前回、Windowsのローカル環境でSparkling Waterを動かしてみたわけですが、今回はその続き。
AWSのEC2で、パワフルなインスタンス(c4.8xlarge - 36 cores)をスポットで借りて、実行時間を詰めつつ、パラメーターを変えて精度を上げられるかどうか、というお話です。
Preparations
基本的には前回と同じなんですが、sbt assemblyでjarを作るようにしてみたので (sbt runだとnohupが上手く行かない模様) 、その辺に違いがあります。
ついでにですが、せっかくAWSを使うので、処理が終わったら自動でメールが飛んだりインスタンスを終了したりするために、Amazon SNS/SQSを使ってみます。
依存するjarの取得
h2o Sparkling-Water
readmeの中ほどに、「Downloads of binaries -> Sparkling Water - Latest version」というリンクがあると思うので、そこから。解凍してjarを取得しておきます。
これ書いてる時点のversionは、0.2.12-97。
Apache Spark 1.2.0
- Chose a Spark release: 1.2.0
- Chose a package type: PreBuild for hadoop 2.4 and later
- Chose a download type: Direct Download
とすると、4.で「spark-1.2.0-bin-hadoop2.4.tgz」のダウンロードリンクが出てきます。これを解凍して、jarを取得しておきます。
org.apache.httpcomponentsのhttpcore/client
AWS SDK for Javaをscalaから使いたいわけですが、sparkの中に既に入っているhttpcomponentsと重複してビルド時面倒なことになったので、別途取得しておいて実行時にclasspathから読み込ませる方針です。以下よりダウンロード可能。
http://mvnrepository.com/artifact/org.apache.httpcomponents/httpcore/4.4.1
http://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient/4.4.1
Amazon SNSの設定
Amazon SNSとは、プッシュ通知サービス。いろいろできますが、主にメールを送る機能を使います。いかんせんDeep Learningは処理時間が長くなる上に、パラメーターをいろいろ弄ってやり直しとかすることにもなりがちなので、処理結果の概要とかをこれ経由でメールに投げておくと、ぼちぼち便利です。
Topicの作成
Webのマネージメントコンソールから、モバイルサービス -> SNSへ入って、Create Topicから、「Service-Stats」「Proc-Finished」という名前で、2つTopicを作ります。
なお、TopicNameは名前の通りトピック名ですが、DisplayNameはメールの送信者名になります。10文字以内ならDisplayNameはなんでも良いですが、「AwsWatch」としておきました。
Subscriptionの作成
次に、作ったTopic「Service-Stats」の詳細ページから、Create Subscription。
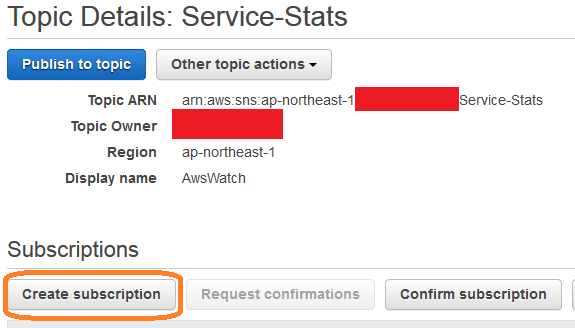
ProtocolをEmailにして、Endpointとして自分のメールアドレスを指定すれば、確認メールが飛びます。そこでConfirmすれば、SNS経由でメールが受け取れるようになります。Publish to topicでお試しメッセージを投げられるので、飛ばして受け取れることを確認しておくと良いのではないかと。
ついでにですが、上記画像で赤く消したTopic Ownerの数字が後で必要になるので控えておいてください。
「Proc-Finished」の方は、この時点ではsubscriprionはしてもしなくても良いです(後で使う)。
Source Codes
scalaのコード類を作っていきます。
build.sbt
Dependencyが諸々引っかかったので、ちょっと面倒な形になっておりますが。。。
name := "Kaggle"
version := "0.0.1"
organization := "my"
scalaVersion := "2.10.4"
scalacOptions ++= Seq("-Xlint", "-deprecation", "-unchecked", "-feature", "-Xelide-below", "ALL")
unmanagedBase := baseDirectory.value / "libs"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "1.2.0" % "provided",
"org.apache.spark" %% "spark-sql" % "1.2.0" % "provided",
"org.apache.commons" % "commons-lang3" % "3.4",
"com.amazonaws" % "aws-java-sdk" % "1.9.30"
.exclude("joda-time", "joda-time")
.exclude("org.apache.httpcomponents", "httpclient")
)
assembly.sbt
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.13.0")
DigitRecognizer.scala
