(目次はこちら)
(Tensorflow 2.0版: https://qiita.com/kumonkumon/items/435952e45662dfe140b4)
はじめに
前回の記事では、フィルタを固定した畳み込みニューラルネットワークに、プーリング層を追加した。今回は、これをさらに拡張して、一般的な(フィルタも学習する)畳み込みニューラルネットワークへとつなげていこうかと。
拡張:ドロップアウト層(dropout layer)の追加
ニューラルネットワークに限らず、機械学習では一般的に、モデルが複雑であればあるほどヒョ現能力は高いが、過学習(over fitting)に陥りやすい。過学習とは、学習データ用にパラメータ調整されてしまい、本来識別したい未知のデータに対しての性能が悪くなってしまうこと。
ディープニューラルネットワークやディープラーニングでは、モデルが複雑になるので過学習の課題がつきまとう。これはニューラルネットワークが冬の時代に入った理由の一つ。
で、過学習に対して効果があるとされているのが、ドロップアウト。これは、パラメータの学習フェーズにおいて、ある層でせっかく抽出した情報を欠落させるという大胆なもの。例えば、ある層で100次元の特徴ベクトルが得られたとして、そのうちの50次元(ランダム抽出)はなかったことにするというもの。これによってアンサンブル学習(いろいろなパターンで学習してその平均をとるみたいな)の効果が得られるとのこと。あとは、ランダムにリンクを失うので特定のリンクのウェイトに頼るような事が起こりにくくなり、正則化項と同じような役割を果たす。
ここでは、全結合層の後ろに入れる。
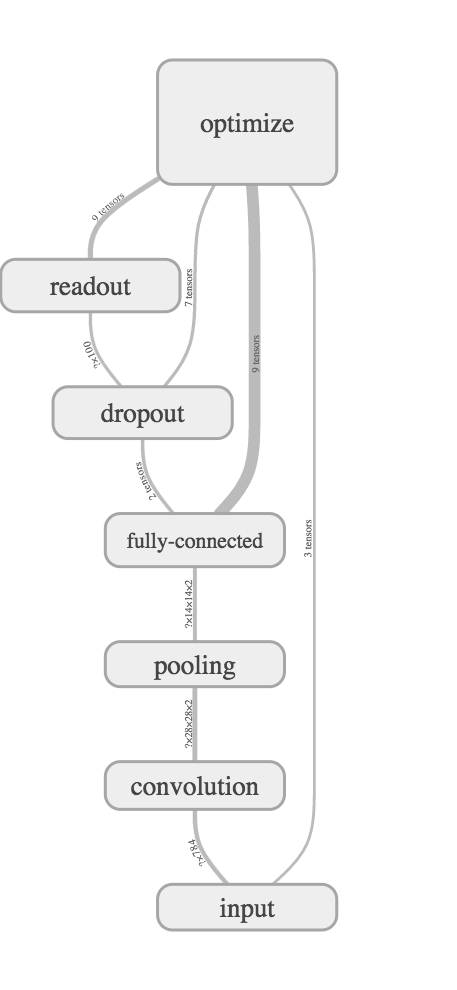
コード
Python: 3.6.8, Tensorflow: 1.13.1で動作確認済み
(もともと2016年前半に書いたものなので、順次更新しています。)
from helper import *
IMAGE_WIDTH, IMAGE_HEIGHT = 28, 28
CATEGORY_NUM = 10
LEARNING_RATE = 0.1
FILTER_NUM = 2
FEATURE_DIM = 100
KEEP_PROB = 0.5
TRAINING_LOOP = 20000
BATCH_SIZE = 100
SUMMARY_DIR = 'log_fixed_cnn'
SUMMARY_INTERVAL = 1000
BUFFER_SIZE = 1000
EPS = 1e-10
with tf.Graph().as_default():
(X_train, y_train), (X_test, y_test) = mnist_samples()
ds = tf.data.Dataset.from_tensor_slices((X_train, y_train))
ds = ds.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat(int(TRAINING_LOOP * BATCH_SIZE / X_train.shape[0]) + 1)
next_batch = ds.make_one_shot_iterator().get_next()
with tf.name_scope('input'):
y_ = tf.placeholder(tf.float32, [None, CATEGORY_NUM], name='labels')
x = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT, IMAGE_WIDTH], name='input_images')
with tf.name_scope('convolution'):
W_conv = prewitt_filter()
x_image = tf.reshape(x, [-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
h_conv = tf.abs(tf.nn.conv2d(x_image, W_conv, strides=[1, 1, 1, 1], padding='SAME'))
with tf.name_scope('pooling'):
h_pool = tf.nn.max_pool(h_conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
with tf.name_scope('fully-connected'):
W_fc = weight_variable([int(IMAGE_HEIGHT / 2 * IMAGE_WIDTH / 2 * FILTER_NUM), FEATURE_DIM], name='weight_fc')
b_fc = bias_variable([FEATURE_DIM], name='bias_fc')
h_pool_flat = tf.reshape(h_pool, [-1, int(IMAGE_HEIGHT / 2 * IMAGE_WIDTH / 2 * FILTER_NUM)])
h_fc = tf.nn.relu(tf.matmul(h_pool_flat, W_fc) + b_fc)
