追記 (2015/10/06)
Amazon Linux 2015.09で、NVIDIAドライバのセットアップに失敗するようになってしまいました。詳細は以下をご覧ください。
Chainer on EC2スポットインスタンスの環境を、AWS Lambdaで用意する
http://qiita.com/pyr_revs/items/bf483b96cca6b01a9110
はじめに
Chainer。触ってみるに当たって、どうせならGPU使ってみたいと思いまして。
EC2のg2.2xlargeでの環境構築について調査していたところ、AWS Marketplaceにある、NVIDIAの提供しているイメージを使えば、ドライバとCUDAのインストールはせずに済むよって情報を得たので、それを使ってスポットインスタンスを立てようと思ったのですが、
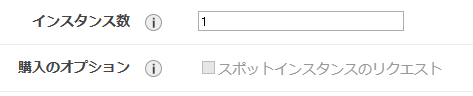
なんかDisableされてますね。スポットインスタンスでは使えないみたいです。
ということで、イメージ使うのは諦めて、手動で環境構築をしたので、そのメモ書きを残しておきたいと思います。
Request Spot Instance
GPUインスタンスはバージニア北部と他のリージョンで価格差があるので、まあバージニア北部で立てるのが吉かと。
OSはAmazon Linux AMIの最新で、後は通常通り、と行きたいところですが、一点。ストレージの設定。tmpの容量の関係上、ルートのサイズを8 -> 16に。あと、インスタンスストアのアタッチもやっちゃいましょう。

Install GPU Drivers
主に以下のブログを参考にさせて頂いたのですが、こちらでは基本的にサイレントでインストールしていく方針でやっていきたいなと(スポットインスタンス使う前提なので、毎度cleanからのインストールをしなければいけない、と考えるとね)。
ディープラーニングフレームワークChainerをEC2のGPUインスタンスで動かす g2.2xlarge instance
RunAs root
いろいろ面倒なので、rootで作業します。
sudo su -
Install updates and dev tools
アップデート、開発ツール群、kernel-develをインストール。
yum update -y
yum groupinstall -y "Development tools"
yum install -y kernel-devel-`uname -r`
Install NVIDIA Driver and CUDA Toolkit
CUDAのインストーラから、NVIDIA GPU ドライバとCUDA ToolkitをExtractして、個別にインストール。
wget -q http://developer.download.nvidia.com/compute/cuda/7_0/Prod/local_installers/cuda_7.0.28_linux.run
chmod 755 cuda_7.0.28_linux.run
./cuda_7.0.28_linux.run -extract=/root
./NVIDIA-Linux-x86_64-346.46.run -s
./cuda-linux64-rel-7.0.28-19326674.run -noprompt
動作確認。
nvidia-smi -q | head
==============NVSMI LOG==============
Timestamp : Wed Jul 15 17:15:18 2015
Driver Version : 346.46
Attached GPUs : 1
GPU 0000:00:03.0
Product Name : GRID K520
Product Brand : Grid
どうもCUDAインストーラのoption各種、いろいろ設定はあるものの、怪しい動きをしてくれまして。。。silentでやろうとすると何かが引っかかるケースがちらほら。特にサンプルまわり。今日のところは、一旦extractしてから実行というのが、一番すっきり動くような感じだったのでそうしてます。
ちなみに、NVIDIA GPUドライバについてはもっと新しいバージョンも出てるですが、それ使うと環境構築終わってec2-userに戻ったところでnvidia-smiが動かなくなりました。
[追記]
Githubのpfnet/chainer-testにあるDockerファイルを見てみると、同じようにExtractしてドライバを-s、Toolkitを-nopromptでやってるみたいですね。アップデート等々はそちらを追いかけた方が早いかもです。
https://github.com/pfnet/chainer-test/blob/master/Dockerfile.ubuntu14_cuda_cudnn
CUDAのバージョンは6.5使ってるみたいですが、まあ動いてるんで7.0でもいいかなってところで。
Set PATH for root
CUDAのインストール後、PATHを通せとメッセージが出るので、とりあえず仮に通しちゃいます。これはPyCUDAのセットアップで必要です。
export CUDA_ROOT=/usr/local/cuda-7.0
export LD_LIBRARY_PATH=/usr/local/cuda-7.0/lib64
export PATH=$PATH:$CUDA_ROOT/bin
Install Python dependencies and Chainer