処理本文。前回と同じく、Execute(dlParams, false)ならtrain.csvを8:2に分割してモデル確認モード。Execute(dlParams, true)ならtrain.csvを全部trainingデータとして使ってtest.csvに対するsubmission.txtを作ります。
package my
import org.apache.spark
import org.apache.spark._
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.sql._
import org.apache.spark.h2o._
import org.apache.spark.examples.h2o._
import water.fvec.H2OFrame
import hex.deeplearning.DeepLearning
import hex.deeplearning.DeepLearningModel.DeepLearningParameters
import hex.deeplearning.DeepLearningModel.DeepLearningParameters.{Activation, Loss, InitialWeightDistribution}
import hex.{FrameSplitter, SplitFrame}
import org.apache.commons.lang.builder._
object DigitRecognizer
{
val trainCsv = "/home/ec2-user/kaggle/data/digit/train.csv"
val testCsv = "/home/ec2-user/kaggle/data/digit/test.csv"
def main(args: Array[String]): Unit =
{
val dlParams = new DeepLearningParameters()
dlParams._max_categorical_features = 10
dlParams._epochs = 100
dlParams._hidden = Array[Int](1024, 1024, 2048)
dlParams._activation = Activation.RectifierWithDropout
dlParams._input_dropout_ratio = 0.2
dlParams._rate = 0.01
dlParams._rate_annealing = 1.0e-7
dlParams._rate_decay = 1.0
dlParams._momentum_start = 0.5
dlParams._momentum_ramp = 33600 * 6
dlParams._momentum_stable = 0.99
dlParams._l1 = 1.0e-5
dlParams._l2 = 0.0
dlParams._max_w2 = 15.0f
dlParams._initial_weight_distribution = InitialWeightDistribution.Normal
dlParams._initial_weight_scale = 0.01
dlParams._nesterov_accelerated_gradient = true
dlParams._loss = Loss.CrossEntropy
dlParams._adaptive_rate = false
dlParams._rho = 0.0
dlParams._epsilon = 0.0
dlParams._fast_mode = true
dlParams._diagnostics = true
dlParams._ignore_const_cols = true
dlParams._force_load_balance = true
//dlParams._classification_stop = -1
//val dlParamsStr = dlParamsToString(dlParams)
//println(dlParamsStr)
Execute(dlParams, false)
//Execute(dlParams, true)
}
def Execute(dlParams: DeepLearningParameters, useTestCsv: Boolean): Unit =
{
my.util.AwsAccessor.sendMessage("DigitRecognizer Start", "DigitRecognizer Start")
logging("Start")
val startTime = System.currentTimeMillis
val sparkConf = new SparkConf()
.setAppName("Kaggle-Digit")
.setMaster("local")
logging("Initialize SparkContext")
val sc = new SparkContext(sparkConf)
logging("Initialize H2OContext")
val h2oContext = new H2OContext(sc)
logging("Start H2OContext")
h2oContext.start()
logging(h2oContext.toString)
logging("Load TrainData")
val trainData = new H2OFrame(new java.io.File(trainCsv))
// For Classification, we need to convert the label value to Enum
trainData.replace(0, trainData.vec(0).toEnum) // Column 0 is "label"
logging("Split Data for Train/Test")
