要約
超高精度自然言語処理&係り受け解析を実施するGiNZAがすごくて、
Colaboratoryにより環境構築不要でブラウザだけでサクッと使える。
そのサクッと感を強調すべく、LT(ライトニングトーク)の最中に
その場で環境構築&コードを書いて自然言語処理、
しかも高精度&高機能ができるよ、という「手品」をやってみた。
一見スゴイが「手品」にはタネがあって・・・。という話をする。
最後まで読むと、以下の二つのノウハウが分かる
・GiNZAで、ゼロから3分で高精度自然言語処理する方法
・LTでライブコーディングする手品のタネ
背景①: GiNZAすごいっ!
2019年4月に発表された「GiNZA」という、
日本語自然言語処理オープンソースライブラリを動かしてみたら、
簡単に高精度で(超重要)、係り受けやベクトル化なども含めた、
自然言語処理全般が実施出来たので驚いた。
ご参考:
https://www.recruit.co.jp/newsroom/2019/0402_18331.html
GiNZAのすごい点1:環境構築が簡単なのにデフォで高精度
自然言語処理は、環境構築が結構大変な場合が多い。(Mecabとか)
または高精度にしようと辞書等をインストールするのが面倒である。
ところが、「GiNZA」ならば、
pip一発で高精度辞書まで含めてインストールしてくれる。
さらに、Colaboratoryを使って、
全くゼロ状態から始めても、ブラウザだけで容易に動かせる。
GiNZAのすごい点2: 主要機能が一発で全部入り
ただの形態素解析だけではない。
係り受け解析や、人名地名抽出、文章をベクトル化する学習済みモデルなど、
多岐にわたる主要機能が一発で使えるようになる(説明雑)
GiNZAの困った点:情報が少なく使い方が分からん
比較的新しいためか、まだ情報が少ない&探しにくい感がある。
⇒ ★本稿に主要な使い方をまとめておこうと思った★
・品詞が「PROPN」などのUD(Universal Dependencies)基準で分かりにくい
(名詞、動詞、などのおなじみの表現も出せる)
・解析した結果が多様な属性を持つので、欲しい属性どれだっけ?状態
(機能が豊富で使いこなせていない感)
・Colaboratoryで動かすのにちょっとだけノウハウが必要
(起動方法、グラフ表示方法など、それぞれ少し調査が必要だった)
など全般的に分かれば簡単だが、最初の導入が欲しいな感。
背景②:ライブコーディングする手品
とある勉強会のLT(ライトニング・トーク)に出る機会を頂いた。
「GiNZA」のすごさをお伝えしようと思ったのだが、普通に紹介しては
「サクッと簡単に出来る感」が伝わらないし
何より「面白み」に欠けてしまう。
(自然言語処理に興味のある人ばかりじゃない)
そこで、ブラウザを立ち上げただけの白紙の状態から、
「ライブコーディング」で、パパっとその場で
高精度自然言語解析を実装する見世物を思いついた。
サクッと簡単に出来る感があるし、
**え、これだけでこんなすごい解析出来るの!?**という驚きがあるし
その場で見る価値が上がってイベントとしても面白くなる。
が、トークと並行で時間内に
ミスらずコーディングするスキルなど筆者には無いっ!
そうだ!
Pythonにライブコーディングさせよう(謎)
⇒最後に、実は自動でやってました、とネタばらしでオチもつく。
ということで、
ライブコーディングっぽく見せかける手品を開発した話。
コードもあとで記載するので、GiNZA部を入れ替えれば、
どなたでも簡単にLT内でライブコーディングしているように
見せかけることが出来ます!!