chainerのcuda_deps/setup.pyに書いてある依存関係を手動で入れちゃいます。
pip install numpy
pip install pycuda
pip install Mako
pip install scikit-cuda==0.5.0
pip install six
ついでにChainerもさくっとpipで。
pip install chainer
Logout root
以上で環境構築は終了なので、ec2-userに戻ります。
exit
環境構築をまとめて
いちいちstep by stepでやるのは面倒なので、まとめて流すとすると、こんな感じになりますね。これ、今日の時点では動いてますが、依存関係は生き物なので、エラーが出たら適宜アレンジしてください。
sudo su -
yum update -y
yum groupinstall -y "Development tools"
yum install -y kernel-devel-`uname -r`
wget -q http://developer.download.nvidia.com/compute/cuda/7_0/Prod/local_installers/cuda_7.0.28_linux.run
chmod 755 cuda_7.0.28_linux.run
./cuda_7.0.28_linux.run -extract=/root
./NVIDIA-Linux-x86_64-346.46.run -s
nvidia-smi -q | head
./cuda-linux64-rel-7.0.28-19326674.run -noprompt
nvidia-smi -q | head
export CUDA_ROOT=/usr/local/cuda-7.0
export LD_LIBRARY_PATH=/usr/local/cuda-7.0/lib64
export PATH=$PATH:$CUDA_ROOT/bin
pip install numpy
pip install pycuda
pip install Mako
pip install scikit-cuda==0.5.0
pip install six
pip install chainer
nvidia-smi -q | head
Run Chainer Examples with GPU
GPU Driver health check
ec2-userでも念のため確認。
nvidia-smi
Set PATH for ec2-user
exportしたPATHは、rootからexitした時点で消えるので、もう一度ec2-userでも。
export CUDA_ROOT=/usr/local/cuda-7.0
export LD_LIBRARY_PATH=/usr/local/cuda-7.0/lib64
export PATH=$PATH:$CUDA_ROOT/bin
当然ながらこのPATHの設定はログアウトすると消えるので、ログインするたびに打ち込むか、.bashrcに書いとく必要があります。
Get Chainer examples and Run
Chainer本体に付属のexampleが、GPUで動くかどうか実験。基本のmnistに、オプション--gpu=0を付けて。
git clone https://github.com/pfnet/chainer
cd chainer/examples/mnist
python train_mnist.py --gpu=0
別窓でGPUの状況をwatchするなど。
watch -n 5 -d nvidia-smi
動いているのが確認できるかと思います。デフォルトだとGPUの使用率が40%あたりを行き来。n_unitやbatchsizeを上げるとGPU使用率は上がるんで、適宜お試しあれ。
Chainer with cuDNN
cuDNNのインストール
上記、動くは動いているので必須ではない、というかソースコード見ると無ければ無いなりに動くようになっているようなのですが、せっかくなのでcuDNNを追加でインストールしていきます。
cuDNNのダウンロードには、「CUDA Registered Developers」の登録が必要です。
公式のcuDNNのページから、register。
https://developer.nvidia.com/cudnn
しかし、それですぐにダウンロードできるようになるわけではなく、しばらく後にApproval的なメールが来てからになります。
メールが来たら、「cuDNN v2 Library for Linux」をダウンロード。ファイル名「cudnn-6.5-linux-x64-v2.tgz」となっていますが、「for CUDA 6.5 and later」となっているのでCUDA7.0でも動くはず。
これ、毎度NVIDIAからダウンロードするのは面倒なので、s3にuploadして、GPUインスタンスに送り込んでいきます。
export AWS_ACCESS_KEY_ID=MY_KEY
export AWS_SECRET_ACCESS_KEY=MY_SEC_KEY
aws s3 cp s3://mybucket/cuda/cudnn-6.5-linux-x64-v2.tgz ./
解凍して、
tar zxvf cudnn-6.5-linux-x64-v2.tgz
中身をcudaのlibがあるところにコピーして終了です
cd cudnn-6.5-linux-x64-v2
sudo cp lib* /usr/local/cuda/lib64/
sudo cp cudnn.h /usr/local/cuda/include/
