これはこちらの記事の続きです。なお今回で、オセロについては一旦終わりとします。
オセロ〜「実装 ディープラーニング」の三目並べより(1)
http://qiita.com/Kumapapa2012/items/cb89d73782ddda618c99
オセロ〜「実装 ディープラーニング」の三目並べより(2)
http://qiita.com/Kumapapa2012/items/f6c654d7c789a074c69b
オセロ〜「実装 ディープラーニング」の三目並べより(3)
http://qiita.com/Kumapapa2012/items/3cc20a75c745dc91e826
前回の記事で、Leaky ReLU を使用したところ、6x6 盤オセロについては勝率が安定したものの、8x8 盤においては大きな変動が見られ、しかも勝率は低下傾向でした。
これについて、再びLeaky ReLU の Slope を変えて今回実行しました。
コードはこちらです。~~が、置いてあるコードは Leaky ReLU 版になっていません。後日更新します(^^;~~追加しました。
https://github.com/Kumapapa2012/Learning-Machine-Learning/tree/master/Reversi
Leaky ReLU の Slope 変更
オセロ 8x8 盤について、前回示しました、Slope=0.2 の Leaky ReLU での実行結果は以下です。
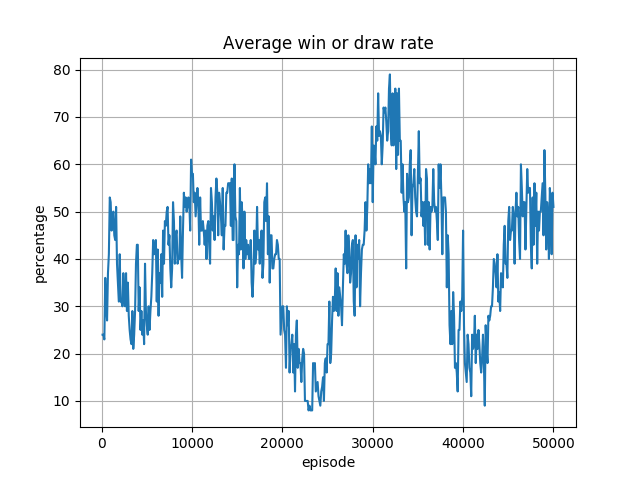
今回、Slope=0.1 とした実行結果は以下です。
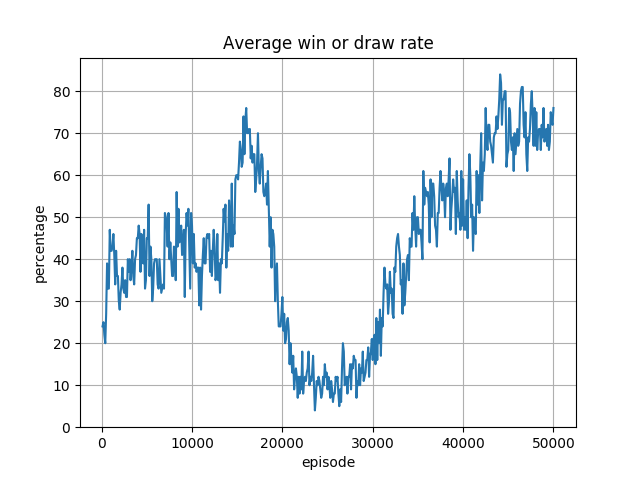
Slope=0.1 にすることで、収束するようになったようですが、Eps. 20000 前後の勝率の急激な落ち込みは解決されません。
これは 6x6 盤の結果では見られない、面白い状況です。
落ち込みの原因は何か?