なんて恐ろしいノウハウ
GiNZAのノウハウまとめ(まずマジメな話)
まずマジメにGiNZAのノウハウとして、
前提知識/前提環境一切不要で、ブラウザだけで超簡単に
高精度高機能自然言語処理する方法を記載する。
実行方法は、ブラウザで「Colaboratory」と検索して、
「PYTHON3の新しいノートブック」を開いて、
以下の100行足らずのコードを順番に実行(shift+enter)するだけ。
もちろん無料。ぜひお試しあれ。
GiNZAのインストールから、主要機能のサンプル実装まで、
全て分かるコードを作った。
(※ライブコーディング時には、これの簡素版で実施した)
GiNZAのインストール方法:
インストールはpipだけ。関連モジュールや辞書データ全て入って簡単。
!pip install ginza
# ★2020-01-15 のv3のリリースから、このようにpipだけで入るようになった模様
# 従来のインストール方法は下記。(LTではこっちを実施)
# !pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
Colaboratoryの特性、モジュールのパスの関係で、
pip実施後に下記のコマンドを実行する必要がある(おまじない)
import pkg_resources, imp
imp.reload(pkg_resources)
GiNZAの利用方法(主要機能の一発利用)
最初に、実行結果を掲載する。
このように、よく使われそうな形態素解析、
依存構造解析(係り受け)、人名地名などの抽象分類の解析、
及びその可視化を、一発で表示するサンプルコードを作った。
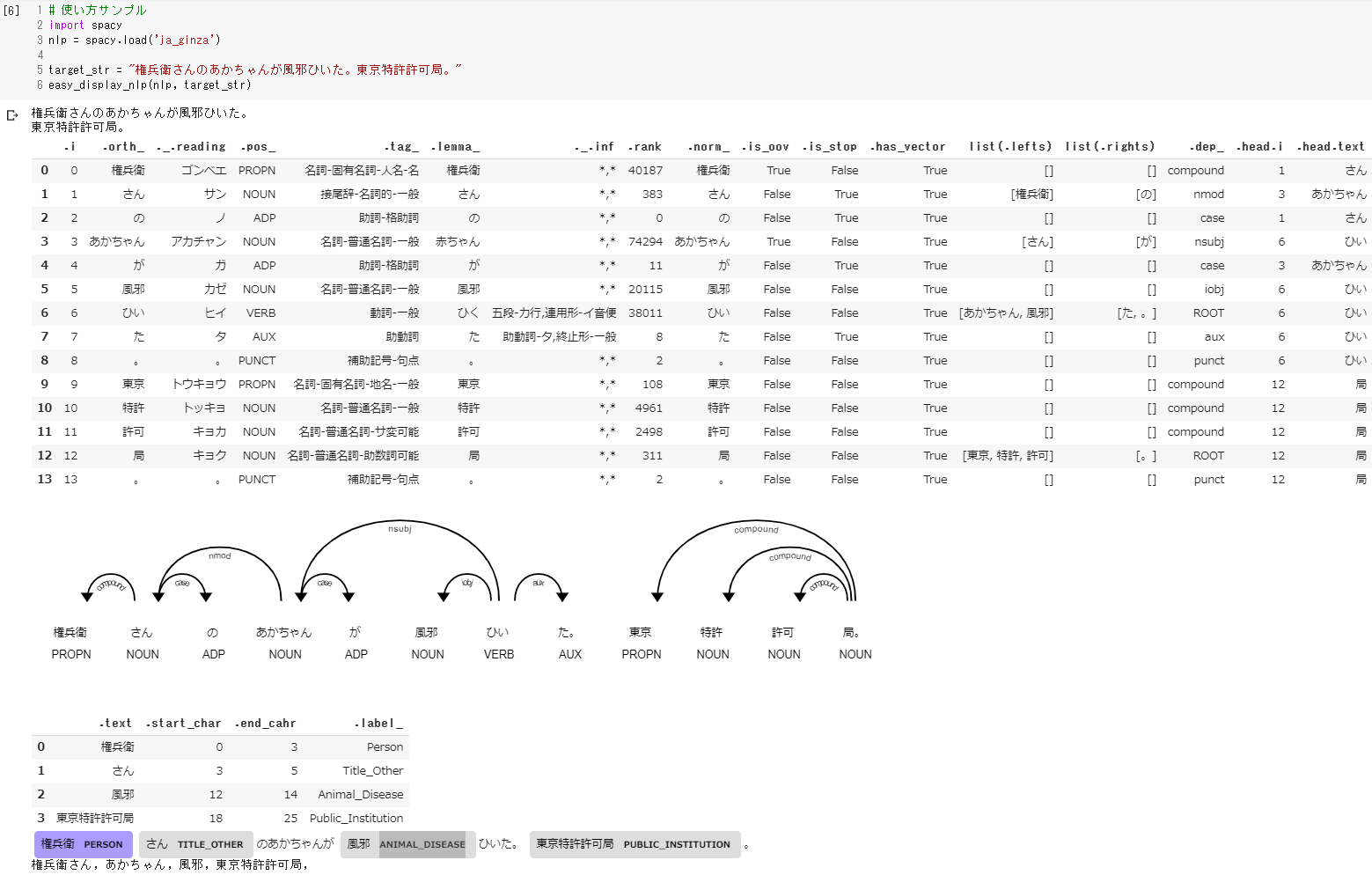
上記を出力した関数がこちら。
# 依存構造解析結果から、主要な要素を表示する関数
# モデルのロードは関数外で実施すること
# import spacy
# nlp = spacy.load('ja_ginza')
# easy_display_nlp(nlp, "テスト用の文章")
def easy_display_nlp(my_nlp, input_str):
doc = my_nlp(input_str)
###依存構文解析結果の表形式表示
result_list = []
for sent in doc.sents:
#1文ごとに改行表示(センテンス区切り表示)
print(sent)
#各文を解析して結果をlistに入れる(文章が複数ある場合でもまとめて一つにしてしまう)
for token in sent:
#https://spacy.io/api/token
#print(dir(token))
#コメントは公式サイト記載ではなく、解釈なので参考程度に。
info_dict = {}
info_dict[".i"] = token.i # トークン番号(複数文がある場合でも0に戻らず連番になる)
info_dict[".orth_"] = token.orth_ # オリジナルテキスト
info_dict["._.reading"] = token._.reading # 読み仮名
info_dict[".pos_"] = token.pos_ # 品詞(UD)
info_dict[".tag_"] = token.tag_ # 品詞(日本語)
info_dict[".lemma_"] = token.lemma_ # 基本形(名寄せ後)
info_dict["._.inf"] = token._.inf # 活用情報
info_dict[".rank"] = token.rank # 頻度のように扱えるかも
info_dict[".norm_"] = token.norm_ # 原型
