TensorFlowおよびCNN(畳み込みニューラルネットワーク)を理解するために柏木由紀さんの顔特徴を調べてみました。今回は、全体処理の中のTensorFlowの判定部分にフォーカスした解説と全体総括をします。判定では、学習したモデルを使って個別の画像を柏木由紀さんか判断します。
当記事の前提として前編と中編があります。
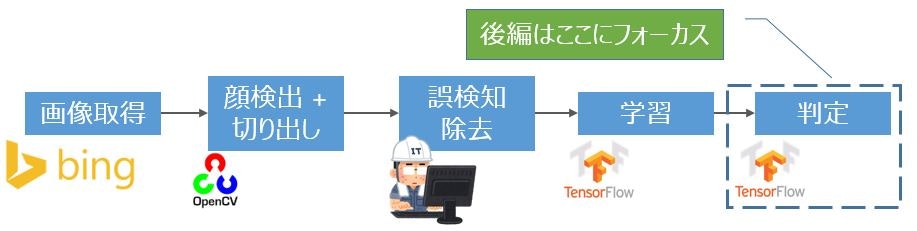
判定処理
前編でも書きましたが、画像判定は、下図の形でOpenCVを使った顔検出 + 切り出しとTensorFlowを使った画像判定を続けてしています。画像判定の際に、「3.学習」のプロセスで保存した学習済パラメータを使用しています。
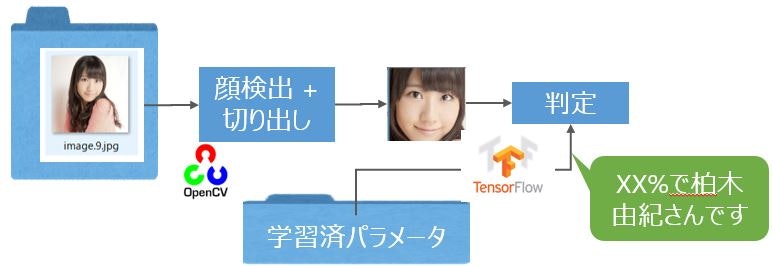
判定実行
実行準備
フォルダ構成はこんな感じで、"models"フォルダにOpenCVで使用する顔検出に使う学習モデルを置きます。取得元はGithubです。OpenCVの基礎に関しては記事「【入門者向け解説】openCV顔検出の仕組と実践(detectMultiScale)」を参照ください。
そして、"images"フォルダに判定対象の画像ファイルを置いてください。複数ファイルも置けますが、最初に顔検出成功した画像ファイルへの判定のみで残り画像ファイルに対しては判定しません。実行時にパラメータ指定することで"images"フォルダ以外の画像を読み込むこともできます。
models
│ haarcascade_frontalface_default.xml
│ haarcascade_frontalface_alt.xml
│ haarcascade_frontalface_alt2.xml
│ haarcascade_frontalface_alt_tree.xml
│ haarcascade_profileface.xml
images
│ 判定対象の画像ファイル
学習実行
python judge_image.py
上記コマンドで実行して、顔検出成功するとポップアップで検出した顔画像を出します。
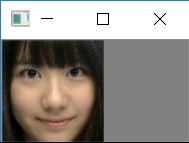
何でもいいのでキーを押すと判定を実行します。

実行時のパラメータとして以下を用意しています。記事「openCVの顔検出でパラメータを指定して手っ取り早く検出精度を高める」で少し解説しているライブラリargparseを使って実装しています。
| パラメータ | 内容 | 初期値 | 備考 |
|---|---|---|---|
| cascade | 顔検出時のモデルファイル | alt | OpenCVの顔検出で使います |
| scale | 顔検出時のscaleFactorパラメータ | 1.3 | このくらいが誤検知少ないです |
| neighbors | 顔検出時のminNeighborsパラメータ | 2 | このくらいが誤検知少ないです。3でもいいかも。 |
| min | 顔検出時のminSizeパラメータ | 50 | もう少し大きくてもいい |
| input_dir | 判定画像のあるフォルダ | ./images/ | この値を変えればテストデータのフォルダ・ファイルを指定可能 |
| log_dir | ログ保存ディレクトリ | /tmp/tensorflow/kashiwagi/logs | 学習したパラメータとTensorBoardログを保存するディレクトリ |
| image_size | 画像サイズ | 81 | resizeするときの初期画像サイズ |
| pool_size | プーリングのサイズ | 3 | マックスプーリングのサイズ |
Pythonプログラム
判定部分(judge_image.py)
モデル部分(model_deep.py)を呼び出して画像判断します。
import cv2, argparse, os
import numpy as np
import tensorflow as tf
import model_deep #TensorFlowの推定部分
# 学習済み画像識別モデルの場所
CKPT_PATH = '/tmp/tensorflow/kashiwagi/logs/'
# 基本的なモデルパラメータ
FLAGS = None
# 識別ラベルと各ラベル番号に対応する名前
HUMAN_NAMES = { 0: u'Kashiwagi', 1: u'others',}
# 顔検出学習済モデルの種類
CASCADE = ['default','alt','alt2','tree','profile']
# 分類器の特徴量取得
def get_cascade():
# 分類器ディレクトリ(以下から取得)
# https://github.com/opencv/opencv/blob/master/data/haarcascades/
# 学習済モデルファイル
if FLAGS.cascade == CASCADE[0]:#'default':
cascade_path = './models/haarcascade_frontalface_default.xml'