val sf = new FrameSplitter(trainData, Array(0.8), Array("train", "valid").map(water.Key.make(_)), null)
water.H2O.submitTask(sf)
val splits = sf.getResult
val spTrain = splits(0)
val spValid = splits(1)
logging("DeepLearning - Set Train / Valid data to param")
val resColName = "label"
dlParams._response_column = resColName
if(useTestCsv)
{
// All data for training
dlParams._train = h2oContext.dataFrameToKey(trainData)
}
else
{
// Use splitted data for train/valid
dlParams._train = h2oContext.dataFrameToKey(spTrain)
dlParams._valid = h2oContext.dataFrameToKey(spValid)
}
logging("DeepLearning - \"new\" object")
val dl = new DeepLearning(dlParams)
logging("DeepLearning - Training data, and generating model")
val dlModel = dl.trainModel.get
logging("dlModel")
println(dlModel)
logging("dlModel.score(train)")
println(dlModel.score(spTrain))
if(useTestCsv)
{
logging("dlModel.score(testCsv)")
val testData = new H2OFrame(new java.io.File(testCsv))
val predRes = dlModel.score(testData, resColName)
logging("Convert predicted values to array")
val sqlContext = new SQLContext(sc)
val predAry =
(h2oContext.asSchemaRDD(new org.apache.spark.h2o.DataFrame(predRes))(sqlContext))
.collect().map(row => row.getString(0))
logging("Output predicted values to text")
//predAry.foreach(println)
val file = new java.io.File("submission.txt")
val pw = new java.io.PrintWriter(new java.io.FileWriter(file))
pw.println("ImageId,Label")
var i = 1
for (line <- predAry)
{
pw.println(i.toString + "," + line)
i += 1
}
pw.close()
val execTime = System.currentTimeMillis - startTime
val report = "Run with test.csv"
sendReport(execTime, dlParams, report)
}
else
{
logging("dlModel.score(valid)")
val validFrame = dlModel.score(spValid)
println(validFrame)
val sqlContext = new SQLContext(sc)
val predAry =
(h2oContext.asSchemaRDD(new org.apache.spark.h2o.DataFrame(validFrame))(sqlContext))
.collect().map(row => row.getString(0))
val expectAry =
(h2oContext.asSchemaRDD(new org.apache.spark.h2o.DataFrame(spValid))(sqlContext))
.collect().map(row => row.getString(0))
val predWithExpect = (predAry zip expectAry).map(tpl => (tpl._1, tpl._2, (tpl._1 == tpl._2)))
val passCount = predWithExpect.filter(tpl => tpl._3 == true).size
val dataCount = predWithExpect.size
val execTime = System.currentTimeMillis - startTime
val report = "PassRate (%): " + (passCount.toDouble / dataCount.toDouble) * 100 + ", " + passCount + " / " + dataCount
sendReport(execTime, dlParams, report)
}
my.util.AwsAccessor.sendProcFinishedMessage()
logging("Stop SparkContext / H2O")
sc.stop()
water.H2O.shutdown()
}
def sendReport(execTime: Long, dlParams: DeepLearningParameters, report: String)
