以前、sparkling-waterをちょろちょろと動かしてたんですが、Version上がったり諸々でいろいろとついていくのが面倒な感じでした。一方、h2oの本体であるところのh2o.jarを使えば、比較的楽にクラスタまで立ちそう。ということで、以下を参考に、AWSのEC2上で、h2o.aiなクラスタを立ててみました。
EC2のインスタンスを起動、の前にセキュリティグループを作っておく
インスタンスを起動するときに注意が必要なのはセキュリティグループ。クラスタとして動かすには、同じセキュリティグループに入れて、セキュリティグループ内での通信を可能にしてやる必要があります。
ということで、先にセキュリティグループを作っておきます。
EC2のメニューからセキュリティグループ->作成と進んで、「名前:h2o-cluster・その他デフォルト」のままでセキュリティグループを作成。
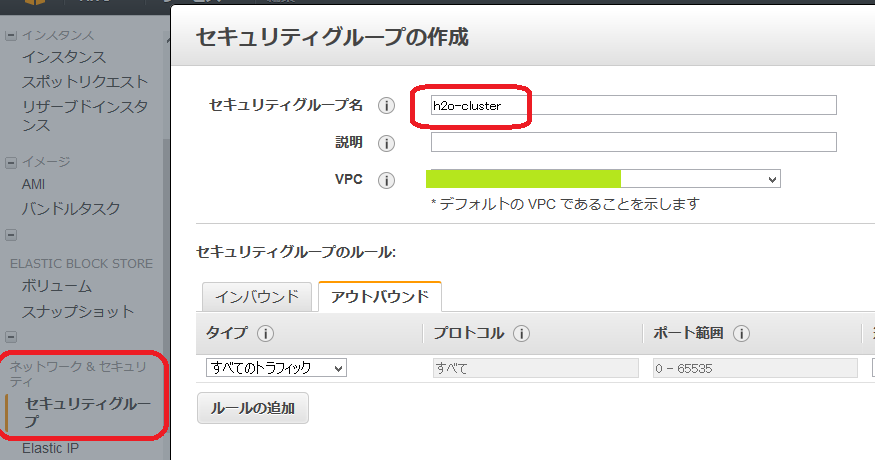
インバウンドルールの編集で、「タイプ: すべてのトラフィック、送信元: カスタムIP、送信元のValue: h2o-clusterのセキュリティグループID(sg-xxxxxxx)」、となるルールを追加。
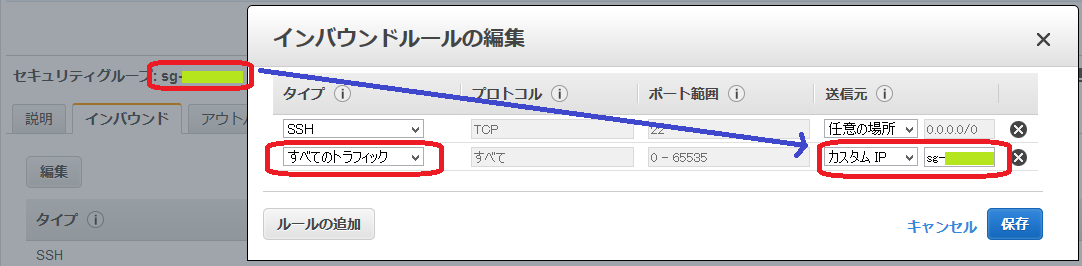
(本当は54321と54322のTCP/UDPだけ開ければいいんですが、まあすべてのトラフィックでも問題ないかと)
あとは、普通にインスタンスをリクエストして、セキュリティグループの設定のところだけ「既存のセキュリティグループを選択」 -> h2o-clusterを選べばOKです。
flatfile.txtを準備
インスタンスを起動すると情報がいろいろと見れますけど、

そん中から、各インスタンスのプライベートIPを拾って、以下のようなテキストファイルを作っておきます。
172.xxx.xxx.xxx:54321
172.yyy.yyy.yyy:54321
172.zzz.zzz.zzz:54321
h2oクラスタの起動
