動作環境
GeForce GTX 1070 (8GB)
ASRock Z170M Pro4S [Intel Z170chipset]
Ubuntu 16.04 LTS desktop amd64
TensorFlow v1.1.0
cuDNN v5.1 for Linux
CUDA v8.0
Python 3.5.2
IPython 6.0.0 -- An enhanced Interactive Python.
gcc (Ubuntu 5.4.0-6ubuntu1~16.04.4) 5.4.0 20160609
GNU bash, version 4.3.48(1)-release (x86_64-pc-linux-gnu)
概要
This article is related to ADDA (light scattering simulator based on the discrete dipole approximation).
- TFRecordsを読込んで学習する
- input: 5 nodes
- output: 6 nodes
- サンプル数: 223,872
- 学習データ: ADDAにより計算した値
- #input
- x,y,z: dipole position
- refractive index: real and imaginary part
- #output
- initial values for linear equation solution for (x,y,z),(real,imaginary)
code v0.1
TensorFlow > TFRecords読込み版sine curveの学習 v0.6 > 学習できた
をベースに
TensorFlow v1.1 / 移行 > tf.pack()はtf.stack()になった
の処理に変更してみた。
learn_mr_mi_170722.py
import numpy as np
import tensorflow as tf
import tensorflow.contrib.slim as slim
"""
v0.1 Jul. 22, 2017
- increase network structure from [7,7,7] to [100,100,100]
- increase dimension of [input_ph], [output_ph]
- alter read_and_decode() to treat 5 input-, 6 output- nodes
- alter [IN_FILE] to the symbolic linked file
:reference: [learnExr_170504.py] to expand dimensions to [input:3,output:6]
=== branched from [learn_sineCurve_170708.py] ===
v0.6 Jul. 09, 2017
- modify for PEP8
- print prediction after learning
v0.5 Jul. 09, 2017
- fix bug > [Attempting to use uninitialized value hidden/hidden_1/weights]
v0.4 Jul. 09, 2017
- fix bug > stops only for one epoch
+ set [num_epochs=None] for string_input_producer()
- change parameters for shuffle_batch()
- implement training
v0.3 Jul. 09, 2017
- fix warning > use tf.local_variables_initializer() instead of
initialize_local_variables()
- fix warning > use tf.global_variables_initializer() instead of
initialize_all_variables()
v0.2 Jul. 08, 2017
- fix bug > OutOfRangeError (current size 0)
+ use [tf.initialize_local_variables()]
v0.1 Jul. 08, 2017
- only read [.tfrecords]
+ add inputs_xy()
+ add read_and_decode()
"""
# codingrule: PEP8
IN_FILE = 'LN-IntField-Y_170722.tfrecords'
def read_and_decode(filename_queue):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'xpos_raw': tf.FixedLenFeature([], tf.string),
'ypos_raw': tf.FixedLenFeature([], tf.string),
'zpos_raw': tf.FixedLenFeature([], tf.string),
'mr_raw': tf.FixedLenFeature([], tf.string),
'mi_raw': tf.FixedLenFeature([], tf.string),
'exr_raw': tf.FixedLenFeature([], tf.string),
'exi_raw': tf.FixedLenFeature([], tf.string),
'eyr_raw': tf.FixedLenFeature([], tf.string),
'eyi_raw': tf.FixedLenFeature([], tf.string),
'ezr_raw': tf.FixedLenFeature([], tf.string),
'ezi_raw': tf.FixedLenFeature([], tf.string),
})
xpos_raw = tf.decode_raw(features['xpos_raw'], tf.float32)
ypos_raw = tf.decode_raw(features['ypos_raw'], tf.float32)
zpos_raw = tf.decode_raw(features['zpos_raw'], tf.float32)
mr_raw = tf.decode_raw(features['mr_raw'], tf.float32)
mi_raw = tf.decode_raw(features['mi_raw'], tf.float32)
exr_raw = tf.decode_raw(features['exr_raw'], tf.float32)
exi_raw = tf.decode_raw(features['exi_raw'], tf.float32)
eyr_raw = tf.decode_raw(features['eyr_raw'], tf.float32)
eyi_raw = tf.decode_raw(features['eyi_raw'], tf.float32)
ezr_raw = tf.decode_raw(features['ezr_raw'], tf.float32)
ezi_raw = tf.decode_raw(features['ezi_raw'], tf.float32)
xpos_org = tf.reshape(xpos_raw, [1])
ypos_org = tf.reshape(ypos_raw, [1])