{
val ln1 = "Done, ExecTime (min): " + execTime / 1000 / 60
val ln2 = report
val ln3 = dlParamsToString(dlParams)
val message = ln1 + "\n\n" + ln2 + "\n\n" + ln3
println(message)
my.util.AwsAccessor.sendMessage("DigitRecognizer Done", message)
}
def logging(msg: String) =
{
val currntDateTime = "%tF-%<tT" format new java.util.Date
val logStr = currntDateTime + ": " + msg
println("####################")
println(logStr)
println("####################")
}
def dlParamsToString(dlParams: DeepLearningParameters): String =
{
val builder = ReflectionToStringBuilder.toString(dlParams, ToStringStyle.MULTI_LINE_STYLE)
builder.toString
}
}
AwsAccessor.scala
SNSへメッセージを飛ばすための諸々。アクセスキーと[Your Topic Owner number]は適宜書き換えてください
package my.util
import com.amazonaws.auth.BasicAWSCredentials
import com.amazonaws.regions._
import com.amazonaws.services.sns.AmazonSNSClient
import com.amazonaws.services.sns.model.CreateTopicRequest
import com.amazonaws.services.sns.model.CreateTopicResult
import com.amazonaws.services.sns.model.SubscribeRequest
import com.amazonaws.services.sns.model.PublishRequest
import scala.collection.JavaConversions._
object AwsAccessor
{
val accessKey = "Your key"
val secretKey = "Your Sec Key"
val credentials = new BasicAWSCredentials(accessKey,secretKey)
// SNS
val sns = new AmazonSNSClient(credentials)
sns.setRegion(Region.getRegion(Regions.AP_NORTHEAST_1))
def sendMessage(subject: String, message: String) =
{
val publishRequest = new PublishRequest()
publishRequest.setTopicArn("arn:aws:sns:ap-northeast-1:[your topic owner number]:Service-Stats")
publishRequest.setSubject(subject)
publishRequest.setMessage(message);
sns.publish(publishRequest);
}
def sendProcFinishedMessage()
{
val publishRequest = new PublishRequest()
publishRequest.setTopicArn("arn:aws:sns:ap-northeast-1:[your topic owner number]:Proc-Finished")
publishRequest.setSubject("DigitRecognizer Finished")
publishRequest.setMessage("DigitRecognizer Finished");
sns.publish(publishRequest);
}
}
S3に配置
上記のファイル類 + kaggleのcsvを、以下のようにS3に置きます。
[my bucket]/sparklib
| httpclient-4.4.1.jar
| httpcore-4.4.1.jar
└ spark-assembly-1.2.0-hadoop2.4.0.jar
[my bucket]/kaggle
| build.sbt
| DigitRecognizer.scala
| AwsAccessor.scala
└project
| assembly.sbt
└libs
| sparkling-water-assembly-0.2.14-97-all.jar
└data\digit
train.csv
test.csv
Run on EC2
EC2でスポットインスタンスを借りる
まあ、普通にスポットインスタンス借りるだけですが。
- Step1: マシンImageは、Amazon Linux AMI
- Step2: インスタンスタイプは、c4.8xlarge (36core, メモリ60GB, ストレージはEBSのみ)
- Step4: ストレージの設定は、デフォルトのEBS 8GBのままで
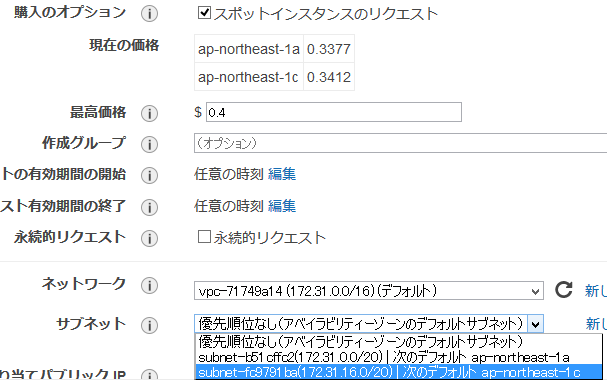
一つ問題は、Step3のスポットの入札価格のところ。なんか1aで突発的にぶっこんで来るやつがいるんですよね。
