概要
書籍「実装 ディープラーニング」の三目並べサンプルをベースに、オセロゲームを自作して DQN(Experience Replay)強化学習を実施してみました。
今回は、スクリプトの紹介と、実行結果について考察を書いてみます。
ご意見や間違いのご指摘などありましたら、コメントいただければ幸いです。
コードはこちらにあります。
https://github.com/Kumapapa2012/Learning-Machine-Learning/tree/master/Reversi
後続の記事はこちら。
オセロ~「実装 ディープラーニング」の三目並べより(2)
http://qiita.com/Kumapapa2012/items/f6c654d7c789a074c69b
オセロ~「実装 ディープラーニング」の三目並べより(3)
http://qiita.com/Kumapapa2012/items/3cc20a75c745dc91e826
オセロ~「実装 ディープラーニング」の三目並べより(4)[終]
http://qiita.com/Kumapapa2012/items/9cec4e6d2c935d11f108
構成
スクリプト 4 つで構成されます。下記の エージェント、環境、実験を rl_glue で結合します。
エージェント(agent.py)
ビデオゲームではプレイヤーに当たります。Environment から情報を受け取り、強化学習によってアクションを決定し、環境に伝えます。より多くの報酬を得ることが目的になります。
環境(environment.py+game_reversi.py)
ビデオゲームそのものに当たります。エージェントのアクションに対して、応答するアクションを行いゲームの状態、報酬を与えます。エージェントはこれに勝つことで報酬を得ます。
二つのスクリプトを合わせて、環境を構成します。 environment.py がエージェントに対するインターフェースを提供し、game_reversi.py が、オセロゲームのロジックを実現します(ゲーム機本体と、カートリッジやディスクの関係と似ています)。
実験(experiment.py)
ビデオゲームではスタート、終了、スコアランキングなどを制御する部分にあたります。このスクリプトを実行することで、エージェントと環境が対戦を始めます。常にスコアを監視、記録し、既定の回数(本スクリプトでは 50000 エピソード)を完了すると、勝率をグラフに出力します。
実行環境
以下、使用した環境の情報です。
自宅マシンの構成:
AMD A10-7870K Radeon R7
Memory 32GB
Geforce GTX 1050 (玄人志向 GF-GTX1050-2GB/OC/SF)
仮想マシンの構成(Azure NV6):
Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz
Memory 56GB
Tesla M60 8GB
ソフトウェア構成(各マシン共通):
OS:
Ubuntu 16.04 LTS
各コンポーネントのバージョン:
CuDA 8.0, V8.0.61
CuDNN 8.0 v5.1
Python 2.7.13( on Anaconda 4.3.11)
Numpy 1.12.0
Matplotlib 1.5.3
rl_glue Version 3.04, Build 909
chainer 1.21.0
※セットアップ手順は、「実装 ディープラーニング」に従っています。
実行手順
書籍「実装 ディープラーニング」の三目並べの起動手順と基本的に同じです。
ターミナルを 4 つ起動し、それぞれ以下を実行します。
1つ目のターミナル:
rl_glue
2つ目のターミナル:
. activate main
python agent.py --gpu 0 --size 8
注)
この例では、8x8 サイズのボード、GPU #0 を使用します。
3つ目のターミナル:
. activate main
python environment.py --size 8
注)
この例では、8x8 サイズのボードを使用します。size は Agent 起動時のサイズと同じ値にしてください。
4つ目のターミナル:
. activate main
python experiment.py
