TensorFlowでのDeep Learningをするためにbing Image Search APIを使って画像収集しました。大量に画像を収集できるようにしています。
以下の環境で実行しています。
| 種類 | バージョン | 備考 |
|---|---|---|
| OS | Windows10 | Pro 64 bit |
| Anaconda | Anaconda 4.4.0 | Anaconda上で仮想環境を作っています |
| Python | 3.5 | TensorFlowと共存しているため、3.5にしています |
| requestsライブラリ | 2.18.4 | bing API呼出に使っています ※筆者のスキル・知識不足で使いましたが、使わないくても実現できるはず |
| API | Bing Image Search API v5 | v7はまだリリースしていないのでv5を使っています。 Googleとの比較まではしていません。 |
実装した機能
パラメータなしで実行
まずは、パラメータなしでプログラム実行します。
python get_images_via_bing_20170822.py
こんな形で経過を表示します。"Get 3 images from offset X"と2行表示しているのは、Bing Image Search APIを2回呼んでいるからです。これは、APIの仕様上、1回の呼び出しで150件までしか検索結果を取得できないため、大量に取得できるように複数回呼び出せるようにしているためです。

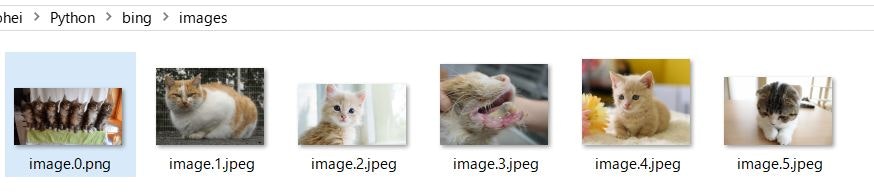
フォルダにかわいい猫が集められました。
パラメータありで実行
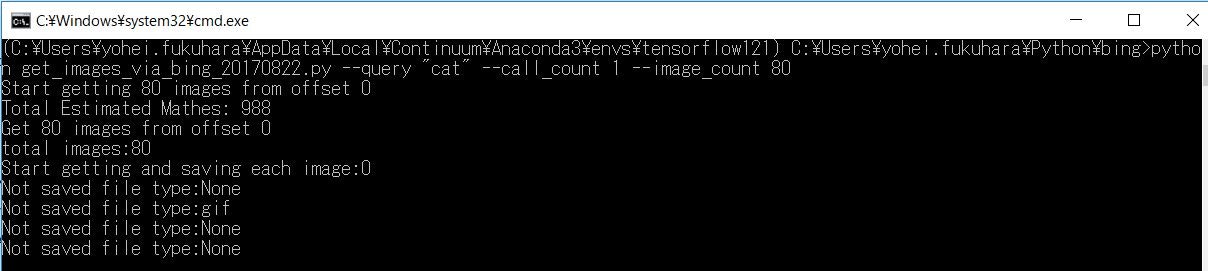
パラメータをつけてプログラム実行してみます。「cat」という検索語句で、80件を1回取得します。
python get_images_via_bing_20170822.py --query "cat" --call_count 1 --image_count 80
"Not Saved file type:"とあるのは、jpegとpng以外の画像種類は取得せずに、その旨をログにだけ出力するようにしています。
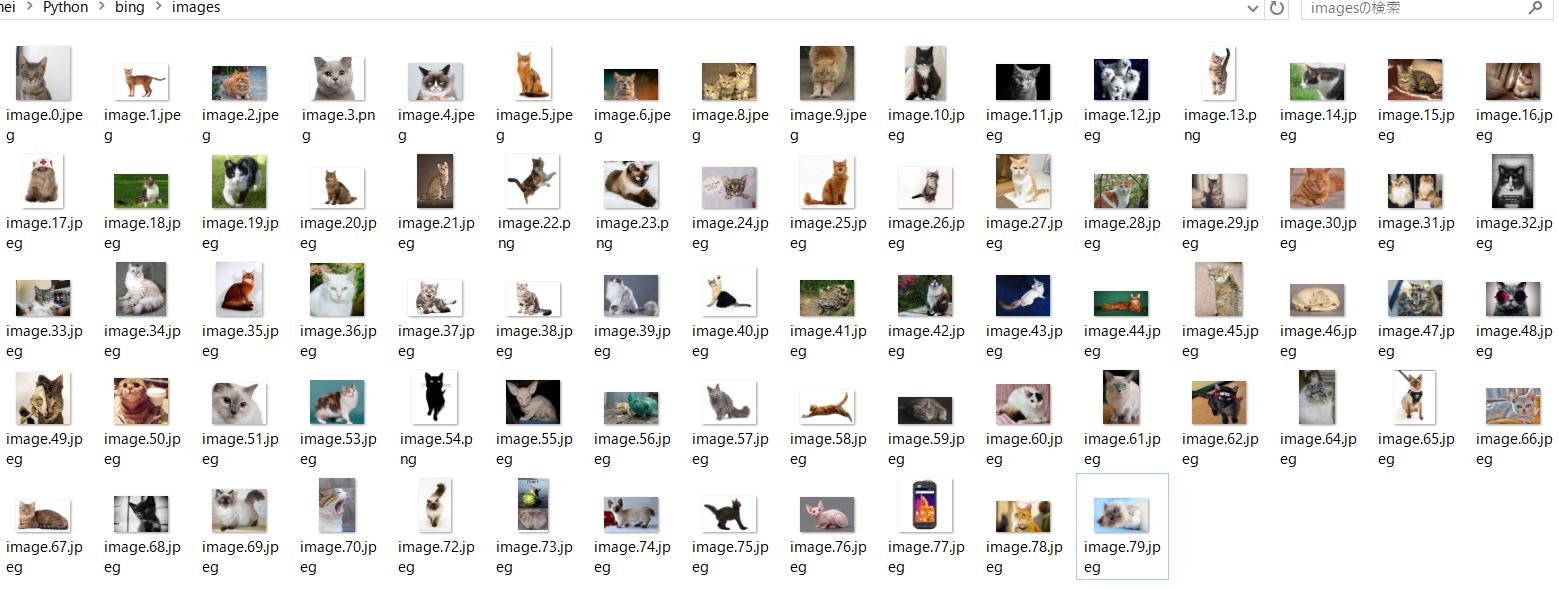
ガンガンたまります![]()
実装手順
1. Microsoft Azureアカウントセットアップ
AzureのCognitive Serviceページから「無料アカウント」リンクをクリックします。
「無料で始める」リンクをクリック
筆者はアカウントがあったので、サインアップに行きました。この後に、個人情報を入れました(記憶が曖昧)。
アカウントのメールアドレスにWelcomeメールが来るので、リンクをクリックした後、ポータル画面へ。
"+"のアイコンをクリックしてBign Search APIsの"create"をクリック。