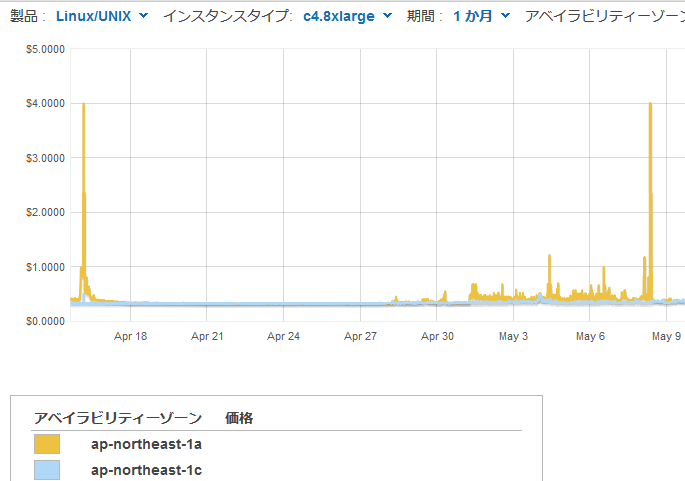
ということで、私は1cを主に使っています。入札$0.4/1hで。
EC2での環境構築 & 実行
1. yum update
インスタンスを立ち上げたら、まずはyum update。
> sudo yum update -y
2. リソースをS3から取得
> export AWS_ACCESS_KEY_ID=Yourkey
> export AWS_SECRET_ACCESS_KEY=YourSecKey
> export AWS_DEFAULT_REGION=ap-northeast-1
> mkdir /home/ec2-user/kaggle
> aws s3 cp s3://[my bucket]/kaggle /home/ec2-user/kaggle --recursive
> mkdir /home/ec2-user/sparklib
> aws s3 cp s3://[my bucket]/sparklib /home/ec2-user/sparklib --recursive
3. SBTのインストール
始めるsbt - Linuxへのsbtのインストールの、RedHat系のケースそのままで。
> curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
> sudo yum install sbt -y
4. SBT でビルド
初回ビルドはいろいろ依存系をダウンロードしてくるので、10分ぐらいかかります。
> cd /home/ec2-user/kaggle
> sbt assembly
成功すれば/home/ec2-user/kaggle/target/scala-2.10/Kaggle-assembly-0.0.1.jarが出来上がります。
5. Java用tmp dirを作っておく
javaコマンドで投げるとき、デフォルトのままだとtmpが足りないと出ることがあったので(df -hで見る限り全体のディスク容量は足りてるにも関わらず)、homeにtmpフォルダを作って、そっちを指定するようにします。
> mkdir /home/ec2-user/sparktmp
6. 実行 with nohup
classpathに依存jarの設定をぶち込みつつ、nohup付きでjarを実行
> cd /home/ec2-user
> CLASSPATH="/home/ec2-user/kaggle/target/scala-2.10/Kaggle-assembly-0.0.1.jar:"${CLASSPATH}
> CLASSPATH="/home/ec2-user/sparklib/spark-assembly-1.2.0-hadoop2.4.0.jar:"${CLASSPATH}
> CLASSPATH="/home/ec2-user/sparklib/httpclient-4.4.1.jar:"${CLASSPATH}
> CLASSPATH="/home/ec2-user/sparklib/httpcore-4.4.1.jar:"${CLASSPATH}
> nohup java -Xms32768m -Xmx32768m -Djava.io.tmpdir=/home/ec2-user/sparktmp/ -classpath ${CLASSPATH} my.DigitRecognizer > out.log 2>&1 &
Xms/Xmxのメモリの設定は適当。ま、c4.8xlargeなら60GBはあるんで。
一応、classpathの区切り文字はUnix(:)とWin(;)で違うようなので、お気を付けを。
実行に至るコマンドを、一括で
step by stepで流すのは面倒なので、実際には一括でコマンド投げればいいんですが、その途中でaws cliでsnsトピックへのメッセージ送信をしておくと、処理状況が見えて便利です(特に長いsbt assemblyの前後)
aws sns publish --topic-arn arn:aws:sns:ap-northeast-1:[your topic owner number]:Service-Stats --subject "Message Title" --message "Message Body"
まとめると、
sudo yum update -y
export AWS_ACCESS_KEY_ID=[Yourkey]
export AWS_SECRET_ACCESS_KEY=[YourSecKey]
export AWS_DEFAULT_REGION=ap-northeast-1
mkdir /home/ec2-user/kaggle
aws s3 cp s3://[my bucket]/kaggle /home/ec2-user/kaggle --recursive
mkdir /home/ec2-user/sparklib
aws s3 cp s3://[my bucket]/sparklib /home/ec2-user/sparklib --recursive
curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
sudo yum install sbt -y
cd /home/ec2-user/kaggle
aws sns publish --topic-arn arn:aws:sns:ap-northeast-1:[your topic owner number]:Service-Stats --subject "sbt assembly start" --message "sbt assembly start"
sbt assembly
aws sns publish --topic-arn arn:aws:sns:ap-northeast-1:[your topic owner number]:Service-Stats --subject "sbt assembly done" --message "sbt assembly done"