h2o.jarを起動していきます。全てのインスタンスで同じ作業が必要。
h2o のダウンロード
まずはh2oをダウンロードして解凍。ダウンロード情報のページで最新versionを確認してください。
sudo yum -y update
wget -q http://h2o-release.s3.amazonaws.com/h2o/rel-shannon/25/h2o-3.0.0.25.zip
unzip h2o-3.0.0.25.zip
cd h2o-3.0.0.25
train/testデータの取得
train/testデータをS3から引っ張ってくる。S3じゃなくてSCPやSFTPで送り込んでもいいんですが、全インスタンスで同じディレクトリに同じ名前のファイルを置いてやる必要があるので、そこだけ注意です。
export AWS_ACCESS_KEY_ID=MY_KEY
export AWS_SECRET_ACCESS_KEY=MY_SEC_KEY
aws s3 cp s3://mybucket/mydatafolder /home/ec2-user/h2o-3.0.0.25 --recursive
flatfile.txtの作成
flatfile.txtを、h2o.jarのあるフォルダに作る。まあviで普通に上のステップで作った情報を流し込めばよいですね。
vi flatfile.txt
172.xxx.xxx.xxx:54321
172.yyy.yyy.yyy:54321
172.zzz.zzz.zzz:54321
h2o.jarの起動
h2o.jarをnohup付きで起動
nohup java -jar h2o.jar -flatfile flatfile.txt > out.log 2>&1 &
ここで起動したプロセスを止めるにはps -A | grep javaで出てきたidをkill。
H2O FlowでBuild Model -> Predict
起動したクラスタを扱うのに、一番お手軽なのはH2O FlowのWeb UIですかね。h2o.jarを起動すると一緒にflowも起動されています。
