はじめに
この記事は実際に手を動かし、コンピュータを使ってデータ可視化を行う人にむ向けて一般的なノウハウをお伝えする三回シリーズの最終回です。
前回までに私が可視化を行うときに従っているおおよその作業の流れと手法の選択方法などをまとめました。最終回は可視化作業全般で私が気をつけている基本原則と、更にこの分野を学び続けるための学習ガイドです。思いつくままに書いていたらダラダラと長くなってしまいましたので、必要なところだけ拾い読みしていただければと思います。
可視化を行う時に従うべき基本原則
いつでも機械的に適用できる都合のいいルールというものはなかなか無いのですが、考え方として常に意識しておいた方が良い原則と言うものはいくつかあります。ここでは、私が本や専門家のレクチャーなどから学んだそれらをまとめます。
チャートジャンクを避ける

[Tufte 1983, 2001. p. 111]
チャートジャンク(Chartjunk)という用語は、情報可視化研究の先駆者であるエドワード・タフテによる造語です。彼の著作から引用してみますとその定義は、
The interior decoration of graphics generates a lot of ink that does not tell the viewer anything new. The purpose of decoration varies — to make the graphic appear more scientific and precise, to enliven the display, to give the designer an opportunity to exercise artistic skills. Regardless of its cause, it is all non-data-ink or redundant data-ink, and it is often chartjunk.
(図内部の装飾は、見る人に何の新しい情報も伝えない大量のインクを生み出す。その目的は様々である ― 時には図をより科学的で正確にするために、またある時はデザイナーの芸術的スキルを披露する機会として。しかし理由はどうあれ、それらは全てデータをエンコードしないインクであり、冗長なものである。そして往々にしてそれはチャートジャンクである。)
Tufte, Edward R. (1983, 2001). The Visual Display of Quantitative Information 2nd edition p. 107. Cheshire, CT. Graphics Press. (日本語訳は私によるもので、正確さより日本語としての伝わりやすさを優先してあります。以下も同様です。)
これは別に難しいことを言っているわけではなく、__データ可視化では情報を伝えるのに必要ない無意味な装飾を避けよ__ということです。つまり、
- 過剰に説明的な装飾
- デザイナーの自己満足のための装飾
- データをエンコードしない装飾
こういったものを極力排除して表現方法を出来る限りミニマルにまとめよ、というだけのことです。デザイナーの方は美しく複雑な図を描く技術があるがゆえにやってしまいがちなのですが、それが情報を伝える役割を果たしていない限り情報可視化の視点からはチャートジャンクとみなされます。この辺りがアートやデザインのスキルと情報可視化の技術が異なる点で、画面(紙)上の全てのもの(インク、もしくはピクセル)が、データポイントを変換した結果であることが最も重要視されます。
(これは手書きですが、類似のExcelで作った三次元チャートはよく目にするのではないでしょうか [Tufte 2001. p. 118])
彼の美学からすると、こういった「情報をエンコードしていない無意味な模様」というものがどうしても許せないらしく、この本の一章まるごと「チャートジャンク」と言う章にあてていて、徹底的に批判しています。ちなみにこの本の初版は30年以上前に出たものなので、殆どの部分で紙の上に情報を変換してインクで表現する技術を論じていますが、特定のテクノロジーに依存していないため、現在でも内容はほぼそのまま通用します。
データ/インク比
チャートジャンクという概念を理解するのに、「データ/インク比(以下D/I)」の定義を理解しておくと良いと思います。これもシンプルな概念で、
データ/インク比 = データをエンコードしているインク量 / 紙面全体で使われているインクの総量
ということです。つまり__一般的なルールとしてこの比を最大化するのが、良い可視化を作成するときの一つの指標になります__。「インク量」を「ピクセル数」に、「紙面」を「画面」に置き換えることにより、計算機ベースの可視化でもそのまま通用する概念です。

[Tufte 2001. p. 93]
データをエンコードするインク
ここの指標で使われている__データをエンコードするインク__とは、具体的には以下の様なものです:
- 散布図における一つの観測値を表す__点__
- ヒストグラムにおける各階級の頻度を表す__バー__
- node-link diagramにおけるエッジを表す__線分__とノードを表す__図形__
- box plotにおける中央値/第1四分位点等を表す__線分__やmix/maxを表すひげ
これらは明確に元のデータセットから受け取った情報をそのまま視覚要素にエンコードしています。