cd /home/ec2-user
mkdir /home/ec2-user/sparktmp
CLASSPATH="/home/ec2-user/kaggle/target/scala-2.10/Kaggle-assembly-0.0.1.jar:"${CLASSPATH}
CLASSPATH="/home/ec2-user/sparklib/spark-assembly-1.2.0-hadoop2.4.0.jar:"${CLASSPATH}
CLASSPATH="/home/ec2-user/sparklib/httpclient-4.4.1.jar:"${CLASSPATH}
CLASSPATH="/home/ec2-user/sparklib/httpcore-4.4.1.jar:"${CLASSPATH}
nohup java -Xms32768m -Xmx32768m -Djava.io.tmpdir=/home/ec2-user/sparktmp/ -classpath ${CLASSPATH} my.DigitRecognizer > out.log 2>&1 &
実行中
tail -f out.logで処理状況を確認したり、topでCPU usageを見たり。
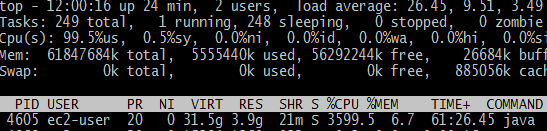
javaの%CPUが3599.5と振り切れておりまして、とても素敵。
途中で止めたい場合
単純にjavaのプロセスとして動いているので、ps -A | grep javaとしてpidを拾ってkill [pid]で。
Results and more
結果1
validデータに対するclasificationエラーが、このモデルの評価になります。0.0174 = 146 / 8,400は正答率98.26%ですね。実行時間は13分ぐらい。
####################
dlModel.score(valid)
####################
Confusion Matrix:
| Act/Pred | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Error |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 847 | 0 | 0 | 1 | 0 | 0 | 3 | 0 | 1 | 0 | 0.0059 = 5 / 852 |
| 1 | 0 | 945 | 2 | 0 | 0 | 0 | 0 | 2 | 1 | 0 | 0.0053 = 5 / 950 |
| 2 | 3 | 1 | 789 | 2 | 0 | 0 | 1 | 3 | 1 | 1 | 0.0150 = 12 / 801 |
| 3 | 1 | 1 | 6 | 860 | 0 | 6 | 0 | 5 | 1 | 2 | 0.0249 = 22 / 882 |
| 4 | 0 | 5 | 0 | 0 | 791 | 0 | 4 | 3 | 1 | 7 | 0.0247 = 20 / 811 |
| 5 | 2 | 1 | 1 | 4 | 0 | 729 | 3 | 0 | 5 | 2 | 0.0241 = 18 / 747 |
| 6 | 2 | 2 | 0 | 0 | 2 | 0 | 825 | 0 | 0 | 0 | 0.0072 = 6 / 831 |
| 7 | 2 | 1 | 4 | 1 | 0 | 0 | 0 | 872 | 1 | 3 | 0.0136 = 12 / 884 |
| 8 | 1 | 7 | 1 | 2 | 1 | 7 | 3 | 0 | 780 | 0 | 0.0274 = 22 / 802 |
| 9 | 3 | 2 | 1 | 3 | 3 | 2 | 0 | 8 | 2 | 816 | 0.0286 = 24 / 840 |
| Totals | 861 | 965 | 804 | 873 | 797 | 744 | 839 | 893 | 793 | 831 | 0.0174 = 146 / 8,400 |
もう少し頑張ってみる
まあ実は、上のDigitRecognizer.scalaで、dlParamsに設定した各種ハイパーパラメーターは、以下のブログのRでの設定を丸パクリしてsparkling water用に翻訳したものでした。。。
H2OのRパッケージ{h2o}でお手軽にDeep Learningを実践してみる(3):MNISTデータの分類結果を他の分類器と比較する
それだけじゃ芸がないので、もう少し弄って精度を出せるかどうか。
モデルのダンプに出てくる、ログのscoring historyを見直してみると、指定は100にも関わらず、84 Epochで途切れておりました。デフォルトでは、「Training Classification Error」が「0」になると、それ以上は過学習っぽいと判断されて、自動で止めてくれる設定になっているから、ということみたいですね。
####################
dlModel
####################
...
Scoring History:
| Training Duration | Training Speed | Training Epochs | Training Samples | Training MSE | Training R^2 | Training Classification Error |
|---|---|---|---|---|---|---|
| 0.000 sec | 0 | 0 | NaN | NaN | 1 | |
| 43.582 sec | 3083.842 rows/sec | 4 | 134400 | 0.03386 | 0.99596 | 0.03864 |