Bing Search APIsの無料使用版を選択して作成。
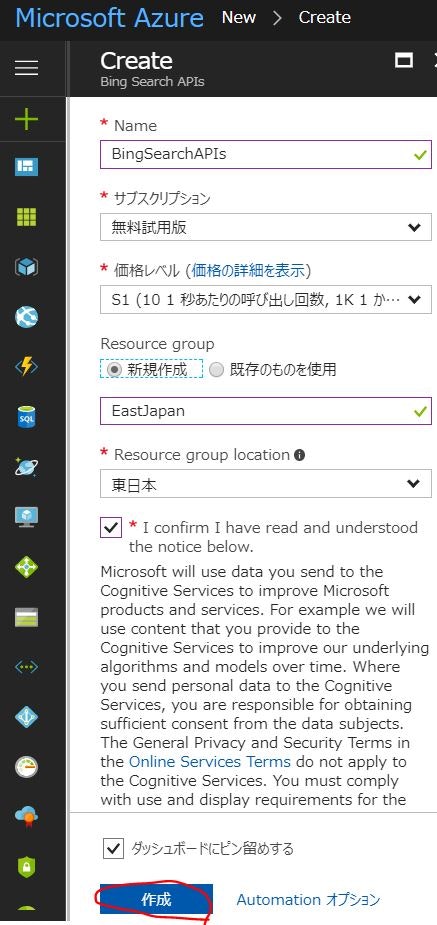
Manage keysの"Show access keys"をクリックしてkeyをメモってください。2つ表示されますが、どちらでもいいそうです(1つ目を使用していて、2つ目は未確認)。

2. requestsのインストール
筆者の環境にはrequestsがなかったのでインストールしました。既にインストールされている方は無視してください。また、冒頭でも触れていますが、なくても実現できると思います。
Anacondaの仮想環境"tensorflow121"にインストールします。Anaconda NavigatorからTerminal起動します。
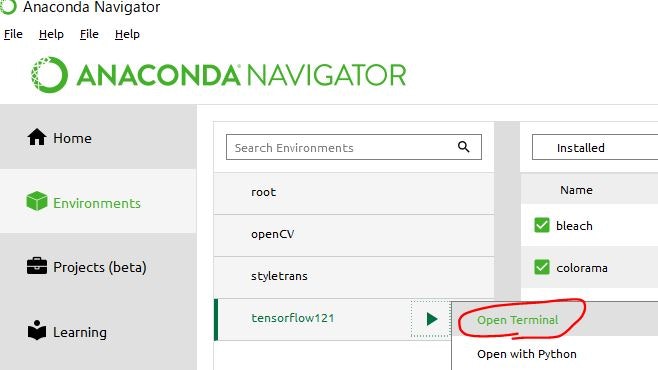
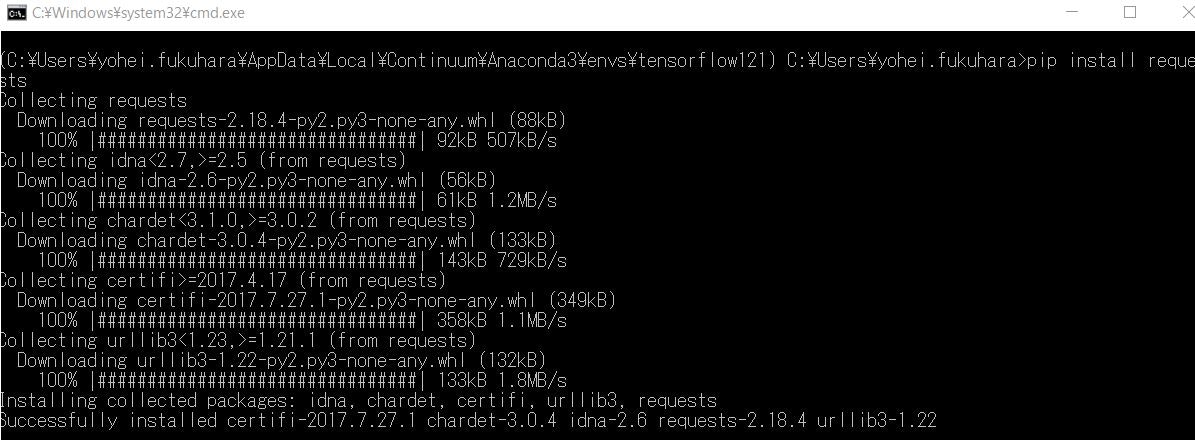
両方ともpipでインストール。特に難しいことはしていません。
pip install requests
3. Pythonコード
こんな仕様にしました。
機能概要
- 1回のBing API呼出で検索語句に対する最大150枚まで画像取得(APIの制限です)
- 1回のプログラム実行で複数回を呼び出して、大量に取得可能
- 取得したファイルをローカルに保存
- 検索結果の途中から取得可能
実行時パラメータ
- image_count:1回のBing API呼出で取得する画像ファイル数
- call_count:1回のプログラム実行でのBing API呼出回数(image_count×call_countで総取得画像数)
- off_set_start:途中呼出時のどこから呼び出すか
- output_path:画像出力ディレクトリ
- query:検索語句
下記コードの「ここにSubscription Keyを入れてください」部分をAzureポータルで作成したSubscription Keyで書き換えてください。
import argparse, requests, urllib.parse, os, io, imghdr
# 基本的なモデルパラメータ
FLAGS = None
# エンドポイント
kEndPoint = 'https://api.cognitive.microsoft.com/bing/v5.0/images/search'
# http リクエストヘッダ
kHeaders = { 'Ocp-Apim-Subscription-Key': 'ここにSubscription Keyを入れてください' }
# 検索結果の画像URL一覧を取得
def GetImageUrls():
print('Start getting %d images from offset %d' % (FLAGS.image_count, FLAGS.off_set_start ))
image_list = []