一方、微妙なものもあります:
- 軸にふられた数字
- 軸そのもの
- キャプション
これらは必要な時もありますが、必ずしも必要でない場合もあります。そしてチャートジャンクは情報量ゼロの要素です:
- バーの中に描かれた模様
- 立方体として描かれたヒストグラムのバーにおけるZ軸そのもの
- 3D円グラフのZ軸そのもの
- データと関係のないイラスト
画面上の要素をこのカテゴリの何処に属するのかを意識しながら作成することにより、不必要な要素が入り込む可能性を最小化出来ます。ExcelでもTableauでもそうですが、デフォルトの描画設定は必ずしもミニマルに設定してありませんので、情報を伝えるのに必要最小限にするにはどのようなデフォルト設定で始めればよいのか、というのも意識してツールを使用するのが良いと思います。特に「あっても良いが、なんとなく冗長な感じがする」と言う要素(上で書いた2番目の要素)はなかなか取捨選択が難しいと思いますが、全体のバランス、伝えたい情報の順位などを考慮に入れて判断して下さい。
D/Iの最大化
以上を踏まえて要点をまとめると、良い可視化とは出来る範囲でD/Iを最大化したものだと言えます。現代のコンピュータ化されたデータ可視化では、画面上に表示された画像のうちできるだけ多くのピクセルがデータのエンコード先になっていることが望ましいということです。タフテは著書の中で、一般的な可視化手法からさらにインク(=線分や点)を引いて、情報を失うことなくどこまでミニマルな表現が可能かということも行っています。以下はその一例です:
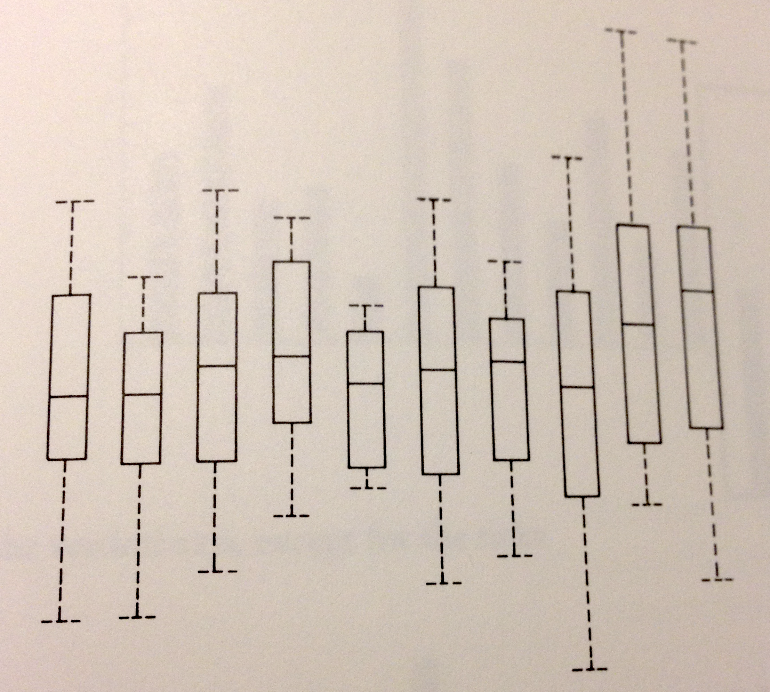
こちらは普通のボックスプロットです [Tufte 2001. p. 125]。これから情報を失わない範囲で余計な装飾を極限まで削ぎ落とすと…
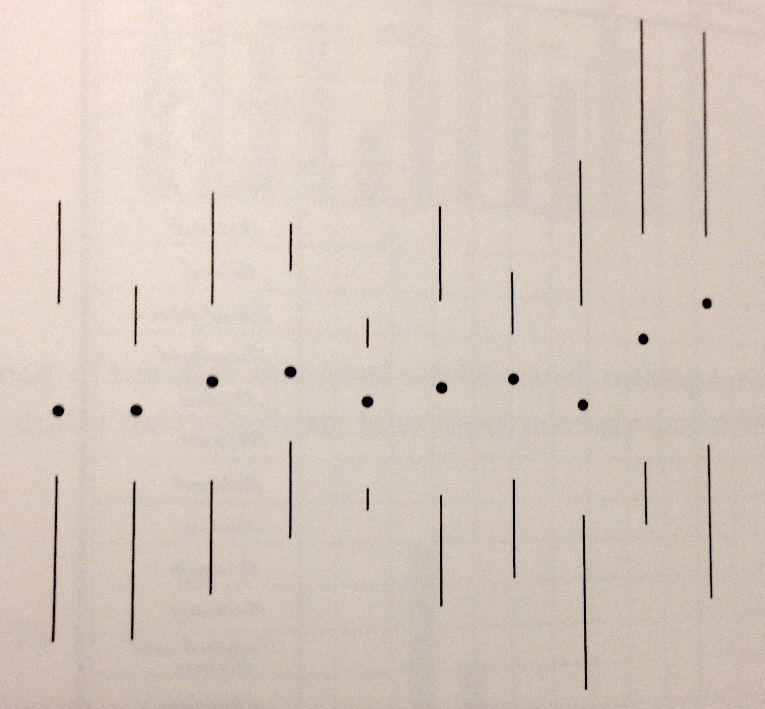
こうなります。__この表現でもオリジナルのプロットに含まれていた5つの情報(min, max, median, Q1, Q3)は失われません__ので、D/Iの最大化という観点からは有効です。個人的にはこの例はちょっとやり過ぎかな、と感じます。と言うのも、ボックスプロットのように定着した表現方法には、改良版に比べてインクをわずかに多く消費する代わりに、読み方を知っている人は一瞬で理解できるというメリットもあるからです。この辺りは必要に応じて適切に使い分ければ良いと思います。D/I最大化の考え方は、D3.js等の高度にカスタマイズ可能なツールキットを用いて、既存の手法を融合したり新しい手法を開発する時に有効だと思います。手法の複合などで生成したオリジナルな可視化は、当然それまでの手法よりもより多くを盛り込もうという試みですから、各データの表現方法を極限までそぎ落として簡略化するのは有効に働くはずです。
Sparklineも、この考えを発展させたものと捉えることが出来ます。一般的なラインチャートからグリッドもベースラインも全て取り除き、文章中に埋め込めるアイコンのようなものにまで凝縮した可視化手法です。


よく目にする基本的な手法も、僅かな改良でまた異なる手法に変化させることが出来ますので、プログラミングが出来る皆さんはこれらの基本原則を意識した上で色々実験してみると面白いと思います。
データ濃度
類似の概念として、タフテは__データ濃度(data density)__と言う指標も紹介しています:
画面のデータ濃度 = 画面上のデータポイントの数 / データを表示するディスプレイの面積
これも単純な単位面積当たりの情報量を表す指数です。最適なデータ濃度は、最終的に出力するメディア(紙、スマホの画面、4Kディスプレイ等)によって異なると思われるのですが、一般的にはこれは見づらくない程度まで高めるのが良いでしょう。このような非常に単純な指標でも、意識して画面を眺めることにより客観的な良さをある程度判断できます。この辺りが普通のデザインやイラストレーションと異なり、文書化・数値化が可能なため、比較的プログラマーにも学びやすいと私が思う理由です。
可視化の作業がコンピュータベースになってから、コピー&ペーストが楽になった上に、コードを書くことでいくらでも反復作業ができるようになったため、インクやピクセルを無駄に使うことはより簡単になりました。この誘惑に負けないのが大切なポイントだと思います。
まとめ
- データ/インク比(もしくはデータ/ピクセル比)を最大化せよ
- 最終的な出力先に最適な範囲でデータ濃度を最大化せよ
ヘテロなデータセットを一つの可視化にまとめるのは難しい
様々なテクノロジーが手軽に利用可能になると、一つの図にできるだけ多くの情報を盛り込んだ凝った可視化を作りたい誘惑に駆られますが、情報の詰め込み過ぎは殆どの場合悪い方向に働きます。これは何もデータ可視化に限ったことではなく、様々な場面において正しいです。皆さんも技術系のカンファレンスや学会などに参加されることがあると思いますが、しばしば箇条書きの文章でびっしり埋まったスライドを使う方を見かけると思います。伝えたいことがたくさんあるのは分かるのですが、多くの場合それは眠気を誘って終わります。データ可視化でも同じで、大量の情報を一画面・一枚の紙で表現するのは難易度が高い作業です。
中にはこの難しい作業をうまく乗り越えた例もあります。とても有名なデータ可視化にCharles Minardによる「ナポレオンのロシア行軍」があります:

Carte figurative des pertes successives en hommes de l'Armée Française dans la campagne de Russie 1812-1813. (Charles Minard's 1869 chart showing the number of men in Napoleon’s 1812 Russian campaign army, their movements, as well as the temperature they encountered on the return path.)
この可視化の歴史的背景はこちらでどうぞ:
- 1812年ロシア戦役 - ナポレオンが没落するきっかけになったモスクワへの進軍。冬季の無謀な行軍により、フランス帝国軍のほとんどが寒さと飢えで死滅した
これはたった一枚の画像の中に、これだけの情報を詰め込んでいます:
- 時間
- 兵士の数
- 地理的な場所 (二軸。緯度と経度)
- 気温
- 進軍方向
これだけ大量の情報を詰め込んでも破綻せずに、ちゃんとこの図のテーマである「無謀な進軍による兵士たちの悲惨な運命」を描くことに成功しています(つまりこの可視化は、一種の反戦ポスターでもあると解釈されています)。先に触れたタフテもいたく気に入っているようで、これを元にしたポスターまで売っています。
この作品ですが、ありとあらゆるデータ可視化の専門書に載っていると言っていいほど様々なところで目にします。__この図がそこまで賞賛されるのも、多くの情報をテーマ性を失わずにうまくまとめた稀有な例で、いつもこのようなものが出来るとは限らないから__だということにほかならないと思います。見やすさを損なわすに異質なデータを二次元に封じ込めるのはとても難易度の高い作業です。一枚の画像に様々な情報を盛り込みコンパクトに情報をまとめるのはエレガントで皆そこを目指すのですが、それが難しい場合は無理をせず、テーマ/ポイント/仮説ごとに一つの可視化(ダイアグラム)を使い、それぞれのポイントがしっかり伝わるのを目指すのもひとつの手です。特にこれはD3.jsなどを利用したカスタム可視化を作成する場合に顕著ですが、カスタムコードを使えばいくらでも複雑な可視化が作成できます。ついつい一画面に大量の情報を盛り込んで、複雑だけどなんとなくカッコイイ物を作りたくなる誘惑に駆られますが、なんとかそれに抗い、「伝わりやすさ」を最優先して下さい。
まとめ
- 異質な情報を一つの可視化で表現するのは本質的に難しい作業だと理解する
- エレガントさは大切だが、それよりも伝わりやすさを再優先する
「可視化の文法」を学ぶ
可視化には基本的文法とも呼べる概念が存在します。究極的には可視化とは線や点の集合に過ぎませんが、それらを一定の意味を持つユニットまで分解していくと、それらで表される概念はある程度共有されていることに気づくと思います。ここでは矢印という一般的なシンボルを例に、いかに直感的な表現方法から外れることなくそれを正しく使うか、を考えてみます。
可視化の中での矢印
以下の図は、昔ニューヨークの現代美術館 (MoMA)で開催された展覧会のパンフレットで使われた図です:
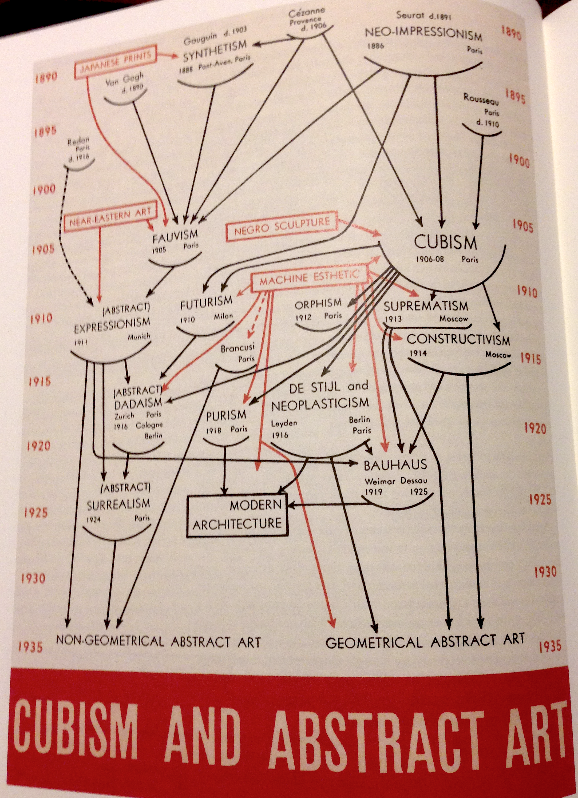
[Tufte 2006 p64. オリジナルはAlfred H. Barr, Jr. Cubism and Abstract Art (New York, 1936)]
この図は、浮世絵からゴッホなどのポスト印象派への影響から、キュビズムやバウハウスなどの影響を経てモンドリアンやカンディンスキー等の抽象絵画へ至る歴史を、最近ではよく見られるジャンルごとの影響を示したグラフ構造として表現したものです。ここには2つのデータが可視化されています:
- 1890年代から1935年までの時間の流れ
- 各芸術運動の相関
左右に振られた数字で、上から下への時の流れはとても自然に表現できますが、どの芸術運動が次のどの運動に影響を与えたかという点に関しては、矢印を使ってそれが表現されています。これは我々にとってとても自然な表現で、矢印で接続された2つのノードの関係性はとても明確です。つまり我々の文化圏(そして恐らくほとんどの地球上の文化圏)では、__矢印で表現されるべき概念は因果律 (causality)__ということになります。従ってこの「文法」から外れた使い方をすれば、不要な混乱を生み出しそれはストーリーを語る上で大きなマイナスに働きます。
もう一つ例を見てみましょう:
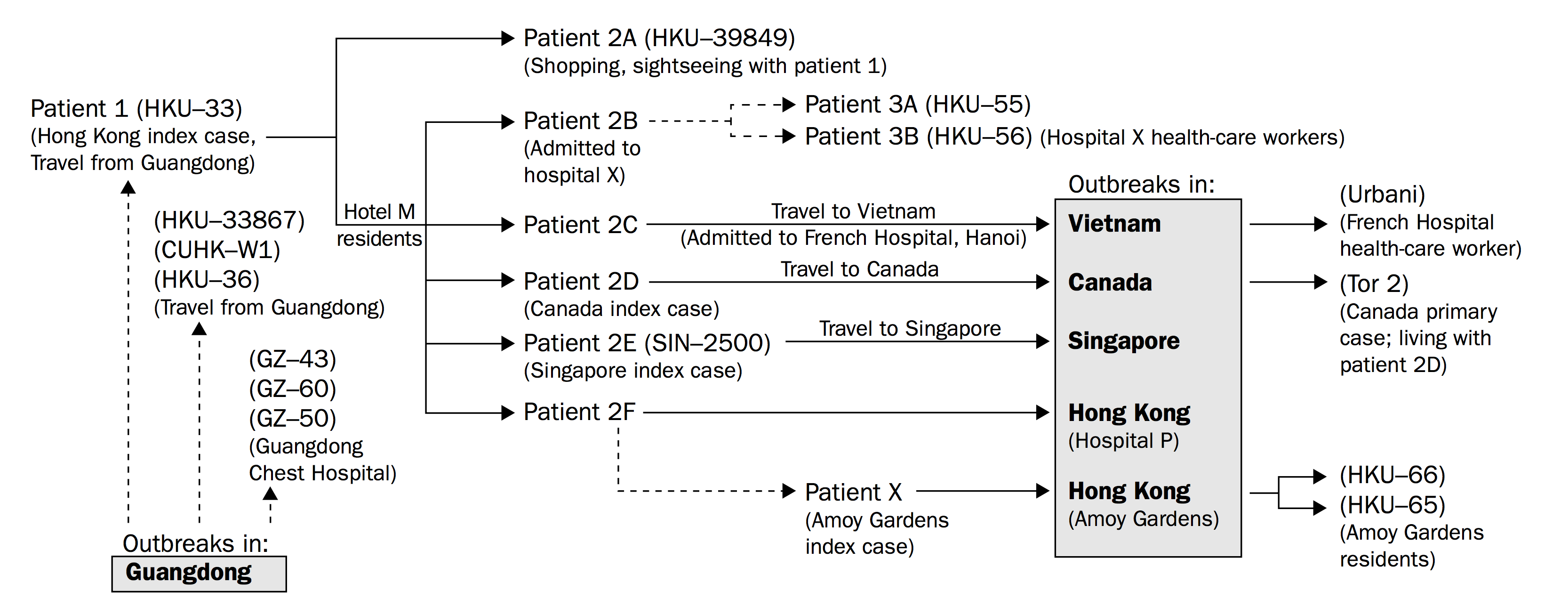
Guan Y, Peiris JS, Zheng B, Poon LL, Chan KH, Zeng FY, Chan CW, Chan MN, Chen JD, Chow KY, Hon CC, Hui KH, Li J, Li VY, Wang Y, Leung SW, Yuen KY, Leung FC. Molecular epidemiology of the novel coronavirus that causes severe acute respiratory syndrome. Lancet. 2004 Jan 10;363(9403):99-104. PubMed PMID: 14726162.