正直なところ、勝率の変動を見ただけではわかりません。学習率の問題なのかも自信が持てません。
手がかりがないか、5000 ステップ以降出力されている Loss 出力(教師データと算出データとの2乗誤差)をプロット。
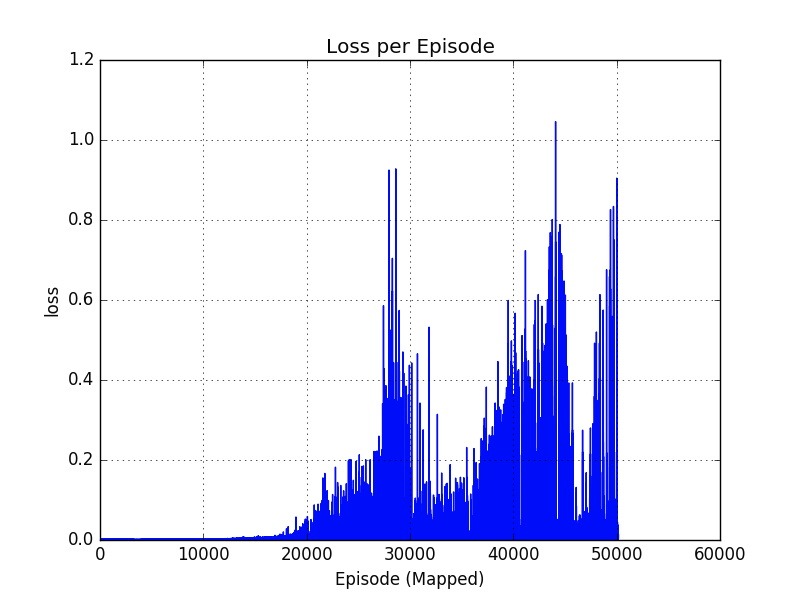
勝率と関連しているようです。これを重ねてみます。
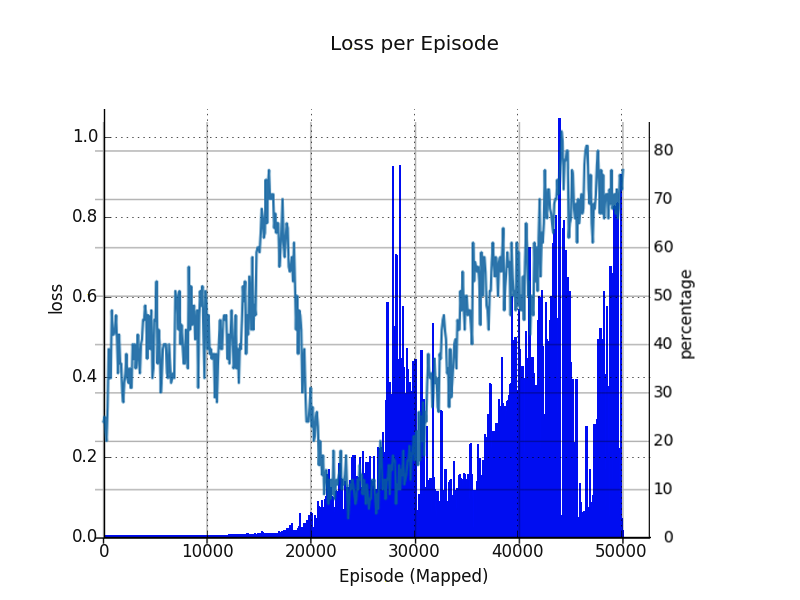
グラフを見る限り、Loss の増加と、勝率急低下には関連があるようです。
この画像を素人なりにどうにか解釈して分類してみますと:
a) 16000(480k Steps) 付近:Loss は非常に低いが、勝率も低い(50%)程度。ここから勝率が上昇に転じる。なお、この時点ですでに ε-Greedy の ε は最低値の 0.001 であり、Q値によるコマの場所決定が支配的な状況になっている。
b) 16000-22000 (660k Steps)付近:勝率が上がるに連れ、 Loss が微増。そして途中から、勝率が激減している。この時点のモデルでは、学習するほど負けが込む状態。モデルが崩壊しているようだ。
c) 22000-27000(720k Steps)付近:定常的に、比較的低い値の Loss が発生、低勝率状態が続く。勝たなければ報酬はないので、この間ほとんど報酬なし。
d) 27000-30000(900k Steps)付近: 再び Loss が拡大。今度は学習がうまく行くようで、勝率が上昇している。
e) 30000-35000(1050k Steps)付近: 一旦 Loss が低下するも、勝率は引き続き上がり続ける。学習がうまく行っている様子。
f) 35000-45000(1350k Steps)付近: 再び Loss が拡大。前回はここが 2 度目の勝率の谷だった。しかし今度は勝率が下がることはない。Loss が学習つまりモデルの補正に対し、いい方向に作用している?