Flowにアクセスするには、SSHでトンネル掘って、ブラウザでhttp://[ip_address]:54321へGO。SSHのトンネリングについては、以下をご参考に。
[「Amazon EMR クラスターでホストされているウェブサイトの表示」(とSparkのデバッグ)]
(http://qiita.com/pyr_revs/items/5e7212581b536fd436fb)
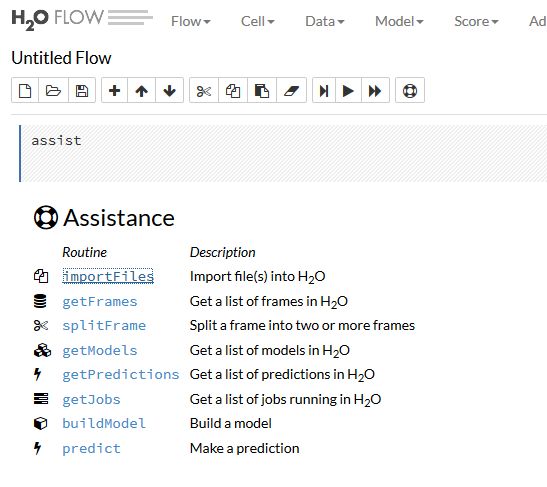
Flowの使い方
Assistance
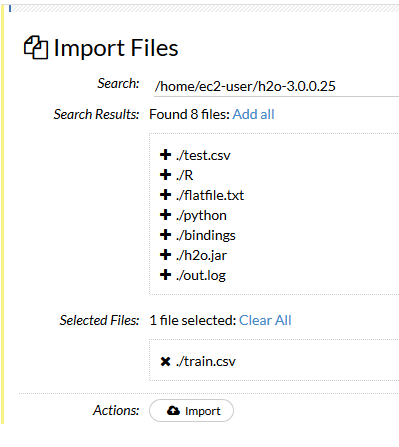
開くとAssistanceがでているとおもうので、ImportFileをクリックして、
ImportFile
Train/TestファイルをH2Oクラスタへimportして、h2oのframeとして認識させる
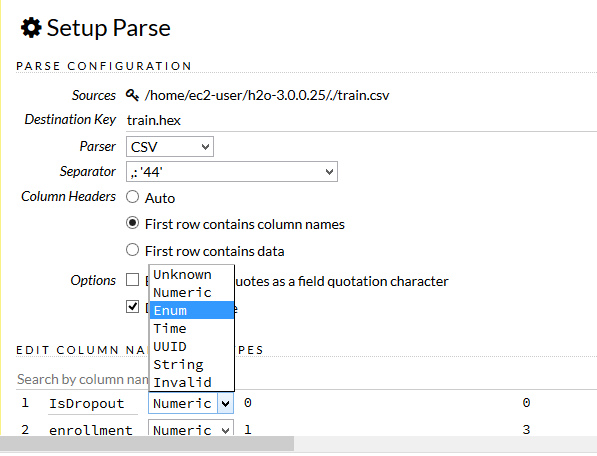
データのParse
headerの有る無し、各カラムのデータタイプ等々を指定。特にclassificationをする場合でラベルが数値の場合、ここでNumericからEnumに変換する必要があるので注意
データのステータス
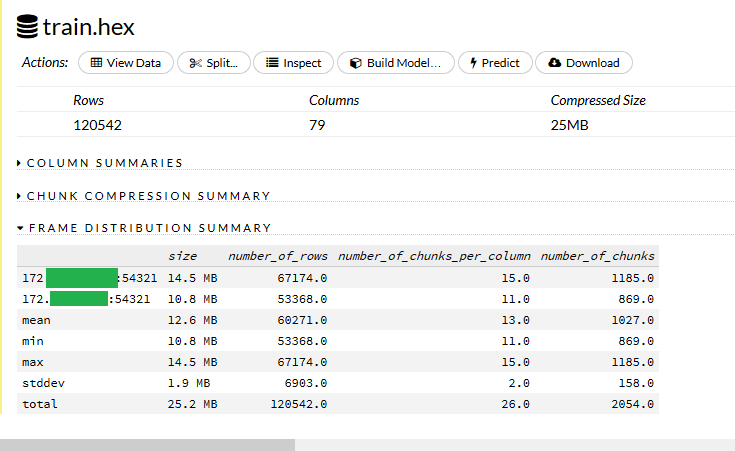
Frame Distribution Summaryを見ると、クラスタ内でのデータの分散されっぷりが見れます。
Build Model
手法はいろいろ選べます。
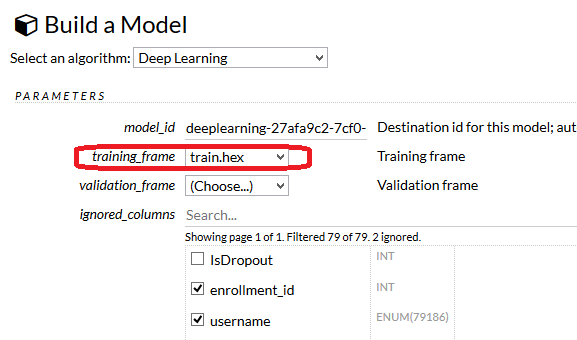
最低限、TrainするframeとResponse columnを選べばtrainningできます
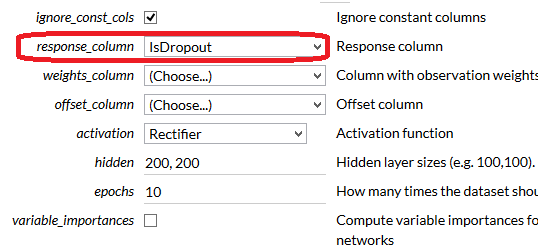
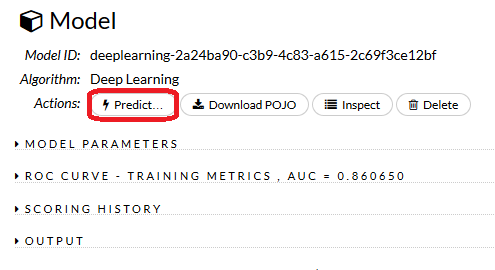
Predict