これもタフテがレクチャーで好んで使っている例です。SARSウイルスの拡散を時系列で追ったものですが、矢印を追うことにより拡散の様子を時間で追うことが出来る上に、各地域のアウトブレイクが発生した原因が明解に語られています。このように、各シンボルを広く使われている文法に則り使うことにより、語るべきポイントが明確になります。タフテはレクチャーの中で、しばしば矢印が可視化の中で因果律以外の意味で使われていることを批判していました。
現実のプロジェクトでも、これらの基本的文法はちゃんと用いられています。
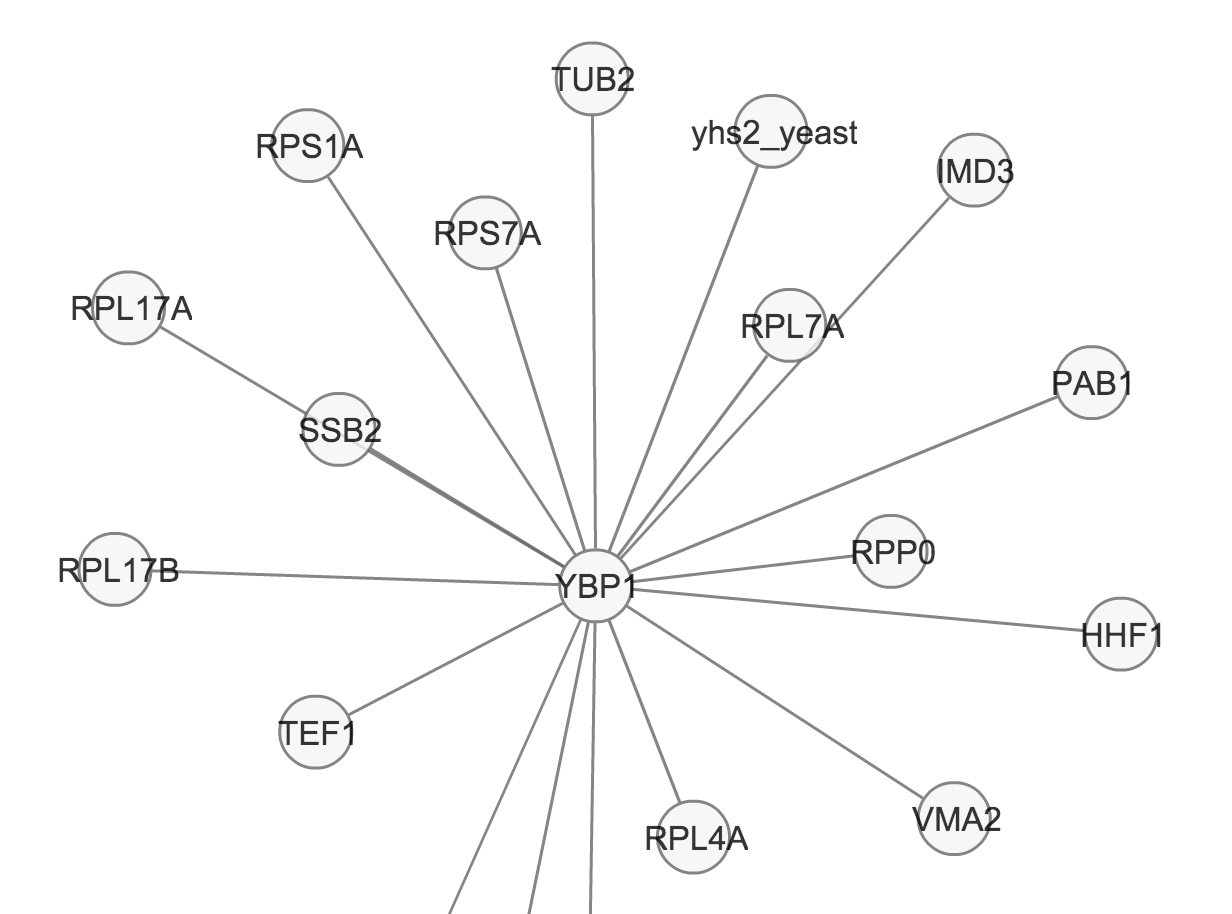
無向グラフ
- タンパク質間相互作用ネットワーク - 方向性は重要ではないので矢印は用いない
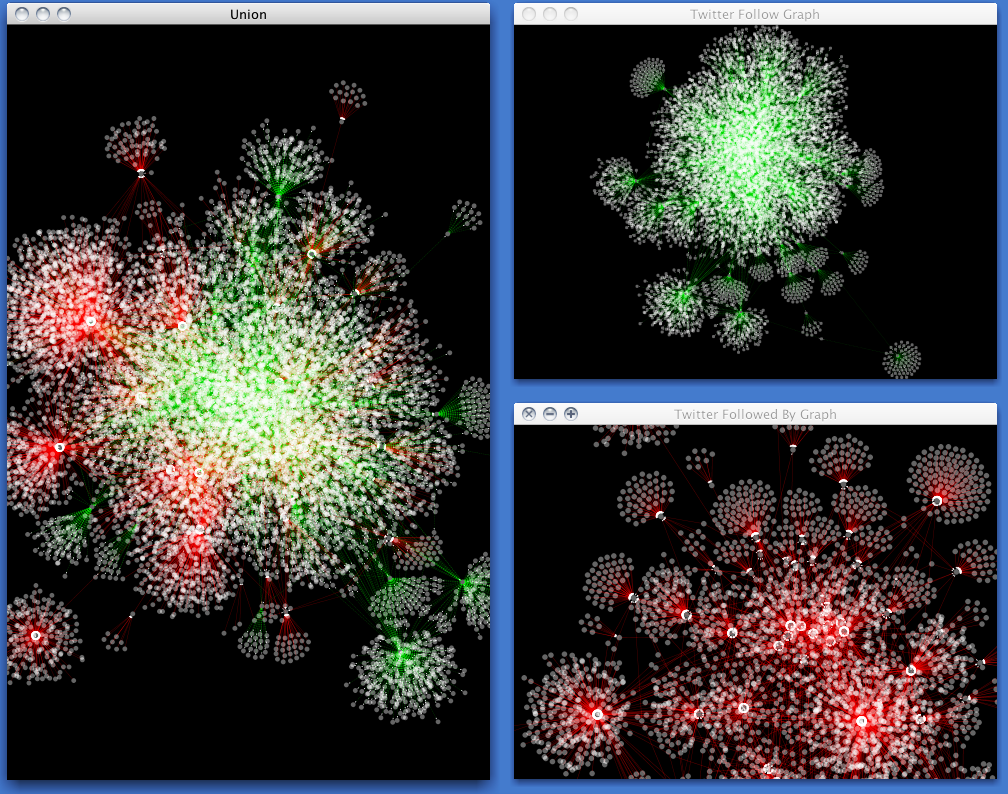
有向グラフ
- Twitterのフォロー(非対称のネットワーク)- フォロー数・フォロワー数にはそれぞれ別別の方向性があるため、異なるタイプのエッジを矢印で示す
まとめ
- 各シンボルを一般に受け入れられている意味で使う
- 基本的な「可視化の文法」を学ぶ
余談
芸術や音楽のジャンルを可視化するというのは多くの人が行っています。様々な表現方法があるので、興味のある方は以下を参考にしてみてください:
検索問題として可視化を捉える
これは最近Mike Bostockが好んで使っている言葉ですが、良い表現だと思うので紹介します:
デザイン(可視化)が難しいのは、良い可視化(ゴール。もちろん複数存在する)はあるのですが、そこに至る経路は無限にあることです。ですからいかに不要な脇道に深入りせず、効率よくゴールに向かうか、と言う技術が実際に手を動かす我々には必要になってきます。ここまでに述べた基本的な知識は、この可視化と言うプロセスで我々が脳内で行う不要な枝を刈り取る技術にほかなりません。バックグラウンドの知識があればあるだけ、この検索問題を有利に進めることが出来ます。可視化がコンピュータベースになったということは、そのプロセスをコード化し、それにGit等のバージョン管理システムを組み合わせることにより、可視化結果と過程を同時に辿れる事を意味します。紙上の可視化だと、結果を見ることは出来ても、過程は再現できません。これは計算機ベースの可視化の巨大なアドバンテージです。プログラマーの皆さんも、デザイナーの皆さんもぜひコードを基板とした可視化のこのメリットを活かし、自分の過去に行った過程から学んでさらなる効率化を目指して下さい。
まとめ
- データ可視化とは「テーマを雄弁に語る可視化」と言うゴールに向かって無数のサーチスペースを検索する検索問題のようなものである
- 可視化の基礎を学ぶことは、この迷路を有利に進むことが出来る技術を学ぶことにほかならない
更に学ぶ
ここまでに書いたことは、専門家ではない自分が経験や読書などで得た知識の一部です。つまり普通に手に入る情報や本でこの分野はある程度まで独学できます。プログラマーがこの先さらに学ぶためのポインタを幾つか示したいと思います。
英語を学ぶ
いきなりやる気を無くすアドバイスで申し訳ないのですが、プログラミング一般の話題と同じく、実務方面の可視化に関する最新の話題は、ほぼ全ての一次情報が英語で書かれています。日本語の紹介記事を待ってもいいのですが、そうするとかなりのタイムラグがあるか、そもそも日本語には訳されない情報が多すぎます。ここは素直に諦めて「必要な情報が理解できる程度の英語力」を目指しましょう。私も英語が苦手だった(今も?)人間ですが、必要に迫られればなんとかなるものです。__技術系の英文は、専門性が上がれば上がるほど英語としての難易度は下がる傾向があります__ので、是非挑戦してみてください。
サイトをざっと眺めて、そのツールが何をするものかがぼんやり分かるくらいの英語力があれば、その先の詳細ドキュメントや参考文献は必要に応じてゆっくり読んでいけばいいのですから、その辺りを最初のゴールとすれば良いのではないでしょうか。
本を読む
やはり独学の場合は読書が学習の中心になると思います。可視化関連の本は、可視化そのものを研究する方々に向けた本と、その研究成果を実際のプロジェクトで使う人々(実務家)向けの本にわかれます。前者は多くの場合高価な英語の専門書や、学会発表の論文という形で発表されています。 ここでは後者に属するものを中心に、私が実際に読んだり、少なくとも中身を拾い読みしたことのある本で良いと思ったものをあげます。
古典
ここでは古くなりにくい根本的な概念や基本的ルールを論じた本を紹介します。残念ながら訳書は一つもありませんので、原著でどうぞ。
Semiology of Graphics by Jacques Bertin

前編で紹介したVisual Variablesの概念を作ったJacques Bertinによる著作で、原著のフランス語版は1967年の出版です。暫く英訳版は手に入りにくかったようですが、現在は2010年にアップデートされた版がAmazonなどで入手できます。未だにこの分野の古典として読み継がれているようです。もちろんコンピューターが普及する前の時代の本ですから、純粋に情報とその表現について論じています。この分野の原点とも言える本ですので、一度手にとってみても損はないと思います。
E.タフテの著作

- The Visual Display of Quantitative Information
- Envisioning Information
- Visual Explanations: Images and Quantities, Evidence and Narrative
- Beautiful Evidence
この記事の前半でたくさん取り上げましたタフテの著作です。現在までに四冊の本を出しており、どれも技術詳細から独立した基本原則を学ぶのにはとても良い本だと思います。特に_The Visual Display of Quantitative Information_は古典中の古典とも言える本なので、一度お読みになることをおすすめします。現在は第二版が出ています。
