ざっくり言うと
- Convolutional Neural Networks(CNN)を使ってテキスト分類をする。
- Convolutional Neural Networks for Sentence ClassificationをChainerで実装した。
- 【Chainer】畳み込みニューラルネットワークによる文書分類 よりも高い正解率でテキスト分類できた。
はじめに
以前投稿した【Chainer】畳み込みニューラルネットワークによる文書分類の続きとして、EMNLP2014で発表されたConvolutional Neural Networks for Sentence ClassificationをChainerで実装しました。
著者のGitHubでもTheanoを使った実装が公開されています。
今回開発したソースコードはこちらで公開しています:chainer-cnnsc
使用したデータ
事前準備
- Chainer, scikit-learn, gensimのインストール
- word2vecの学習済みモデル( GoogleNews-vectors-negative300.bin.gz)のダウンロード.
環境
- Chainer
- Python 2.7系
学習データ
英語のテキストデータを使用します。
テキストデータは上記のダウンロード先から取得して下さい。
各行が1つの文書に対応しています。1列目がラベル、2列目以降がテキストです。
ラベルの0がネガティブ文書、1がポジティブ文書です。
[ラベル] [テキスト(半角スペース区切り)]
0 it just didn't mean much to me and played too skewed to ever get a hold on ( or be entertained by ) .
1 culkin , who's in virtually every scene , shines as a young man who uses sarcastic lies like a shield .
...
モデル
今回はこちらの論文(Convolutional Neural Networks for Sentence Classification)で提案されているモデルを使用しました。
こちらの記事にモデルの解説が載っています。
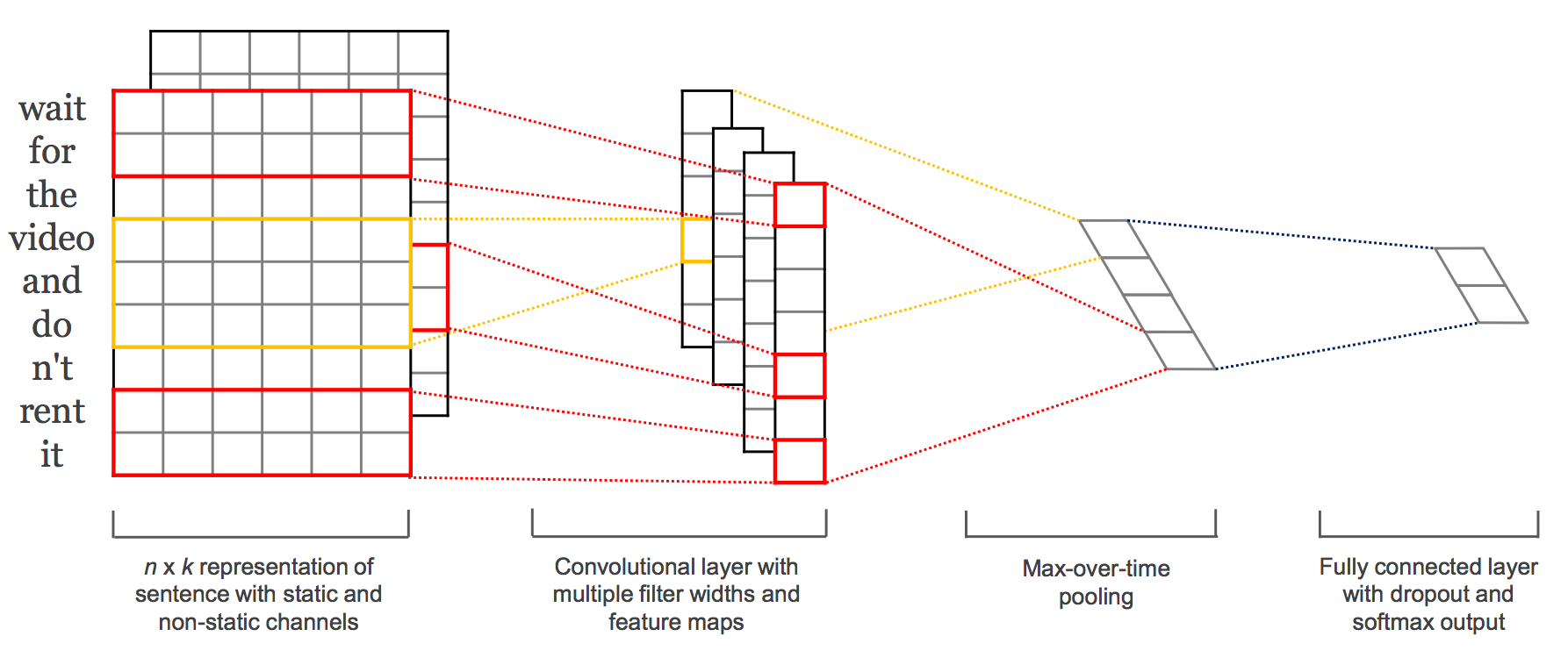
プログラム (ネットワーク部分)
プログラムでは、畳込み時のフィルタサイズを複数定義し、各フィルタごとに畳み込みを行います。
定義したフィルタサイズはfilter_heightにリスト形式で格納しています。
順伝搬には、以下のようにフィルタサイズごとにループを回して畳み込みを行います。
# フィルタ形毎にループを回す
for i, filter_size in enumerate(self.filter_height):
# Convolition層を通す
h_conv[i] = F.relu(self[i](x))
# Pooling層を通す
h_pool[i] = F.max_pooling_2d(h_conv[i], (self.max_sentence_len+1-filter_size))
以下にネットワーク部分のソースコードを示します。
# リンク数を可変にしたいのでChainListを使用する
class CNNSC(ChainList):
def __init__(self,
input_channel,
output_channel,
filter_height,
filter_width,
n_label,
max_sentence_len):
# フィルター数、使用されたフィルター高さ、最大文長は後から使う
self.cnv_num = len(filter_height)
self.filter_height = filter_height
self.max_sentence_len = max_sentence_len
# Convolution層用のLinkをフィルター毎に追加
# Convolution2D( 入力チャンネル数, 出力チャンネル数(形毎のフィルターの数), フィルターの形(タプル形式で), パディングサイズ )
link_list = [L.Convolution2D(input_channel, output_channel, (i, filter_width), pad=0) for i in filter_height]
# Dropoff用のLinkを追加
link_list += [L.Linear(output_channel * self.cnv_num, output_channel * self.cnv_num)]
# 出力層へのLinkを追加
link_list += [L.Linear(output_channel * self.cnv_num, n_label)]