elif FLAGS.cascade == CASCADE[1]:#'alt':
cascade_path = './models/haarcascade_frontalface_alt.xml'
elif FLAGS.cascade == CASCADE[2]:#'alt2':
cascade_path = './models/haarcascade_frontalface_alt2.xml'
elif FLAGS.cascade == CASCADE[3]:#'tree':
cascade_path = './models/haarcascade_frontalface_alt_tree.xml'
elif FLAGS.cascade == CASCADE[4]:#'profile':
cascade_path = './models/haarcascade_profileface.xml'
#カスケード分類器の特徴量を取得
return(cv2.CascadeClassifier(cascade_path))
# 顔判定
def run_judge(image):
# 入力画像に対して、各ラベルの確率を出力して返す
logits = model_deep.inference(image, 1.0, FLAGS.image_size, FLAGS.pool_size)
# Softmax計算
loss = tf.nn.softmax(logits)
# TensorBoardにここまでの内容を出力
summary = tf.summary.merge_all()
# 学習済モデル呼出準備
saver = tf.train.Saver()
# Sessionの作成(TensorFlowの計算は絶対Sessionの中でやらなきゃだめ)
with tf.Session() as sess:
# TensorBoradへの書込準備
summary_writer = tf.summary.FileWriter(FLAGS.log_dir, sess.graph)
# 変数初期化(学習済モデル読込前に実行)
sess.run(tf.global_variables_initializer())
# 学習済モデルの取得
ckpt = tf.train.get_checkpoint_state(CKPT_PATH)
# 学習済モデルがあった場合には読込
if ckpt:
saver.restore(sess, ckpt.model_checkpoint_path)
# セッション実行し、TensorBoardのサマリと誤差の取得
summary_str, loss_value = sess.run([summary, loss])
# TensorBoardにサマリを追加してクローズ
summary_writer.add_summary(summary_str)
summary_writer.close()
# 判定結果
result = loss_value[0]
humans = []
# 名前、確率のHashを作成
for index, rate in enumerate(result):
humans.append({
'name': HUMAN_NAMES[index],
'rate': rate * 100
})
# 確率で降順ソートして最も確からしい答えを出力
rank = sorted(humans, key=lambda x: x['rate'], reverse=True)
print('Probalibity %d %% :This image is %s' % (rank[0]['rate'], rank[0]['name']))
# OpenCVを使って顔検出して判断
def read_and_edit_images(file_name, faceCascade):
# 画像ファイル読込
img = cv2.imread(FLAGS.input_dir + file_name)
# 大量に画像があると稀に失敗するファイルがあるのでログ出力してスキップ(原因不明)
if img is None:
print(file_name + ':Cannot read image file')
return 0
# 顔検出
face = faceCascade.detectMultiScale(cv2.cvtColor(img, cv2.COLOR_BGR2GRAY),
scaleFactor=FLAGS.scale, minNeighbors=FLAGS.neighbors, minSize=(FLAGS.min, FLAGS.min))
# 検出できなかった場合はログ出力して終了
if len(face) <= 0:
print(file_name + ':No Face')
else:
# 顔検出した1つ目のみを使って、顔部分を切り取って画像サイズ変更
cut_image = cv2.resize(img[face[0,1]:face[0,1] + face[0,3], face[0,0]:face[0,0] + face[0,2]], (FLAGS.image_size, FLAGS.image_size))
