はじめに
前回は拡張カルマンフィルタによる、自己位置推定の可視化を実演しました。
今回はもう一つの推定アルゴリズムである、パーティクルフィルタ(Particle Filter)を用いた
自己位置推定の可視化を実演していこうと思います。
パーティクルフィルタ(Particle Filter)
パーティクルフィルタは基本的に以下4つのサイクルを実行していく形になります。
- リサンプリング
- 予測
- 観測
- 尤度の計算
パーティクルフィルタアルゴリズムの詳細については色んなサイトで紹介されているので、あえてここでは説明はしません。
アルゴリズムを知りたい方は以下のサイトが参考になると思います。
・パーティクルフィルタ理論と特性
・Pythonでパーティクルフィルタを実装してみる
・粒子フィルタのPython実装
・Particle Filterを使用した自己位置推定MATLABサンプルプログラム
ここでは、パーティクルフィルタアルゴリズムの中でも特に重要そうと思われる個所をピックアップして説明していきます。
リサンプリングのタイミング
以下を参考しました。
・第11章 逐次モンテカルロ法とパーティクルフィルタ
リサンプリングを行うタイミングは以下の評価式から算出される有効サンプルサイズ (Effective Sample Size, ESS)を用いるのが一般的らしいです。
\begin{align}
ESS = \frac{1}{\sum_{i=0}^{N}\Bigl(\omega_{t}^{(i)}\Bigl)^2} \tag{1}\\
\end{align}
ただし、
$N$:パーティルクの数
$\omega_{t}^{(i)}$:時刻$t$における、$i$番目のパーティクルの重み
なお、算出された$ESS$の値には以下のような意味合いがあります。
- $ESS = N$:全てのパーティクルの重みが等しい
(全ての粒子が均等に利用されている) - $ESS = 1$:ひとつを除く、全てのパーティクルの重みが$0$
(ひとつの粒子のみが利用されている)
$ESS$に任意のしきい値を設定することでリサンプリングを行うタイミングを決定します。
リサンプリング方法
以下を参考しました。
・Particle filter のリサンプリング方法の比較
・確率ロボティクス第五回
リサンプリング手法には以下のようなあります。
- 単純ランダム抽出法(simple random sampling)
- 系統抽出法(systematic sampling)
- 層別抽出法(stratified sampling)
- Kullbuck-Leibler divergence(KLD sampling)
確率ロボティクス第五回によると、特に事情がなければ系統抽出法を用いるみたいです。
尤度関数の定義と推定方法
パーティクルフィルタの良し悪しを決定するのが、この尤度関数の定義になります。最適解付近で尤度が最大となるように設計します。
また、推定方法については「重み付き平均」や「最大重み」を適用するなど、方法はいくつかあるみたいです。一般的には重み付き平均がよく使われるらしいですが、その考察をされた先駆者がおりましたので参考にさせていただきました。
・なぜパーティクルフィルタの推定値に「重み付き平均」が使われるのかを考察してみた
例題
2次元座標において、あるロボットが速度$v[m/s]$、角速度$\omega[deg/s]$で周回移動するものとします。このとき、ロボットの移動には誤差$\boldsymbol{v}(k)$を含みます。また、ロボットには距離センサが搭載されており、障害物(ここではランドマークとします。)の2次元座標位置を計測することができます。ただし、計測には誤差$\boldsymbol{w}(k)$を含みます。
サンプリング周期は$\Delta t$とします。ここで、観測されたランドマーク位置から実際の軌跡をパーティクルフィルタによって推定します。
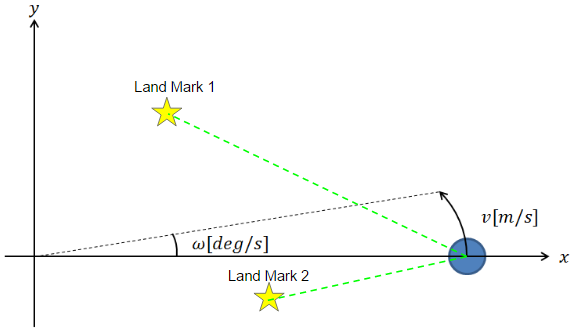
ここで、ロボットの姿勢を定義します。
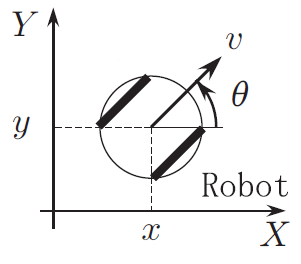
$x,y,\theta$はそれぞれ、ロボットの$X$座標、$Y$座標、姿勢角を表し、姿勢ベクトル$\boldsymbol{x}(k)$は以下のように定義されます。
\boldsymbol{x}(k) =