zpos_org = tf.reshape(zpos_raw, [1])
mr_org = tf.reshape(mr_raw, [1])
mi_org = tf.reshape(mi_raw, [1])
exr_org = tf.reshape(exr_raw, [1])
exi_org = tf.reshape(exi_raw, [1])
eyr_org = tf.reshape(eyr_raw, [1])
eyi_org = tf.reshape(eyi_raw, [1])
ezr_org = tf.reshape(ezr_raw, [1])
ezi_org = tf.reshape(ezi_raw, [1])
# input
wrk = [xpos_org[0], ypos_org[0], zpos_org[0], mr_org[0], mi_org[0]]
inputs = tf.stack(wrk)
# output
wrk = [exr_org[0], exi_org[0],
eyr_org[0], eyi_org[0],
ezr_org[0], ezi_org[0]]
outputs = tf.stack(wrk)
return inputs, outputs
def inputs_xy():
filename = IN_FILE
filequeue = tf.train.string_input_producer(
[filename], num_epochs=None)
in_org, out_org = read_and_decode(filequeue)
return in_org, out_org
in_orgs, out_orgs = inputs_xy()
batch_size = 4 # 4
in_batch, out_batch = tf.train.shuffle_batch([in_orgs, out_orgs],
batch_size,
capacity=40,
min_after_dequeue=batch_size)
input_ph = tf.placeholder("float", [None, 5])
output_ph = tf.placeholder("float", [None, 6]) # [6]
# network
hiddens = slim.stack(input_ph, slim.fully_connected, [100, 100, 100],
activation_fn=tf.nn.sigmoid, scope="hidden")
prediction = slim.fully_connected(hiddens, 6,
activation_fn=None, scope="output")
loss = tf.contrib.losses.mean_squared_error(prediction, output_ph)
train_op = slim.learning.create_train_op(loss, tf.train.AdamOptimizer(0.001))
init_op = [tf.global_variables_initializer(), tf.local_variables_initializer()]
with tf.Session() as sess:
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
for idx in range(30000): # 30000
inpbt, outbt = sess.run([in_batch, out_batch])
_, t_loss = sess.run([train_op, loss],
feed_dict={input_ph: inpbt, output_ph: outbt})
if (idx + 1) % 100 == 0:
print("%d,%f" % (idx+1, t_loss))
finally:
coord.request_stop()
coord.join(threads)
実行準備
TensorFlow > 複数のTFRecordsファイルを1つにまとめる v0.1,v0.2
で作成したcombined_IntField-Y_170722.tfrecordsを以下のようにリンクしておく。
$ ln -fs combined_IntField-Y_170722.tfrecords LN-IntField-Y_170722.tfrecords
実行
$ python3 learn_mr_mi_170722.py
...
2017-07-22 11:24:43.941798: I tensorflow/core/common_runtime/gpu/gpu_device.cc:908] DMA: 0
2017-07-22 11:24:43.941802: I tensorflow/core/common_runtime/gpu/gpu_device.cc:918] 0: Y
2017-07-22 11:24:43.941821: I tensorflow/core/common_runtime/gpu/gpu_device.cc:977] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1070, pci bus id: 0000:01:00.0)
100,0.034486
200,0.012395
300,0.017949
400,0.053576
500,0.045468
600,0.059177
700,0.008754
...
補足
- とりあえず動いた程度のコード
- 無駄な処理をしている
- reshapeして
- [0]で値取り出し
- capacityやbatch_sizeは今後検討
lossの経過
$ python3 learn_mr_mi_170722.py > log_learn.170722_t1133
$ head log_learn.170722_t1133
100,0.023204
200,0.010955
300,0.012770
400,0.044665
500,0.032256
600,0.055092
700,0.022653
800,0.016465
900,0.035304
1000,0.019785
Jupyterコード
check_result_170722.ipynb
%matplotlib inline
# learning [Exr,Exi,Eyr,Eyi,Ezr,Ezi] from ADDA
# Jul. 22, 2017
import numpy as np
import matplotlib.pyplot as plt
data1 = np.loadtxt('log_learn.170722_t1133', delimiter=',')
input1 = data1[:,0]
output1 = data1[:,1]
fig = plt.figure()
ax1 = fig.add_subplot(2,1,1)
ax1.plot(input1, output1)
ax1.set_xlabel('step')
ax1.set_ylabel('loss')
ax1.set_ylim([0,0.2])
ax1.grid(True)
# fig.show()
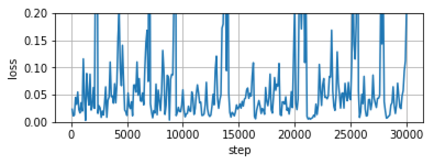
予定どおり芳(かんば)しくない。
http://qiita.com/7of9/items/6c5959c786851bce3e76
と比べてlossが減少していない。
違いはrefractive indexを入れたこと。