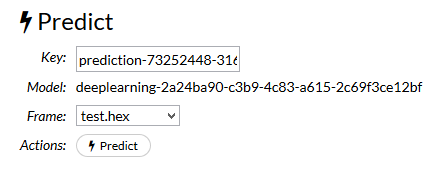
TestデータをPredict。build modelが終わったら、predictを押して、
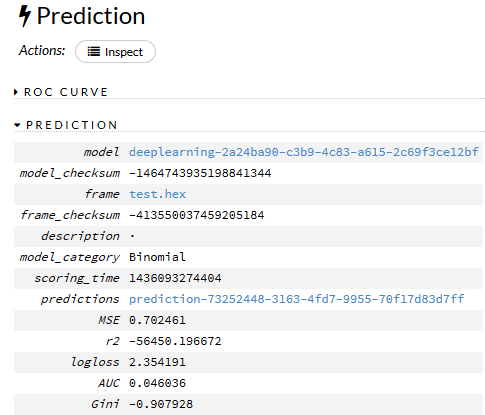
testデータのframeを選択
Predictionの結果。さらにpredictionsのリンクをクリックして詳細に進んで、
結果をダウンロード
Admin Menu
jobの途中でブラウザを閉じた場合、もう一度つないでAdminメニューからJobsを開くと状況が確認できます。詳細なlogやらCPU usageもここから。
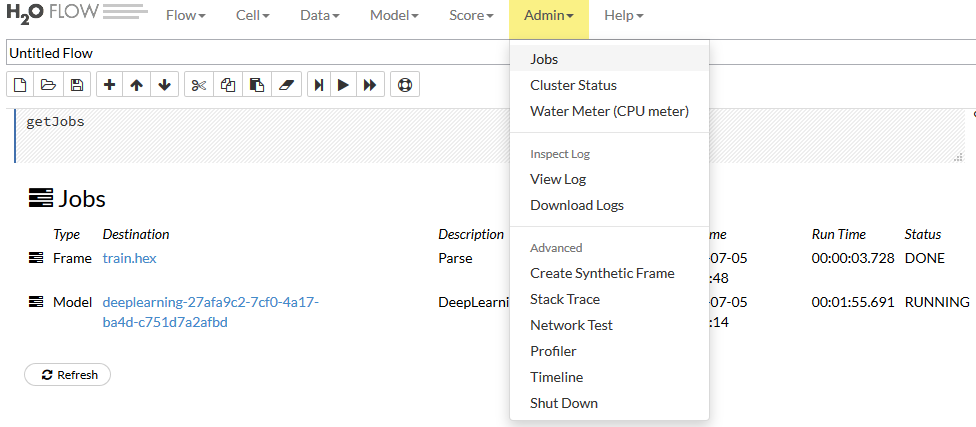
Split Frame
もちろん、trainデータを分割して、
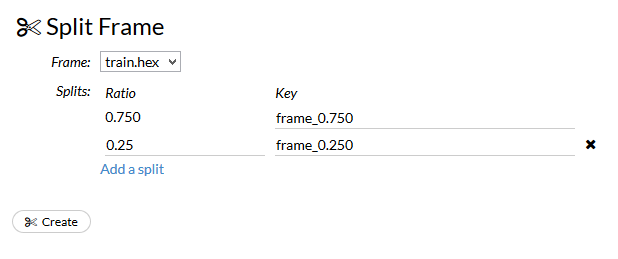
trainning_frameとvalidation_frameを設定したうえでBuild modelすることもできます。
終わりに
c4.8xlarge(36core)×3台でクラスタを立てまして、build modelをしてみると、logに「Estimated compute power : 128 GFlops」と出ました。
一方、gpuインスタンスを使った場合、単精度で1TFlops出るとか何とか。
単純に数値比較するのもアレですが、h2oで1TFlopsまでもっていくにはc4.8xlarge 2-30台必要?
コストパフォーマンス的にどうよ感はありますね。。。
まあ、h2oのいいところはいろいろな手法がさくっと使えるところ。DF RandamForestなんかはFlowでやると「Variable Importances」という形でfeatureの重要度なんかも確認できて使い勝手よいですね。Sparkのmllibだとこの辺はまだまだ感があったりなかったり。
Rでローカルマシンでやるとちょっと重いとかそういうデータにはよいんではないでしょうか。Flowを使えばコードも書かずにすみますしねえ。