| ... | ... | ... | .... | ... | .... | ... |
| 11 min 51.124 sec | 3779.931 rows/sec | 80 | 2688000 | 0.00015 | 0.99998 | 0.0001 |
| 12 min 25.608 sec | 3785.367 rows/sec | 84 | 2822400 | 0.00006 | 0.99999 | 0 |
dlParams._classification_stop = -1とすると、指定のEpochまで学習を続けさせることはできますが、Training Classification Errorが0の状況だと学ぶことはあんまり無いようで、validデータに対する全体のclassificationエラーも減っていかないという状況になります。
対処として、Training Classification Errorを収束させずにもっと細かく学習しろと指示を出しつつ、Epochをバカみたいに増やすという方向で考えていきます。
一番お手頃な設定はhiddenの数。
差し当たりdlParams._hidden = Array[Int](1568,1568,3136)として、epochも400としてみると、正答率98.57%。実行時間は2時間半ほど。
もう一声、と思ってhiddenをいろいろ変えてみるも。。。実はH2Oにはhiddenの数の限界があるようでして、例えば(5000,5000)とかやるとToo muchと怒られます。
PUBDEV-941 Large DL models cause oversize issues during serialization
あと変えられそうなところは、と、以下をいろいろ変えてみるも、どうもただ収束が遅くなるだけで、あんまり正答率伸びず。
- Rate
- Momentum
- L1
最後にたどり着いたのが、Dropoutのレート。
デフォルトでは0.5になってますが、これを0.7まで引き上げて、Epochも上げてみると。
正答率が伸び始めます。
結果2
最終的には、以下の設定でsubmissionを出してみたところ。
dlParams._epochs = 2000
dlParams._hidden = Array[Int](2048, 2048, 4096)
dlParams._hidden_dropout_ratios = Array[Double](0.75,0.75,0.7)
dlParams._input_dropout_ratio = 0.5
dlParams._momentum_ramp = 33600 * 10
dlParams._momentum_stable = 0.9999
正答率0.98929で59位とでました。実行時間は12時間ほどかかりましたがね。。。
https://www.kaggle.com/c/digit-recognizer/leaderboard
実はこのモデル、2000 epochsでも収束してません。あとちょっとで正答率99%の大台と思うと、3000 epochsで回しておけばとは思いましたが、また$0.4 * 10数時間と考えると、もういいかなと。
| Duration | Training Speed | Epochs | Samples | Training MSE | Training R^2 | Training LogLoss | Training ClassificatioError |
|---|---|---|---|---|---|---|---|
| … | … | … | … | … | … | … | … |
| 6.274 sec | 1735.565 rows/sec | 101.91379 | 4280379 | 0.00603 | 0.99927 | 0.02263 | 0.00739 |
| 01:15:10.19 | 1863.633 rows/sec | 200.12704 | 8405336 | 0.0028 | 0.99966 | 0.01021 | 0.00334 |
| 02:58:43.26 | 1959.737 rows/sec | 500.35165 | 21014770 | 0.00062 | 0.99992 | 0.00251 | 0.00061 |
| 05:56:00.63 | 1969.602 rows/sec | 1001.71277 | 42071937 | 0.00026 | 0.99997 | 0.00111 | 0.0004 |
| 09:00:18.22 | 1944.863 rows/sec | 1501.16687 | 63049007 | 0.00018 | 0.99998 | 0.00075 | 0.0001 |
| … | … | … | … | … | … | … | … |
| 12:07:39.58 | 1917.443 rows/sec | 1993.20776 | 83714731 | 0.00011 | 0.99999 | 0.00045 | 0.0001 |
| 12:08:42.75 | 1917.340 rows/sec | 1995.98535 | 83831382 | 0.0001 | 0.99999 | 0.00042 | 0.0001 |
| 12:09:48.72 | 1917.117 rows/sec | 1998.76477 | 83948123 | 0.00011 | 0.99999 | 0.00046 | 0.0002 |
| 12:10:32.04 | 1917.001 rows/sec | 2000.62073 | 84026070 | 0.00012 | 0.99999 | 0.00047 | 0.0001 |
SNS + SQSで、logをS3へアップロード & インスタンスの自動終了
ずっと画面の前に張り付いているわけにもいかないので、終わったらおいそれと自動終了したくなることがあるかと思います。