# ポップアップで顔切り取りを画像見せる(キーを押したらポップアップを閉じて次処理へ)
cv2.imshow('image', cut_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
image = []
# TensorFlow形式へ変換(Floatの0-1の範囲)
image.append(cut_image.astype(np.float32)/255.0)
# 配列にしてReturn
return np.asarray(image)
def cut_and_judge_images():
# 分類器の特徴量取得
faceCascade = get_cascade()
# フォルダ内ファイルを変数に格納(ディレクトリも格納)
files = os.listdir(FLAGS.input_dir)
# 集めた画像データから顔が検知されたら、切り取り、保存する。
for file_name in files:
# ファイルの場合(ディレクトリではない場合)
if os.path.isfile(FLAGS.input_dir + file_name):
# 画像読込と顔切り取り
image = read_and_edit_images(file_name, faceCascade)
if image is not None:
# TensorFlowへ渡して画像判断
run_judge(image)
# 1回でも判断したらば終了
return 0.
# 直接実行されている場合に通る(importされて実行時は通らない)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--cascade',
type=str,
default='alt',
choices=CASCADE,
help='cascade file.'
)
parser.add_argument(
'--scale',
type=float,
default=1.3,
help='scaleFactor value of detectMultiScale.'
)
parser.add_argument(
'--neighbors',
type=int,
default=2,
help='minNeighbors value of detectMultiScale.'
)
parser.add_argument(
'--min',
type=int,
default=50,
help='minSize value of detectMultiScale.'
)
parser.add_argument(
'--input_dir',
type=str,
default='./images/',
help='The path of input directory.'
)
parser.add_argument(
'--image_size',
type=int,
default=81,
help='Input image size'
)
parser.add_argument(
'--pool_size',
type=int,
default=3,
help='Pooling size'
)
parser.add_argument(
'--log_dir',
type=str,
default='/tmp/tensorflow/kashiwagi_judges',
help='Directory to put the log data.'
)
# パラメータ取得と実行
FLAGS, unparsed = parser.parse_known_args()
# TensorBoard保存ディレクトリが存在したら削除し、再作成
if tf.gfile.Exists(FLAGS.log_dir):
tf.gfile.DeleteRecursively(FLAGS.log_dir)
tf.gfile.MakeDirs(FLAGS.log_dir)
# 顔検出と判定
cut_and_judge_images()
全体の改善点
いつか以下の改善点を克服してリベンジしたいことろです![]() いつになるのやら。
いつになるのやら。
学習データの少なさ
学習データの少なさが精度を下げる大きな要因になったと考えています。記事「PythonからBing Image Search API v5を呼び出して画像収集」にあるようにBingを使っているのですが、Googleなどの方がよかったか?私以外にもBingで画像をあまり取得できない現象が起きている方がいました。
画像水増しで増やすのもありでした。
CNNの学習モデル
今回はDeep MNIST for Expertsとほぼおなじ学習モデルにしたのですが、Image Recognitionを参考にした方がいいはずです。
最後に
TensorFlowどころかPythonおよびDeep Learning初心者でもこの程度の質ならできました!TensorFlow素晴らしいですね。時間はかかりましたが楽しかったです。
「TensorFlowを使ってDir en greyの顔分類器を作ってみた」と「ディープラーニングでザッカーバーグの顔を識別するAIを作る」の記事はとても参考にさせていただきました。