彼はYale大学の教授として研究や教育を行う一方、自ら会社を立ち上げ出版と講演のビジネスとしています。この会社を立ち上げた目的の一つが、上記の四冊に自分の気にいる紙質と装丁を実現するためだったそうですからかなり徹底しています。彼は会社のビジネスとして、全米の各都市で一般向けの可視化やプレゼンテーションに関する二種類のレクチャーを行っています。一つは彼の今までの研究に基づいた、一般向けの一日集中講義で、いかにしてデータから効果的な文章や可視化を作成するかという基本的な考え方をレクチャーします。
もう一つは、可視化分野の著名な実務家(実際にジャーナリズムやソフトウェアの世界でデータ可視化を行っている人々)を招き、タフテを含む四人が_See, Think, Design, Produce_と言うキーワードに基づきレクチャーを行うスタイルのものです。タフテ以外の三人は、開催時期によりメンバーが入れ替わるようですが、私が参加した時は、Mike Bostock (D3.js/NYT)、Jonathan Corum (NYT)、Bret Victor (UX Designer/ Programmer)の三人でした。
両方のレクチャーに参加した感想ですが、前者は長く使える基本的な知識/原則を学ぶのにとてもいい講義で、後者は実際の現場で働く人々の実プロジェクトから得た経験に基づくノウハウの伝授(といっても技術詳細ではなく、基本原則の応用や作業の流れといった長く使える知識)と言った感じで、どちらも有益でした。アメリカ出張/旅行と重なる事があれば、ぜひ参加してみて下さい。ただしタフテはアメリカのインテリらしく、洗練された英語表現を好む方なので、完全に理解するにはかなりのリスニング力が必要です。
The Grammar of Graphics by Leland Wilkinson
計算機をベースにする可視化をやろうとしている人、特にバーチャートなどの一般的なものを超えた、カスタマイズされた可視化を作成しようとしている人には必読書です。カスタマイズされた可視化手法と言っても、多くの場合既存の手法の拡張であることが多いため、この本で述べられている基本的な事を理解して上でシステムを設計するのが好ましいからです。タフテの著書が紙を念頭においた一般論が多いのに対して、こちらはコンピュータベースの可視化にフォーカスしています。可視化ソフトウェアが従うべき基本的な設計方針や、それを構築するためのbuilding blockを「文法」という皆に馴染みのある概念を使って分類し、まとめています。
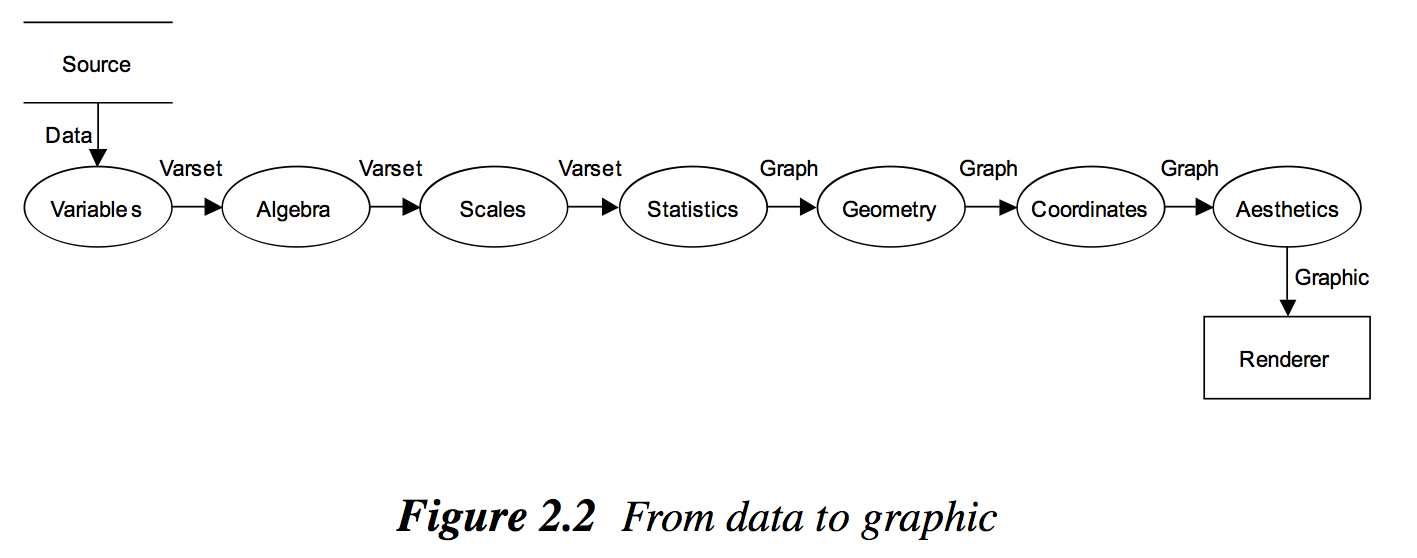
この本は大きく2つのセクションにわかれています。
- Syntax
- Semantics
Syntaxのセクションでは文法、すなわちデータや変数、関数、やスケールと言った、可視化を構成する要素を解説し、Semanticsのセクションでは、それら構成要素を使って実際の文章(すなわち可視化)を構築するときに必要となる時間や空間、不確実性といったもう一つ上のレイヤの話題を扱っています。英語で700ページ近い大著で、自分もしっかり読み込めていないのでもう一度細部まで読み込んで勉強したい本です。因みにRにおける著名可視化ライブラリであるggplot2は、この本に書いてある概念をベースにして作られています (ggplot2 = Grammar of Graphics Plot 2)。
また著者は違いますが、関連の話題として我々プログラマにとっては馴染み深いデザインパターンを拡張した、「可視化のためのデザインパターン」も考案されていますので、このエリアに興味のある方はどうぞ:
教科書
Visual Insights: A Practical Guide to Making Sense of Data by Katy Börner

この本は、以下の可視化のオンラインコースで教科書として使われたものです:
- Information Visualization MOOC by Indiana University
元々教科書として書かれたものですから、実際のツールを使いながら学んでみたいという方にはお薦めです。ただ利用しているツールは彼女のラボで開発されたものが中心ですので、若干マイナーなものも含みます。少々話題が脱線しますが、彼女のラボは各種ツールの開発も積極的に行っており、我々のプロジェクトでも採用しているOSGiと言うJavaのモジュラリティを実現する技術があるのですが、それを我々に紹介して最初の頃技術協力してくれたのも彼女のラボです。
マクロスコープ (Macroscopes)
余談ですが、彼女は__マクロスコープ__という造語を使ってモダンな可視化システムの進むべき方向性を定義しています。遠くの極大の世界を見る望遠鏡 (telescope)、極小の世界を覗く顕微鏡 (microscope)と言う二つのものに続く第三のツールとして、目には見えないデータや概念といったものを見えるようにする計算機上に構築されたデータ可視化システムを、データに対する巨視的な視座を与えるということでマクロスコープと呼んでいます。
- Katy Börner. Plug-and-Play Macroscopes. Communications of the ACM, Vol. 54 No. 3, Pages 60-69
10.1145/1897852.1897871
Macroscopes provide a "vision of the whole," helping us "synthesize" the related elements and detect patterns, trends, and outliers while granting access to myriad details.