info_dict[".is_oov"] = token.is_oov # 登録されていない単語か?
info_dict[".is_stop"] = token.is_stop # ストップワードか?
info_dict[".has_vector"] = token.has_vector # word2vecの情報を持っているか?
info_dict["list(.lefts)"] = list(token.lefts) # 関連語まとめ(左)
info_dict["list(.rights)"] = list(token.rights) # 関連語まとめ(右)
info_dict[".dep_"] = token.dep_ # 係り受けの関係性
info_dict[".head.i"] = token.head.i # 係り受けの相手トークン番号
info_dict[".head.text"] = token.head.text # 係り受けの相手のテキスト
result_list.append(info_dict)
#作成した辞書のリストを、DataFrame形式にしてJupyter上で綺麗に表示する
import pandas as pd
#pd.set_option('display.max_columns', 100)
df = pd.DataFrame(result_list)
from IPython.display import display
display(df)
###係り受け表示
#係り受けのグラフ形式を図示する
#Colaboratory上で直接表示するためには少々工夫を要する
#https://stackoverflow.com/questions/58892382/displacy-from-spacy-in-google-colab
from spacy import displacy
displacy.render(doc, style='dep', jupyter=True, options={'distance': 90})
###抽象分類の可視化
#入力した文章に特に地名等がなければ、
#UserWarning: [W006] No entities to visualize found in Doc object の警告が出る
#抽象分類の表示
ent_result_list = []
for ent in doc.ents:
ent_dict = {}
ent_dict[".text"]=ent.text
ent_dict[".start_char"]=ent.start_char
ent_dict[".end_cahr"]=ent.end_char
ent_dict[".label_"]=ent.label_
ent_result_list.append(ent_dict)
#DataFrameの表形式での表示
display(pd.DataFrame(ent_result_list))
#マーキング形式での表示
displacy.render(doc, style='ent', jupyter=True, options={'distance': 90})
###キーワードの列挙表示
#接頭/接尾などが加わった形で出してくれる
for chunks in doc.noun_chunks:
print(chunks,end=", ")
実行方法はこちら
# 使い方サンプル
import spacy
nlp = spacy.load('ja_ginza')
target_str = "権兵衛さんのあかちゃんが風邪ひいた。東京特許許可局。"
easy_display_nlp(nlp, target_str)
形態素解析結果と主要な属性を表形式で表示し、
また、係り受けや人名地名の抽出等を図示する。
この機能を使うとどんな解析になるのか?