# bing APIの制限で150件までなので、ループしてcall_countの回数分取得
for step in range(FLAGS.call_count):
# 取得オフセット
off_set = FLAGS.off_set_start + step * FLAGS.image_count
# httpリクエストのパラメータ
params = urllib.parse.urlencode({
'count': FLAGS.image_count,
'offset': off_set,
'imageType':'Photo',
'q': FLAGS.query,
})
# 'mkt': 'ja-JP',
# bing API呼出
res = requests.get(kEndPoint, headers=kHeaders, params=params)
if step == 0:
print('Total Estimated Mathes: %s' % res.json()['totalEstimatedMatches'])
vals = res.json()['value']
print('Get %d images from offset %d' % (len(vals), off_set))
# 結果の画像URLを格納
for j in range(len(vals)):
image_list.append(vals[j]["contentUrl"])
return image_list
# 画像を取得してローカルへ保存
def fetch_images(image_list):
print('total images:%d' % len(image_list))
for i in range(len(image_list)):
# 100件ごとに進捗出力
if i % 100 == 0:
print('Start getting and saving each image:%d' % i)
try:
# 画像取得
response = requests.get(image_list[i], timeout=5 )
# 取得元によってエラーが起きる場合あるため、ログだけ出しておいて続行
except requests.exceptions.RequestException:
print('%d:Error occurs :%s' % (i, image_list[i]))
continue
# 画像種類でフィルタ
with io.BytesIO(response.content) as fh:
image_type = imghdr.what(fh)
if imghdr.what(fh) != 'jpeg' and imghdr.what(fh) != 'png':
print('Not saved file type:%s' % imghdr.what(fh))
continue
# 画像をローカル保存
with open('{}/image.{}.{}'.format(FLAGS.output_path, str(i), imghdr.what(fh)), 'wb') as f:
f.write(response.content)
# 直接実行されている場合に通る(importされて実行時は通らない)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--image_count',
type=int,
default=3,
help='collection number of image files per api call.'
)
parser.add_argument(
'--call_count',
type=int,
default=2,
help='number of api calls.'
)
parser.add_argument(
'--off_set_start',
type=int,
default=0,
help='offset start.'
)
parser.add_argument(
'--output_path',
type=str,
default='./images',
help='image files output directry.'
)
parser.add_argument(
'--query',
type=str,
default='猫',
help='search query.'
)
# パラメータ取得と実行
FLAGS, unparsed = parser.parse_known_args()
fetch_images(GetImageUrls())
やりたかったけど実現できなかったこと
時間が足りなくて以下のことは実現できませんでした。Python初心者には時間かかりそうで諦めてます。
- 検索結果総数に達した場合に自動で終了する機能:普通にコーディングすればいいのですが、面倒で・・・
- requestsライブラリを使わない:urllibのような標準ライブラリだけで実装したかったのですが、できませんでした。非オープンのSAP屋さんからすると、非標準ライブラリはなんか気持ち悪いです(慣れの問題?)。
- サブスクリプションが無料試用版のせいか、"cat"のようなたくさん検索結果がありそうな検索語句でも結果が1000件程度までしか取得できませんでした。どうしても総数の値が少ないです・・・ お手上げ状態

参考リンク
今回、参考にしたサイトをリンクとして載せておきます。
| サイト | コメント |
|---|---|
| 公式テストツール | ここを見ながらコードを組んでいきました |
| API公式資料 | 使えそうなパラメータを参照しました ところでODataはどこへいったの? |
| Bing Image Search APIを使って、画像を自動収集する | Bing APIについてかなり参考にしました |
| Bing Search API v2 から v5 へ移行した話 | 画像取得部分のロジックは特に参考にしました |
| bing_image_getter.py | 最初にこちらのソースをベースに変更していきました |