(マクロスコープは「全体を見渡す視点」を(ユーザーに)提供する。つまり関連する要素を「作り出す」事を手助けし、そしてパターン、傾向、概要といったものを発見し、同時に無数にある詳細へのアクセスを常に保証する。)
こういったものを実現するのに、一つの研究機関で全てのツールを賄うのはとても無理ですから、様々なツールを組み合わせるのに便利な技術の一つとしてOSGiを推奨しています。OSGiはJavaランタイム上でのモジュラリティを保証する技術ですが、巨大なデータセットが続出している現在では、更なるスケーラビリティを目指してService Oriented Architecture (SOA)などと呼ばれる分散・独立したサービスを疎に結合して大きなワークフローを構築する設計手法も必要になってくるでしょう。
Visualization Analysis and Design by Tamara Munzner

まだ発売前なのですが、ドラフト段階のものをざっと眺めた感想です(恐らくそれよりも製本版は良くなっているはずなので、来月届いたらちゃんと精読してみます)。この本は彼女が大学で行ってきたレクチャーや、様々なカンファレンスでの講演を元にした集大成で、最初から教科書を意図して書かれているため、独学にも向いていると思います。彼女には我々のプロジェクトの科学アドバイザーになってもらっていますが、講演や授業のスライドを積極的に公開していて、私も色々と勉強させてもらっています。この本は情報も新しく、これからこの分野を学ぶ方にはお薦めです。出版社の方、多分日本語版出せば売れますよ(笑)。
日本語の本
多くはないですが、最近増えつつあります(訳書は日本語版を読んでいないものもあるので、訳の質は考慮に入れていません)。
ビューティフルビジュアライゼーション (Beautiful Visualization)
この本は、教科書的に入門から基礎知識・応用と言う形には編集されていません。可視化分野のエキスパートが、自らの実プロジェクトでの経験やそれに関する考察をエッセイとしてまとめたものです。各章は独立していてどこから読み始めて良いのですが、基本的には応用事例集なので、最初に読む本と言うよりは、教科書的なものを読んだあとに興味のある話題を拾い読みしていく、と言うのが良いと思います。これはソフトウェアに関する書籍であるかぎりしかたがないのですが、扱っている内容そのものは今でも価値が有る一方、各ケーススタディの中で使われているツール類は結構古くなっています。今ならもっと便利なツールも存在する場合が多いので、実践に移るときには一度最新のツールに関する話題をチェックしたほうが良いと思います。
ちなみにこの本の14章では、我々が作っているCytoscapeと言うツールを利用して作られた図が多用されています。実プロジェクトで使われている例として、興味のある方はご覧になってみてください:

ビジュアライジング・データ ―― Processingによる情報視覚化手法 (Visualizing Data)
Processingの作者であるBen Fryによる著書です。Processingを使ったデータ可視化の実践的手法が、様々なデータセットを使って紹介されています。Processingを使ったデータ可視化入門としては一番のお薦めです。
データ可視化ツールとしてのProcessingについて
数年前なら、Processingは間違いなくカスタム可視化を制作するベースとしてお薦めでした。が、最近は必ずしもそうとはいえなくなってきています。多くの可視化関連ライブラリがブラウザをターゲットにするようになり、最新の話題の多くはweb系の技術に偏ってきています。Processingは素晴らしいツールで、Processing 2となった現在も活発に開発されています。もともとProcessingはメディアアート系の方々が盛んに使っていたツールで、表現の自由度が非常に高い一方、何かを作ろうと思えば、基本的にI/Oなどのローレベルな処理を除いて自前で書くことになります。ですから現在では、非常に高度なことを行いたい場合以外はプリセットである程度まで作り込めるツールを選択するのも一つの方法です。逆にProcessingでもパフォーマンスが足りないような高度なものを作る場合は、CinderやOpenFrameworksと言ったC++ベースのライブラリを使うのがよいでしょう。この辺りのノウハウはメディアアート系の方々が蓄積していて、日本でもエヴァンジェリスト的な方々がいらっしゃいますので、データアートに近い可視化を行いたい場合は、そういったコミュニティを覗いてみることをおすすめします。
エンジニアのためのデータ可視化[実践]入門 ― D3.jsによるWebの可視化
日本語では珍しく、そのもののタイトルだったので電子版で買ってみました。Amazonの評価はかなり分かれていますが、D3.jsの入門書として考えなければとてもいい本だと思います。マーケティングの都合上このようなタイトルになったのだと思いますが、それでかなり損をしていると思いました。この本の価値はD3.jsを使って手を動かすパートではなく、私がこの記事で書いたような、プログラミングを行って可視化を作る以前の基礎知識にあります。その辺りをもっと日本語で読みたい方にはお薦めです。視覚変数やその正しいマッピング方法などについて、私の記事よりずっと詳しく解説してあります。
インタラクティブ・データビジュアライゼーション ―― D3.jsによるデータの可視化
逆にデザイナーの方などが、非常に基礎的な部分からD3.jsを学びたい場合の入門書としては、こちらをお薦めします。HTMLとは何か、辺りから説明してありますので、プログラミング経験の無い方にもわかると思います。非JSプログラマがD3.jsを学ぶ時にネックになるのは、JavaScriptの関数型の側面を強調したプログラミングスタイルとセレクションの部分にあると思いますので、その辺りをしっかり知りたい方には良い本です。ただし対象読者が初心者であるため、経験のあるプログラマの方には物足りないかもしれません。
実装技術を学ぶ
ここまでは、どちらかと言うと実装よりも、もう一つ上のレイヤの話題が中心でしたが、カスタマイズされた可視化を作成する場合、最終的には何らかのツールを使って行うことになります。あまり深くは述べませんが、私が最近追っている情報から判断した重要と思われる関連技術を集めてみました。