と最初に探索する時に活用することを想定。
GiNZAは単語/文章のベクトル演算も可能
以下のように、文章をベクトル化して、類似度計算も出来る。
(学習済みのモデルを内蔵している)
doc1 = nlp('このラーメンは美味しいなあ')
doc2 = nlp('カレーでも食べに行こうよ')
doc3 = nlp('ごめん、同窓会には行けません')
print(doc1.similarity(doc2))
print(doc2.similarity(doc3))
print(doc3.similarity(doc1))
> 0.8385934558551319
> 0.6690503605367146
> 0.5515445470506148
> #食べ物系の二つが最も似ている。
単語のベクトル化も同様に実現出来る模様。
token.has_vectorでベクトル情報を所持しているか確認するのと、
token.lemma_で基本形に戻すことを考えたほうが良いかも。
GiNZAの学習済みモデルについては
まだよく見ていないので、あとで確認したい。
GiNZAのノウハウは以上。
前提知識/前提環境一切不要。
ブラウザでColaboratoryを開いて上記のコードを順番に実行するだけ。
だれでも超簡単に、高精度&多機能の自然言語解析が実現できます!
(使用例)NHKから国民を守る党構文の解析も一発
「NHKから国民を守る党構文」は、
何から何を守っているのか全く理解出来ないですね。
でも、ご安心ください。
これで一発で分かります。そうGiNZAならね
target_str = "NHKから国民を守る党からNHKを守る党からNHKから国民を守る党を守る党からNHKから国民を守る党からNHKを守る党を守る党"
easy_display_nlp(nlp, target_str)

※NHKから国民を守る党構文を人間として理解したい方は
下記の素晴らしい記事をご参照ください。
https://qiita.com/MirrgieRiana/items/da7dade622770a04d8f7
(オマケ)上記サンプルを作るまでに戸惑った点メモ
Colaboratory上での利用に戸惑う
pipインストールするだけでは実行時にエラーになってしまう。
一部の先輩方の情報では、Colaboratoryを再起動しろ、
など方法も見受けられ、前述の方法に辿り着く前に右往左往した。
ただ、よく見たら前述のコードがGiNZA公式サイトにも書いてあった。
当初、この方法が分からずに、後述の
nlp = spacy.load('ja_ginza')の部分を、
nlp = spacy.load(r'/usr/local/lib/python3.6/dist-packages/ja_ginza/ja_ginza-2.2.0')
のように変えて、直接パスを通す方法を勝手に編み出してしまった。
一応余計なコードの実行不要でコレでも動くことをご報告しておく。
!find / | grep spacy | grep data
でGiNZAのColaboratory上でのインストール先パスを調べ、
spacy.load時に直接その絶対パスを指定する方法だ。
品詞が「PROPN」などのUD基準なのに戸惑う
いくつかの実行例では、
「ほら、この単語がPROPNとして解析できました!」
みたいなので説明終了になっていた。
(「名詞」とか「動詞」とか言ってくれないと全く分からんw)
これらのUniversal Dependencies という分類が
国際的には標準らしく、私が不勉強なだけなのだが、
日本語的な分類も併記したり、対応を調べたりした。
また、解析後に使える属性情報が多すぎたので、
dataframeの表形式にして、見やすくした点はちょっと工夫。
「displacy.render」がColaboで表示されずに戸惑う
係り受けや人名地名抽出のグラフ図表示(displacy.render)を普通に使うと
Serving on http://0.0.0.0:5000 ...