scalaの処理内でAWS SDK経由でやってもいいんですが、本処理とは別に、後付でインスタンス終了のフラグ的なものを立てて、それを別のプロセスが処理するという形の方が、急な呼び出しやら急なやる気の喪失に対応できて便利ですよね。
フラグを立てて次に処理をお願いする、これはAmazon SQSのキューでやるのが簡単そうです。
んで、こんな記事を読みまして。
【AWS】SQSキューの前には難しいこと考えずにSNSトピックを挟むと良いよ、という話
scalaからSQSのキューを投げてもいいですが、既にscalaではSNSでのメッセージ送信をやっているわけです。その延長線上で、
- scalaからは終了メッセージをSNSで送って、
- SNS -> SQSでキューを入れ、
- SQSを監視するプロセスを回しておいて、
- SQSキューを捕捉したらインスタンスを止めたりログをS3にアップロードしたりする
ようにしてみます。
Amazon SQSの設定
SQSキューの作成
「Terminate-Instance」という名前でSQSキューを新規作成。作成後、SQS:SendMessageへのアクセス許可を+してください。
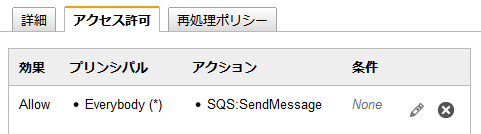
ここで、SQSキューのARNをメモっておきます。
尚、画像は終わったら消す前提でEverybodyに振っちゃってますが、恒常的に使うならIAM ユーザに対してちゃんと設定しましょう ( ステップ 4. 適切なトピックおよびキューアクションに対するアクセス許可を与える )
SNSのsubscription設定
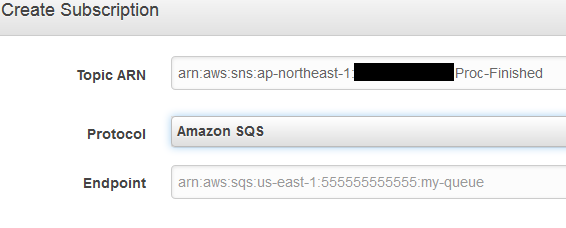
SNSの設定をしたときに使わなかった「Proc-Finished」
こいつのsubcriptionのEndpointとしてSQSのARNを設定すると、SNSにメッセージが飛んできたとき、SQSにキューを入れてくれます。
SQSキューを待ち受けして、処理するプロセス
ざっと検索した感じ、rubyがよさげだったので。
AWS SDK for Rubyのインストール
> sudo yum -y install rubygem20-aws-sdk
ログアップロード & インスタンス終了スクリプトの作成
vi sqs.rbとして、
require 'rubygems'
require 'aws-sdk'
AWS.config(:access_key_id => 'Your key',
:secret_access_key => 'Your sec key',
:sss_endpoint => 'sqs.ap-northeast-1.amazonaws.com',
:region => 'ap-northeast-1')
url = 'https://sqs.ap-northeast-1.amazonaws.com/[your topic owner number]/Terminate-Instance'
sqs = AWS::SQS.new
ec2 = AWS::EC2.new
s3 = AWS::S3.new
while true
receive = sqs.queues[url].receive_message()
if receive
message = JSON.parse(receive.body)
puts message['Message']
puts message['Timestamp']
bucket = s3.buckets['your bucket name']
filename1 = "/home/ec2-user/out.log"
basename1 = File.basename(filename1)
o = bucket.objects[basename1]
o.write(:file => filename1)
filename2 = "/home/ec2-user/submission.txt"
basename2 = File.basename(filename2)
o = bucket.objects[basename2]
o.write(:file => filename2)
i = ec2.instances["i-123456789"]
i.terminate
receive.delete
exit
end
puts "Waiting"
sleep 60
end
これ、エラートラップしてないので、S3に既にファイルがあったり、逆にsubmission.txtが無いままアップロードしようとしたりすると落ちます。
落ちるとインスタンス終了のところまでたどり着かずに課金され続けたりするので、必要に応じてファイルの存在チェック入れてください(私は運用でカバーでいいや的な)。
実行
例によってnohupで。
> nohup ruby sqs.rb > sqs.log 2> sqserr.log &
終わりに
実はEMR上でもちょいとだけ動かしてみたですが。
10台借りて8台しか認識されてない、よし一度止めてもう一度流しなおすかとやってみると3台しか認識されなくなったり、sparkling-waterのversionを上げるとFrameSplitterのあたりがエラー吐きまくって手が付けられなくなったりで、そちらでの実行は個人的にはしばらく様子見ですね。Spark 1.3対応するか、Maven repoがまともになってくれるぐらいまでかなぁ。
あと、c4.8xlargeをスポットで使い始めて思ったけど、EMRは加算料金意外とかかります(c3.8xlargeで$0.270。EMRで2台借りると、EMR無しでスポットもう一台借りられちゃう感じ)。
もしスケールさせたい場合でも、以下のh2o.jarを各マシンに配って自力でクラスタ立てる方法が良いのかもですね。
H2O on EC2
H2O on a Multi-Node Cluster
まあ試してないですが、というかここまで書いてきて、sparkling-waterとは何だったのかという気もしていますが。。。