JavaScript
先にも述べましたが、一部の特殊事例を除き、最近の可視化ツールの多くがブラウザ上に移行しています。従って最新の話題、技術に追随しようと思うとJavaScriptを学ぶことは避けようがありません。JSは初学者がとても簡単に始められて、とても簡単にメンテナンス不能なコードを生成するのに最適化されています(?)。特に、カスタムの可視化アプリケーションはコード量が大きくなりがちなので、基礎を学んだ上で、ある程度大きなコードになったら下で述べるクライアントサイドフレームワークの併用も検討して下さい。
クライアントサイドフレームワーク
最近は、事実上3つほどに集約されています。
- AngularJS
- Ember.js
- Backbone.js
これらに関しては大量の比較記事が書かれていますのでここでは書きませんが、現在はAngularJSが頭ひとつ抜けた人気を得ているようで、関連情報な入手しやすいです。MEAN(MongoDB, Express, AngularJS, Node.js)と言う言葉が生まれるほど、素早く全てをJavaScriptで完結するときに標準的なスタックとなりつつあるようです。
Web Components
高度な可視化アプリケーション(ここではブラウザ上のSPAを想定しています)を設計する時場合、UIは複数の独立したコンポーネントの集合となる場合が多いです。JSが生まれた頃は当然こんなユースケースは想定されておらず、最近の複雑なアプリケーションはある意味無理やり現在のテクノロジーで一定のモジュラリティを持つUXを設計しようとしています。これを標準化された技術で根本的に解決しようとする動きもあり、その一つがWeb Componentsです。これも様々な解説記事があるのでそちらを参考にしていただくとして、個人的にはこれが早く普及してほしいと願っています。いくつかのカンファレンスに参加して得た印象としては、GoogleとMozillaはかなりこれに積極的なようです。まだ未来のテクノロジーですが、Polymerのpolyfillですぐに体験することが出来ますので興味のある方は是非挑戦して下さい。
Python
データ可視化は常にデータから始まりますが、いつもきれいなデータが手に入るとは限りません。それを掃除したり加工したりするのにぴったりな言語です。ただしこれはあくまで個人の好みなので、他の言語でも出来ます。また定型の可視化ならば、これだけで完結させることも可能です。
R
独特な文法でとっつきにくいですが、極めて高レベル(=抽象度が高い)な統計に関するライブラリが用意されていますので、少ないコードでかなり複雑な統計処理が出来ます。可視化も(スタティックなものが中心ですが)含まれていますので、定型ならばこれだけで完結することも考えて下さい。
D3.js
この手の話題では必ず出てくるライブラリです。直接レンダリング部分は持っていないのですが、基本的にSVGとして描画する時にもっとも力を発揮します。大量の文献が出回っていますので、英文の電子書籍を購入するか、本屋さんで日本語の本を実際に手にとってみて下さい。
WebGL
私がこの記事の読者として想定しているのは、三次元を必要とするシミュレーションやエンジニアリング系の可視化ではなく、各種統計データ、地理データ、グラフデータなどの比較的ビジネスや報道などの世界でもよく用いられる方面を想定しています。これらの分野では、3Dがどうしても必要になる場面は意外と少ないので、3Dグラフィックスに関して私は素人同然ですが、これから学ぶことがあるとすればこの周辺になると思います。全般的に言えることですが、パフォーマンスを優先で実装するより、まず正しく実装することを最初に考えて下さい。上であげたような技術で足りない場合、WebGLはその時初めて検討すべき技術だと思います。繰り返しになりますが、3Dを使う場合は必ずその必要性を先に検討して下さい。可視化の専門家は「3Dのための3D」に対して批判的な人も多いです。
ツールの未来
定番化した表現手法(バーチャート、ラインチャート、ボックスプロット、散布図等)に関しては、自前で何か新しいものを作るというのは極力避けたほうが良いと思います。それは、もう既に使い切れないほどの大量の可視化ツールキットが対応しているからです。ではまだ残っている分野は何かと考えると、やはり既存の手法を踏襲しつつも、それらを組み合わせたりした高度にカスタマイズされた可視化だと思います。もちろんこれは比較的ローレベルなツールキット(D3.jsやp5.js等)を使えばコードとして表現できますが、ExcelやTableauのような使い心地でこういったものが作れるようにならないか研究している人も居ます。
Lyra by UW Interactive Data Lab
これはまだアルファバージョンのプロジェクトですが、D3.jsを生み出したJ. Herr教授のラボの学生が作ったものです。既存の手法やツールだけでは表現の難しい可視化を、GUIからプログラマでない人も作れるようにしようというプロジェクトです。
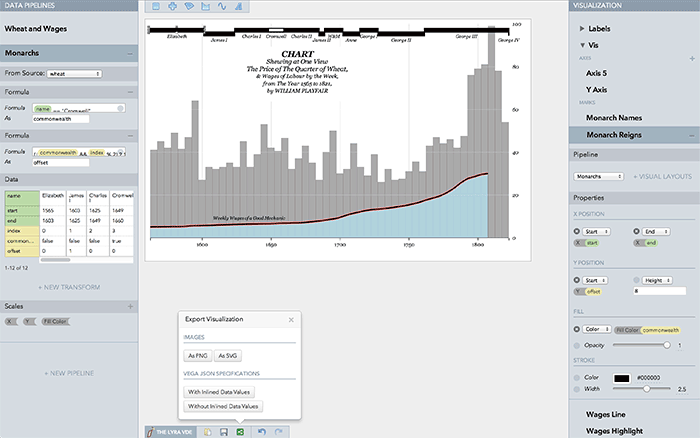
このツールの表現力のデモとして、先に紹介した「1812年ロシア戦役」の可視化を再現しています:
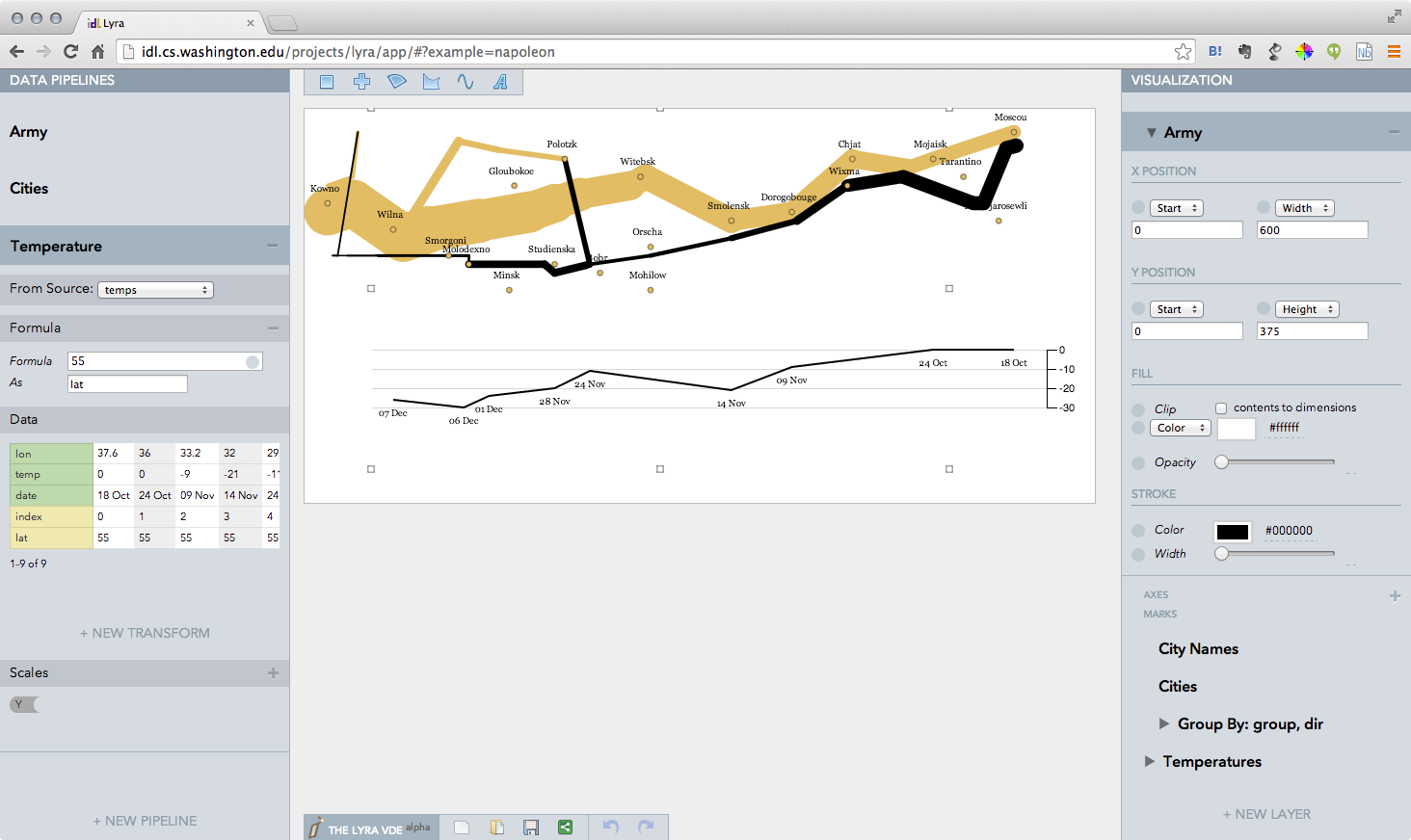
作者の講演を聞いたことがあるのですが、「Excelなどのアプリケーションと、D3.jsなどのプログラマ向けのツールキットの間くらいを目指している」とのことでした。技術的にはNode.js上に構築されたブラウザで実行するアプリケーションですから、興味のあるJavaScriptプログラマの方は、GitHubで中身をご覧になってみてください。まだまだ若いプロジェクトでどの程度実用性が上がってくるのかはまだ未知数ですが、可視化そのものを研究している人々の間では、こういった動きもあると覚えておくのがいいでしょう。
可視化に関するニュースを追う