g) 45000-48000(1440k Steps)付近: Loss が低下。勝率も安定している。
h) 48000以降:再び Loss が拡大。でも、勝率が収束する気配がある。
Loss 拡大は、モデルが変貌する、つまりエージェントが成長する予兆といえます。
この状況の解釈が正しければ、エージェントが、b) のあたりで誤った方向に成長していた、と言えそうです。
今回は、全局面をテキストで保存していたので、この仮定について振り返りをしてみます。
序盤で、わりと勝敗の分かれ目になりそうな、以下の局面を見てみます。
[[ 0 0 0 0 0 0 0 0]
[ 0 0 0 (0) 0 (0)(0) 0]
[ 0 (0)(0)-1 (0)-1 0 0]
[(0)-1 -1 -1 -1 1 0 0]
[ 0 0 0 1 1 0 0 0]
[ 0 0 0 0 1 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]]
これは、これからエージェントがコマを置く局面です。
この局面では、(見難いですが)エージェントは、カッコで囲った場所にコマを置けます。
この局面を pcregrep で検索したところ、50000 中 622 エピソードで発見されました1。
勝率の谷に当たる 20000 から 30000 エピソードの間では、この局面は以下の 5 回、発現していました。()内はそのエピソードの勝敗です。
21974(win)
22078(lose)
22415(lose)
29418(lose)
29955(win)
上記局面で、29955 を除く4つは、以下のように打ちました。これを打ち手Aとします。
[[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 -1 0 -1 0 0]
[(1) 1 1 1 1 1 0 0]
[ 0 0 0 1 1 0 0 0]
[ 0 0 0 0 1 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]]
29955 は以下のように打ちました。これを打ち手Bとします。
[[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 -1 (1)-1 0 0]
[ 0 -1 -1 -1 1 1 0 0]
[ 0 0 0 1 1 0 0 0]
[ 0 0 0 0 1 0 0 0]
[ 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0]]
29955以後、すべてのエピソードを見たわけではありませんが、勝率が高めで安定する 50000 まで、確認した同局面ではどれも、打ち手Bに打っていました。
打ち手Aは、この局面で最も多くのコマを取れる手です。勝率が最低の時、このコマを取るアクションが 5 回中 4 回発生していることから、この時のエージェントは、常により多くのコマを取る、というアクションを起こす傾向が強まっていたと考えられます。
しかし、序盤でコマを多く取るという行動は、オセロの戦略上よろしくないとのことです。序盤では打ち手Bのように、取れるコマが最小で、出来るだけ「端」から遠い箇所が、後に有効となります。
ところが、「コマを多く取る」という行動は、自作オセロエージェントが、常に 80% の割合で実施するように実装している行動でした。2エージェントはこの動きを学習してしまったように見えます。
オセロは盤の中心から始まるゲームなので、常にコマを多くとるという行動は、序盤においては中心から遠い「端」を積極的に取ることにつながると考えられます。積極的に「端」を取る行為が、「角」を取るチャンスを誘発してしまい、環境に「角」を取られ、エージェントの負けが続いた、と考えられます。
これは、負けが続く前、勝率 50% 程度の期間は、エージェントと環境が「角」を取る確率はほぼ同等だったものが、エージェントが「端」を取る傾向がすこし強まったとたんに、環境が「角」を取ってしまう確率が高まり、環境が勝ちやすくなった、とも言えそうです。
この、「端」を取ると「角」がとられやすい状況は盤が広いほど発生しやすく、このため、6x6 盤では落ち込みが発生せず、8x8 盤でのみ、落ち込みが発生したと考えられます。
よって今回の勝率低下は、環境の特定の行動にエージェントが影響され、「過学習」(overfitting)と似ている状態に陥り、誤った戦略を学習したため、ということでひとまず結論としたいと思います。
でも、 Leaky ReLU の Slope の効果は、どう解釈していいものか。。。引き続き勉強して考えていきたいと思います。
ともかくこのような事態を避けるには、 Alpha Go のように、環境との対戦の前に、事前に教師あり学習を行い、十分に勉強させておくこと、また誤った方向に成長し報酬が減少した場合、モデルの新陳代謝を加速するために、例えば ε-Greedy の ε を増やす、と言ったことも有効かもしれません。
終わりに
ちょっと他のこともやってみたいので、今回でオセロについては一旦終わりにします。
今回のオセロは、自分で問題を作って、それを強化学習にかませたらどうなるのか?という興味本位ではじめました。強いオセロエージェントを作ることは目的ではないので、エージェントについては一切教師あり学習など行わず、適当に作った、自作の環境だけを相手にしています。
この「白紙」の状態から、環境だけを相手にする強化学習では、環境の行動がモデルに強く影響します。というよりも、他に影響を与えるものがありません。このため今回のように、環境の実装がちょっとまずい場合は、エージェントの学習が一時的に意図しない方向に進むことがあり得る、という結果が見えました。しかしエージェントが自己修正をし、最終的に勝率を上げていく、という姿も見えます。この自己修正が、強化学習の真価なのでしょうか。3
少々情緒的な解釈ですが、変な親(環境)でも、子(エージェント)はまともに育つものなんだなぁ。という感じがします(^^;。4
なお今回のオセロでは、50000 エピソードを実行するのに、6x6 盤の場合 10 時間以上、8x8 盤の場合は24時間以上の時間がかかりました。さらに、8x8 盤は自宅の Pascal GeForce 1050GTX(2GB) ではメモリ不足で動作しませんので、自宅よりちょっと遅い、Azure NV6 上の Maxwell Tesla M60(8GB) で動作させなければならず、おかげで Azure の今月の請求額がもう 1 万円超えました。これ以上試すのはつらいです。
これも、オセロを今回でやめる理由の一つです。
あぁ、8GB の 1070 か 1080 GTX がほしい。。。5
参考文献
●オセロ/リバーシ必勝法 ○
http://mezasou.com/reversi/top27.html