fnEngineerFeatures]( @passenger_count, @trip_distance, @trip_time_in_secs, @pickup_latitude, @pickup_longitude, @dropoff_latitude, @dropoff_longitude) ' DECLARE @lmodel2 varbinary(max) = (select model from nyc_taxi_models where name = @model); EXEC sp_execute_external_script @language = N'Python', @script = N' import pickle import numpy # import pandas # Load model and unserialize mod = pickle.loads(model) # Get features for scoring from input data X = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] # Score data to get tip prediction probability as a list (of float) prob = [mod.predict_proba(X)[0][1]] # Create output data frame OutputDataSet = pandas.DataFrame(data=prob, columns=["predictions"]) ', @input_data_1 = @inquery, @params = N'@model varbinary(max),@passenger_count int,@trip_distance float, @trip_time_in_secs int , @pickup_latitude float , @pickup_longitude float , @dropoff_latitude float , @dropoff_longitude float', @model = @lmodel2, @passenger_count =@passenger_count , @trip_distance=@trip_distance, @trip_time_in_secs=@trip_time_in_secs, @pickup_latitude=@pickup_latitude, @pickup_longitude=@pickup_longitude, @dropoff_latitude=@dropoff_latitude, @dropoff_longitude=@dropoff_longitude WITH RESULT SETS ((Score float)); END GO以下はrevoscalepyモデルを使用してスコアリングを実行するストアドプロシージャ
PredictTipSingleModeRxPyです。CREATE PROCEDURE [dbo].[PredictTipSingleModeRxPy] (@model varchar(50), @passenger_count int = 0, @trip_distance float = 0, @trip_time_in_secs int = 0, @pickup_latitude float = 0, @pickup_longitude float = 0, @dropoff_latitude float = 0, @dropoff_longitude float = 0) AS BEGIN DECLARE @inquery nvarchar(max) = N' SELECT * FROM [dbo].[fnEngineerFeatures]( @passenger_count, @trip_distance, @trip_time_in_secs, @pickup_latitude, @pickup_longitude, @dropoff_latitude, @dropoff_longitude) ' DECLARE @lmodel2 varbinary(max) = (select model from nyc_taxi_models where name = @model); EXEC sp_execute_external_script @language = N'Python', @script = N' import pickle import numpy # import pandas from revoscalepy.functions.RxPredict import rx_predict # Load model and unserialize mod = pickle.loads(model) # Get features for scoring from input data x = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] # Score data to get tip prediction probability as a list (of float) prob_array = rx_predict(mod, x) prob_list = prob_array["tipped_Pred"].values # Create output data frame OutputDataSet = pandas.DataFrame(data=prob_list, columns=["predictions"]) ', @input_data_1 = @inquery, @params = N'@model varbinary(max),@passenger_count int,@trip_distance float, @trip_time_in_secs int , @pickup_latitude float , @pickup_longitude float , @dropoff_latitude float , @dropoff_longitude float', @model = @lmodel2, @passenger_count =@passenger_count , @trip_distance=@trip_distance, @trip_time_in_secs=@trip_time_in_secs, @pickup_latitude=@pickup_latitude, @pickup_longitude=@pickup_longitude, @dropoff_latitude=@dropoff_latitude, @dropoff_longitude=@dropoff_longitude WITH RESULT SETS ((Score float)); END GO -
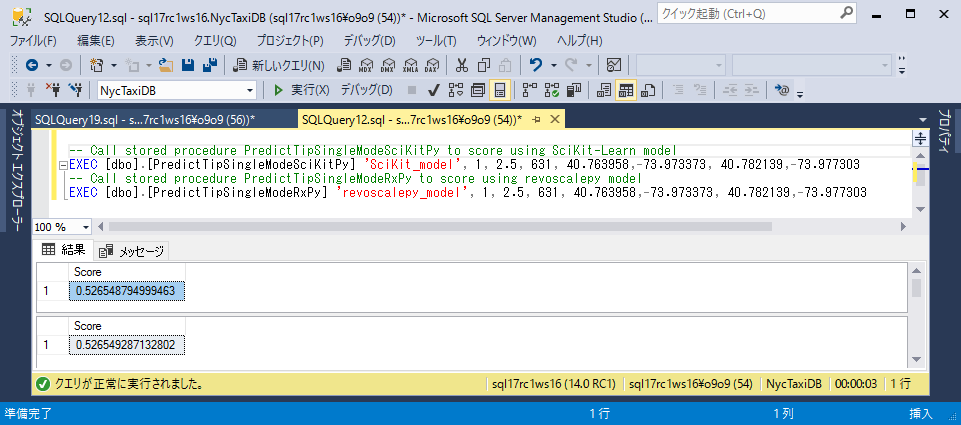
Management Studioで新しいクエリウィンドウを開き、説明変数列を入力してストアドプロシージャを呼び出します。
-- Call stored procedure PredictTipSingleModeSciKitPy to score using SciKit-Learn model EXEC [dbo].[PredictTipSingleModeSciKitPy] 'SciKit_model', 1, 2.5, 631, 40.763958,-73.973373, 40.782139,-73.977303 -- Call stored procedure PredictTipSingleModeRxPy to score using revoscalepy model EXEC [dbo].[PredictTipSingleModeRxPy] 'revoscalepy_model', 1, 2.5, 631, 40.763958,-73.973373, 40.782139,-73.9773037つの説明変数値は以下の順序です。
- passenger_count
- trip_distance
- trip_time_in_secs
- pickup_latitude
- pickup_longitude
- dropoff_latitude
- dropoff_longitude
結果として上記のパラメータを有する運転においてチップが支払われる確率が返されます。
まとめ
このチュートリアルでは、ストアドプロシージャに埋め込まれたPythonコードを操作する方法を学びました。Transact-SQLとの統合により、予測のためのPythonモデルのデプロイメントやエンタープライズデータワークフローの一部としてのモデル再トレーニングの組み込みがさらに簡単になることを確認しました。
リンク
前のステップ
Step 5: T-SQLを使用したモデルのトレーニングと保存
チュートリアルのはじめから
SQL開発者のための In-Database Python 分析
出典
Step 6: Operationalize the Model