\begin{bmatrix}
x(k) \\
y(k) \\
\theta(k) \\
\end{bmatrix} \tag{2}\\
よって状態方程式は以下のようになります。
\begin{align}
\boldsymbol{\hat{x}}^-(k+1) &= \boldsymbol{f}(\boldsymbol{\hat{x}}(k),\boldsymbol{u}(k)) \\
&=
\begin{bmatrix}
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \\
\end{bmatrix}
\boldsymbol{\hat{x}}^-(k)
+
\begin{bmatrix}
v & 0 & 0 \\
0 & v & 0 \\
0 & 0 & \omega \\
\end{bmatrix}
\boldsymbol{u}(k) \\
\end{align} \tag{3}\\
但し、
\boldsymbol{u}(k) = \begin{bmatrix}
\Delta t \cdot cos\theta(k) \\
\Delta t \cdot sin\theta(k) \\
\Delta t \\
\end{bmatrix} \tag{4}\\
次は観測値$\boldsymbol{y_r}(k)$を定義します。
まず、観測ベクトル$\boldsymbol{y_r}(k)$を以下のように定義します。
\boldsymbol{y_r}(k) =
\begin{bmatrix}
x_r(k) \\
y_r(k) \\
\end{bmatrix} \tag{5}\\
添え字の$r$はロボット座標系(ローカル座標系)を表します。よって、$x_r,y_r$はそれぞれロボット座標系にて観測されたランドマークの$X$座標、$Y$座標を表します。
また、観測には観測雑音$\boldsymbol{w}(k)$が含まれることから、$j$番目のランドマークの観測値は以下の式で算出されます。
\boldsymbol{y_r}^{(j)}(k) =
\begin{bmatrix}
x_r^{(j)}(k) \\
y_r^{(j)}(k) \\
\end{bmatrix}
+ \boldsymbol{w}_r^{(j)}(k)
\tag{6}\\
例題の説明は以上です。
上記例題を実装したスクリプトはGitHubで公開しています。
・GitHub - particle_filter.py
また、スクリプトを実行した結果は以下のようになります。
(画像をクリックするとYouTubeへジャンプします。)
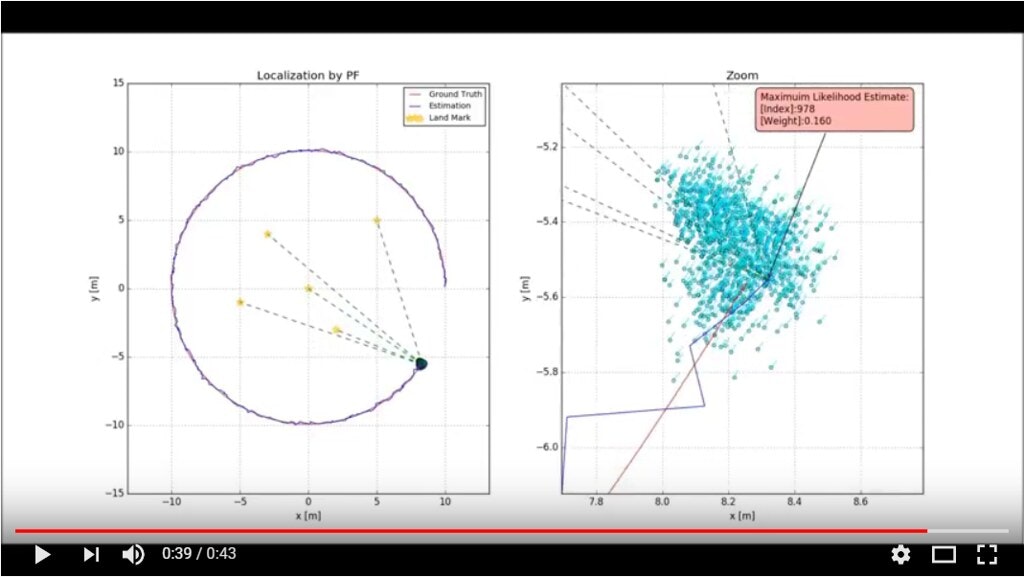
左図がグローバル座標系を基準とした全体の軌跡を表しています。
赤点が現時刻での真の位置を、赤線が過去の真値の軌跡をそれぞれ表しています。
青点が現時刻での推定位置を、青線が過去の推定値の軌跡をそれぞれ表しています。
星★がランドマークを表しています。
右図は赤点を中心とした拡大図です。
水色点が現時刻での全パーティクル位置を表しています。
おわりに
拡張カルマンフィルタとパーティクルフィルタの両方を実装し、実際に動かしてみた感想になります。
-
パーティクルフィルタはロジック設計、実装がめちゃ簡単!
拡張カルマンフィルタはアルゴリズム理解からロジック設計、実装まで3、4ヵ月費やしましたが、
パーティクルフィルタは2,3週間ほどでできてしまった。手軽に推定ロジックを組むならパーティクルフィルタが適しているかもしれない。 -
拡張カルマンフィルタはパーティクルフィルタに比べ、計算コストが低い!
これは設定するパーティクル数$N$に依存するのですが、一般的に拡張カルマンフィルタの計算コストは一定$O(1)$なのに対し、パーティクルフィルタは$O(N)$となります。
当然、パーティクル数が多くなれなばなるほど精度が上がりますが、それに比例して計算コストも上がってしまします。 -
パーティクルフィルタは予測に乱数をしようしているため、なんとなく不安になる!
パーティクルフィルタでは予測の際に乱数を使用してパーティクルをばら撒きます。よって運が悪いと、最適解付近にばら撒けないときもあるのでは?と思ってしまいます。
これはあくまでも私の直観であり、実際に動かしているときはそんなことはありませんでした。