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
h_drop = tf.nn.dropout(h_fc, keep_prob)
with tf.name_scope('readout'):
W = weight_variable([FEATURE_DIM, CATEGORY_NUM], name='weight')
b = bias_variable([CATEGORY_NUM], name='bias')
y = tf.nn.softmax(tf.matmul(h_drop, W) + b)
with tf.name_scope('optimize'):
y = tf.clip_by_value(y, EPS, 1.0)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), axis=1))
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy)
cross_entropy_summary = tf.summary.scalar('cross entropy', cross_entropy)
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(SUMMARY_DIR + '/train', sess.graph)
test_writer = tf.summary.FileWriter(SUMMARY_DIR + '/test')
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
accuracy_summary = tf.summary.scalar('accuracy', accuracy)
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_LOOP + 1):
images, labels = sess.run(next_batch)
sess.run(train_step, {x: images, y_: labels, keep_prob: KEEP_PROB})
if i % SUMMARY_INTERVAL == 0:
train_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: images, y_: labels, keep_prob: 1.0})
train_writer.add_summary(summary, i)
test_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: X_test, y_: y_test, keep_prob: 1.0})
test_writer.add_summary(summary, i)
print(f'step: {i}, train-acc: {train_acc}, test-acc: {test_acc}')
コードの説明
変更点を。
ドロップアウト層
追加された層。
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
h_drop = tf.nn.dropout(h_fc, keep_prob)
出力層
全結合層の出力から、ドロップアウト層の出力を入力に。
with tf.name_scope('readout'):
W = weight_variable([FEATURE_DIM, CATEGORY_NUM], name='weight')
b = bias_variable([CATEGORY_NUM], name='bias')
y = tf.nn.softmax(tf.matmul(h_drop, W) + b)
学習&評価時
ドロップアウト率を渡してあげる必要があり、
学習時には、0.5(KEEP_PROB)を。
sess.run(train_step, {x: images, y_: labels, keep_prob: KEEP_PROB})
評価時には、1.0(ドロップアウトさせない)を。
train_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: images, y_: labels, keep_prob: 1.0})
test_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: X_test, y_: y_test, keep_prob: 1.0})
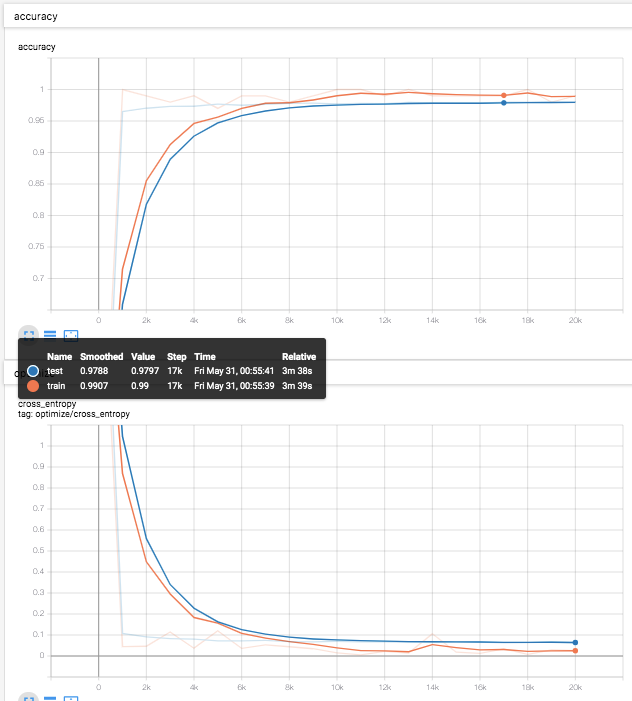
結果
テストデータ(青線)での識別率は、97.9%程度。
ドロップアウトを追加することで若干落ちていて、やはり固定フィルタでの限界。
あとがき
今回は、前回の記事で紹介したフィルタを固定した畳み込みニューラルネットワークに、ドロップアウト層を追加してみました。次回の記事では、Prewitte filterで固定していた畳み込み層のウェイトも学習によって推定するようにしてみます。