experience.py が起動すると、以下の動画のようにオセロゲームが始まります。-1 が環境、1 がエージェントになります。
なお、現時点では実行後にモデルをファイルに書き出す実装は行っていません。実行するたびにゼロから学習のやり直しになります。
実行結果
三目並べに比べてオセロは複雑であるためか、書籍のように 100% の勝率にはなりません。
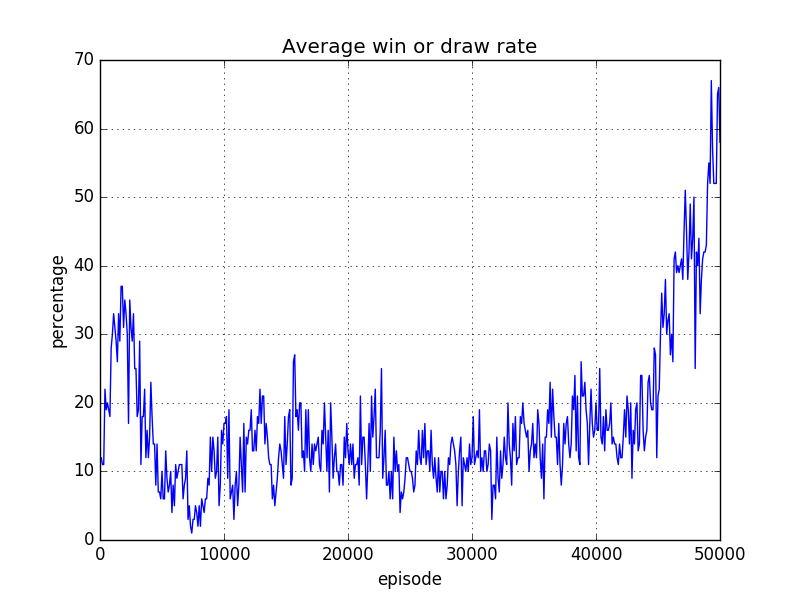
6x6 盤(自宅のマシンで実施)
8x8 盤(Azure NV6 で実施)
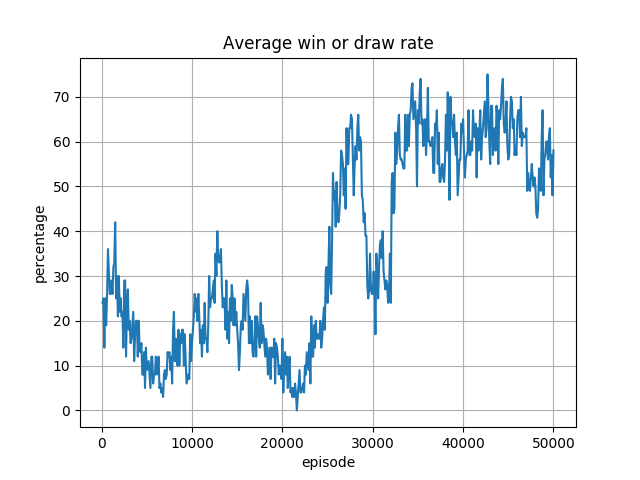
いずれも最終的には7割程度の勝率。環境のオセロが完全にランダムではなく、ある程度「勝ち」に行くロジックであること、またオセロには完璧な必勝法がないことから、勝率自体は妥当と思われます。
しかし、6x6 盤の勝率が 40000 エピソード位まで上がっていないこと、8x8 盤の勝率が 30000 エピソード付近で一旦下がっているといった問題点が見られます。
いずれも、学習のロジックの改善が必要であると考えられます。
例えば、このコードは ReLU を活性化関数に使用しています。
ReLU は「負値はすべて 0」とする関数ですので、あるニューロンの殆どの入力が常に負値になると、常に 0 を出力する、つまり入力に対して出力が固定してしまう可能性があります。こうなると、逆伝搬しても重みが変わることがほぼなくなり、ずっと 0 だけを返す状態、いわゆるニューロンが死んだ状態になりえます。
今回の実行中に W を見たわけではないのですが、仮に大きな負の Bias 値により、6x6 盤なら学習の初期段階で、または 8x8 盤なら 30000 エピソード付近で突然、一部のニューロンが死亡し、残ったニューロンで学習をすることになったことが、学習の遅れの原因とするならば、Leaky ReLU や PReLU を使用すれば、ニューロンの死亡を避けられるため、よりよい学習速度を得られ、勝率も上がるかもしれません。
また、"Prioritized Experience Replay"(2015Schaul)も効果があるかもしれません。今回は学習サンプルデータを完全にランダムに抽出していますが、"Prioritized Experience Replay" はサンプルデータに優先度をつけておき、それぞれの優先度のサンプルデータを取得して学習を行うというものです。サンプルへの優先度の付け方など、まだ学ばなければならないことがありますが、今後時間があったら試してみたいと思います。
いずれにしても、今回のコードをたたき台に、様々なことが試せそうなので、引き続き遊んでみたいと思います。
次回は、コードの解説をしてみたいと思います。
参考にさせていただいた書籍・サイト
参考にさせていただいた情報はこの他にも多数ありますが、特にお世話になったのは以下になります。
(書籍)実装 ディープラーニング
http://shop.ohmsha.co.jp/shopdetail/000000004775/
(書籍)ゼロから作るディープラーニング
https://www.oreilly.co.jp/books/9784873117584/
クラバートの樹 No.180 - アルファ碁の着手決定ロジック(1)(2)
http://hypertree.blog.so-net.ne.jp/2016-06-17
http://hypertree.blog.so-net.ne.jp/2016-06-24
REVERSI
https://inventwithpython.com/chapter15.html
Introduction to Prioritized Experience Replay
https://www.slideshare.net/ssuser07aa33/introduction-to-prioritized-experience-replay
What is the “dying ReLU” problem in neural networks?
http://datascience.stackexchange.com/questions/5706/what-is-the-dying-relu-problem-in-neural-networks/5734