日々新しい技術や作品が生み出される最もハードコアな情報(可視化技術そのものやアルゴリズムの開発)を追うには、当然IEEE等の学会誌やカンファレンス向けの論文を読むのが最も近道ですが、これはさすがに難易度が高いと思われる方が多いはずです。日本にもたくさんの可視化の専門家の方々はいらっしゃるので、そういった方々向けの学会は当然あります。しかし、専門家の方々が作り上げた理論や技術体系を使って、実際の可視化を作成する人々が何かを作ろうと思った時のノウハウが共有が出来る場所はまだ少ないです。英語圏ではたくさんのpractitioner(実際に手を動かして可視化を作る人々)がブログなどで情報発信をしているので、興味のあるものを購読してみてください。先日ちょうどそういった方々をまとめたリンク集を発見しましたので、この辺りを手がかりに探すと良いでしょう。
学会やカンファレンスに参加する
学術的な研究も実務者向けの情報も、最新の動向にはカンファレンスや学会で触れることが出来ます。我々はプログラマーなのですから、どちらかと言うとそこに解決すべき課題があり、コードとしてそれを実装する技術に目が行きがちですが、それに加えてもう少しメタな話題を含めたカンファレンスなども増えてきています。ここで言うメタな話題とは、可視化全般に関する原理原則の議論や、データ駆動型ジャーナリズムなどへの応用も含みます。
以下にいくつか例をあげますが、残念ながら全てが欧米で行われています。
-
IEEE Vis
可視化の先端を研究する研究者向けの会議です。ここにあげてある中では最も専門性が高いです。今年はパリで行われます。 -
Visualized
こちらは技術系のカンファレンスでありながら、メタな話題も多いです。ニューヨークという土地柄、デザイナーの参加者も多いのが特徴です。 -
OpenVis
まだ今年始まったばかりのカンファレンスです。具体的な実装技術に寄った話題も多いので、プログラマの方には一番分かりやすいと思います。ちなみに今年のキーノートはMike Bostockでした。 -
Strata
データサイエンティスト向けの会議ですが、データ可視化トラックもあります。オライリーの主催するカンファレンスは、チュートリアルも含めた様子を全部録画して編集したものを販売しています。行けない方は会社のボスに頼んで、このビデオを経費で購入してもらいましょう。もちろん英語ですが、必要に応じて巻き戻しながら見ればなんとかなると思います。
分野特化型の会議
根本的な可視化の基礎知識はほとんどの分野で共通ですが、実際に作成に使われる技術は扱うデータによってかなり異なります。例えば、生物分野に限っても、タンパク質立体構造可視化をやっている人と、我々のようにタンパク質間相互ネットワークやパスウェイ解析をやっている人では扱うデータも技術もかなり異なります。全く異なった分野であれば、更に差異は広がります。こういったギャップのために、より限定されたトピックでの可視化について専門のカンファレンスもあります。以下は生物学分野に限ったものですが、他にも色々とあります:
日本では?
当然日本でも専門家向けの学会はありますが、実際に手を動かすデザイナーやプログラマー向けというのは寡聞にして知りません。日本でもそういったMeetupやカンファレンスが定期的に開催されるといいのですが、まだそういった動きは始まったばかりのようです。これまた手前味噌ですが、微力ながら私もそういったグループのオーガナイザーとして参加させてもらっているので、興味のある方はどうぞ:
- Data Visualization Japan (申し訳ないですがFBグループなので、登録が必要になります)
- 第一回meetupもまもなく開催されます。
美術館に行く

Piet Mondrian Broadway Boogie Woogie (1942-43) MoMA NY 2014年2月 K.O.撮影
ありきたりの意見ですが、コンピュータから離れて外に刺激を求めるのも良い勉強になります。アートとデータ可視化は似て非なるものですが、芸術から学べることもたくさんあります。我々プログラマーは芸術作品を作るわけではないのですが、盗めるところはどんどん盗みましょう。日本語に訳しにくいのですが、可視化分野の人々は__aesthetic__と言う言葉を使って、数値化の難しい全体的な美しさに関わる部分を分類します。あくまでデータ可視化ではこれまで述べてきたようなデータを中心とした変換のテクニックが中心になりますが、それを補完し最終的な仕上がりを左右する要素としてaestheticも重要な要素です。これは言語化の難しい点でもあるので、私もこうだ、と言う学習方法は思いつきません。だからこそ、こういう一見非効率だと思えることも必要なのかな、と思っています。個人的に足を運んだことがある好きな美術館は、近現代の代表作をまるでカタログのように現物で観られるNYのMoMAとカンディンスキー作品の充実したグッケンハイム、ナチスの迫害によりNYにモダンアートの拠点が移るまでの作品が充実したパリのポンピドーセンターですが、日本も含めて世界中には素晴らしい美術館がたくさんありますので、自分の足でお気に入りを見つけて下さい。古代や中世の様々な美術品があるロンドンの大英博物館やナショナルミュージアム、パリのルーブルなども実際に行ってみると素晴らしいと思うのですが、我々の生きている時代と離れすぎていることもあり、美しさの基準が色々と移り変わっているため、「分かりやすい」近現代美術に比べると深い理解にはより時間をかけて見たり調べたりすることが必要だと感じました。
いいな、と思ったものがあれば、そこから盗めるエッセンスはなにか考えるのが良いと思います。逆に不快なものがあれば、その感情を呼び起こす原因に向きあうことにより、これもまた役立つ知識となるはずです。
おわりに
この記事は、本来なら本にすべきようなトピックを無理やり小さな記事内で列挙したため説明不足な点も多くありますが、プログラマーの皆さんがこの分野に足を踏み入れる手助けになれば幸いです。繰り返しになりますが、私は可視化分野をちゃんと大学や大学院で勉強したことのない一介のプログラマーですから、専門家の方から見るとおかしなところ、説明不足なところがたくさんあると思います。コメントや修正した方がいいなどのリクエストは大歓迎ですので、よろしくお願いします。
今後の記事のリクエストなどもあればぜひお知らせ下さい。書ききれなかったことも山のようにありますので、また機会があればまとめてみたいと思います。日本でもこの分野に(実際にコードを書く)沢山の人々が参入するのを願っています。
Keiichiro Ono
Cytoscape Consortium Core Developer
National Resource for Network Biology