# ここまで定義したLinkのリストを用いてクラスを初期化する
super(CNNSC, self).__init__(*link_list)
# ちなみに
# self.add_link(link)
# みたいにリンクを列挙して順々に追加していってもOKです
def __call__(self, x, train=True):
# フィルタを通した中間層を準備
h_conv = [None for _ in self.filter_height]
h_pool = [None for _ in self.filter_height]
# フィルタ形毎にループを回す
for i, filter_size in enumerate(self.filter_height):
# Convolition層を通す
h_conv[i] = F.relu(self[i](x))
# Pooling層を通す
h_pool[i] = F.max_pooling_2d(h_conv[i], (self.max_sentence_len+1-filter_size))
# Convolution+Poolingを行った結果を結合する
concat = F.concat(h_pool, axis=2)
# 結合した結果に対してDropoutをかける
h_l1 = F.dropout(F.tanh(self[self.cnv_num+0](concat)), ratio=0.5, train=train)
# Dropoutの結果を出力層まで圧縮する
y = self[self.cnv_num+1](h_l1)
return y
実験結果
実験では、データセットを学習データ、テストデータに分割し、50エポックを回して学習しました。
テストデータに対する正解率は50エポック目で、accuracy=0.799437701702となりました。
こちらの記事でよりシンプルなCNNを用いたモデルで文書分類をした時は、accuracy=0.775624996424だったので、わずかながら正解率が向上することが分かりました。
input file name: dataset/mr_input.dat
loading word2vec model...
height (max length of sentences): 59
width (size of wordembedding vecteor ): 300
epoch 1 / 50
train mean loss=0.568159639835, accuracy=0.707838237286
test mean loss=0.449375987053, accuracy=0.788191199303
epoch 2 / 50
train mean loss=0.422049582005, accuracy=0.806962668896
test mean loss=0.4778624475, accuracy=0.777881920338
epoch 3 / 50
train mean loss=0.329617649317, accuracy=0.859808206558
test mean loss=0.458206892014, accuracy=0.792877197266
epoch 4 / 50
train mean loss=0.240891501307, accuracy=0.90389829874
test mean loss=0.642955899239, accuracy=0.769447028637
...
epoch 47 / 50
train mean loss=0.000715514877811, accuracy=0.999791562557
test mean loss=0.910120248795, accuracy=0.799437701702
epoch 48 / 50
train mean loss=0.000716249051038, accuracy=0.999791562557
test mean loss=0.904825389385, accuracy=0.801312088966
epoch 49 / 50
train mean loss=0.000753249507397, accuracy=0.999791562557
test mean loss=0.900236129761, accuracy=0.799437701702
epoch 50 / 50
train mean loss=0.000729961204343, accuracy=0.999791562557
test mean loss=0.892229259014, accuracy=0.799437701702
おわりに
こちらの記事でもCNNを使ったテキスト分類の実装を紹介しています。