参考:
CUDAメモ: cuDNN のダウンロード方法
github - BVLC/caffe: Install Caffe on AWS from scratch
cuDNNの動作確認
cuDNNがChainerで認識されてるかどうかは、以下のようにすれば確認できますね。
from chainer import cudnn
print "cudnn:" + str(cudnn.available)
有る無しでどうなるのかは、正直まだわかってないところですが。。。
Appendix: Calculate FLOPS with nbody benchmark
Chainerとは関係ないですが、g2.2xlargeの実力が見たいということで、CUDAのサンプルにあるベンチマークを動かしてみます。以下のブログを参考にさせてもらいました。
以下、ec2-userで。
Install dependencies
X.Orgまわりの追加インストールが必要っぽいので、いれちゃいます。
sudo yum install -y libGLU-devel
sudo yum install -y libX11-devel
sudo yum install -y libXi-devel
sudo yum install -y libXmu-devel
sudo yum install -y freeglut-devel
Install Samples from CUDA installer
CUDAサンプルはサイレントで入れられなかった(途中で微妙に止まる)ので、対話式に入れていきます。
wget -q http://developer.download.nvidia.com/compute/cuda/7_0/Prod/local_installers/cuda_7.0.28_linux.run
chmod 755 cuda_7.0.28_linux.run
./cuda_7.0.28_linux.run
EULAがmoreで出てくるので最後まで読む or qで飛ばすと、対話式インストールが始まります。Sampleだけを入れる設定で以下のように。
Do you accept the previously read EULA? (accept/decline/quit) accept
You are attempting to install on an unsupported configuration. Do you wish to continue? ((y)es/(n)o) [ default is no ]: yes
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 346.46? ((y)es/(n)o/(q)uit): n
Do you want to install the OpenGL libraries? ((y)es/(n)o/(q)uit) [ default is yes ]: n
Install the CUDA Toolkit? ((y)es/(n)o/(q)uit): n
Install the CUDA Samples? ((y)es/(n)o/(q)uit): yes
Enter Toolkit Location [ default is /usr/local/cuda-7.0 ]: (enter)
Enter Samples Location [ default is /home/ec2-user ]: (enter)
Run nbody benchmark
サンプル内のフォルダ、nbodyに移動
cd NVIDIA_CUDA-7.0_Samples/5_Simulations/nbody
普通にmakeしたいところなんですが、libXなんちゃらが見当たらないとか出てダメ。GLPATH=/usr/lib64を頭につけてmakeしてやると、上手く行くようです。
GLPATH=/usr/lib64 make
makeが正常終了したら、binのあるフォルダに移動
cd ../../bin/x86_64/linux/release
実行。-numbodiesの値によって、実行時間と結果は変わってきますが。
./nbody -benchmark -numdevice=0 -numbodies=25600
number of bodies = 25600
25600 bodies, total time for 10 iterations: 149.265 ms
= 43.906 billion interactions per second
= 878.115 single-precision GFLOP/s at 20 flops per interaction
もういっちょ。
./nbody -benchmark -numdevice=0 -numbodies=256000
number of bodies = 256000
256000 bodies, total time for 10 iterations: 12137.070 ms
= 53.997 billion interactions per second
= 1079.931 single-precision GFLOP/s at 20 flops per interaction
1000GFLOP/s = 単精度1TFLOPS出てるということで、環境構築としては問題なさそうですね。
比較対象としてはアレですが、H2O.aiでc4.8xlarge(36core)×3台 = 128 GFlopsの時と比べると。。。はい。