などと、表示用のサーバが立ち上がり、
そのサーバにアクセスして図を見る、という流れになるようだが、
Colaboratory内で直接表示させるようにオプションを設定した。
GiNZAのノウハウについてはここまで。
誰でも簡単にライブコーディングっぽく見せかける手品
さて、ここからは本当は紹介したくない悪い子の世界。
まずは、こんな感じにライブコーディングを実演したんだよ、
っていうgif動画をご覧ください。
ライブコーディング手品の様子(環境構築のpip部分省略)

イベントの結果
「手品」と宣言していたにもかかわらず、
「本当にライブコーディングしているように見えてしまった」らしい。
「いや、それ実は打ってないでしょw」みたいなツッコミを期待し、
多少手抜きをしたウソっぽさを入れていたものの、
「簡単にバレるのもツマラナイよな・・・」と、
余計なコダワリも入れすぎたため。
意外とすーぱーえんじにぁっぽく見えた模様(違
ふつーはこんなアホな実装をする人はいないから
数行で簡単に高度なことが出来るGiNZAと、
自動ライブコーディングの相乗こうかは ばつぐんだ!
オートでライブコーディングする仕組みを作ってみたのでございます。
実装方針は、自動と手動の程よいブレンド
主要な方針としては、pyautoguiを使った自動タイピング。
pyautoguiによる自動化の詳細は下記の記事と同様なのでご参照されたし。
「写経」を自動化し、オートで功徳を積める仕組みを作ってみたのでございます。
ただし、これでは「全自動化」であり、
ライブ感が全くない無い。
全自動でひたすらコードを書いていくだけでは、
アドリブが効かないし、トークとの乖離が生じてしまう。
そこでもう一つの方針として、
キーボードイベントハンドリングが重要である。
特殊コマンド(今回は、ctrl+Q にした)を押すたびごとに、
1セル分のコードを自動タイプする。
つまり、各セルを書き始める際の一瞬の手動感と、
なにより、各セルの「実行」だけ「手動」で行うのが重要だ!
この自動と手動の程よいブレンドによって、
コーディング/タイピングがオートになる一方、
「ENTERキーを強打する快感」だけが手動で残るというワケ。
トークで解説等をしながら実行していくため、
LTなどのイベント進行にもピッタリである。
キーボードイベントハンドリングの実装方法
keyboardというライブラリを使う。
※これは、Colaboratoryではなく、
プレゼンするためのPC側で実装/実行する点は注意
pip install keyboard
このライブラリの仕様詳細は下記をご参照。
https://github.com/boppreh/keyboard#keyboardon_press_keykey-callback-suppressfalse
keyboardライブラリの基本的な使い方
最も重要なポイントは以下。(詳細は後述の全コードを参照)
keyboard.add_hotkey('ctrl+q', my_auto_func, args=(1, ) )
このようにホットキーを追加しておき、
ctrl+qが押されるたびに、
pyautoguiを使って作った自動タイピング関数(my_auto_func)を動かす。
タイピングしたい内容は予め文字列でリスト化しておき、
my_auto_func内では、それを順番に出力させればよい。
(実行1回目は1セル目向けの文字列、2回目は2セル向けの文字列をタイプ)
keyboardライブラリで困った点
「半角/全角」のキーを押すとバグる模様。
hotkeyが解除されてしまうようである。
当初、自然言語処理の解析対象とする文章は、
手動入力しようと思っていた。
ただこの問題が解決出来ず、このさい、
全タイピングをオートでやってしまうことにした。
(実行の shift + enter だけ手動♪)
Pyautoguiで悩んだ点/こまった点
USキーボード以外では、「:」を入力しようとすると、
「Shift+:」キーが送信され「*」が入力されてしまう。
ご参考: https://teratail.com/questions/79973
上記のリンク先を参考に一応対策をしたものの、最終的には、
下記のようにtypewriteコマンドで1文字ずつ打っていくのをやめて、
pyautogui.typewrite("abcdefg", interval = 0.1)
下記のようにクリップボードを操作/経由して、
ひたすらctrl+vだけで張り付けていく形で実装した。
# クリップボードに文字をコピーしておく
pyperclip.copy(cp_str)
# すべての文字列は貼り付けて登録
pyautogui.hotkey('ctrl', 'v')
「半角/全角」キー問題のため、日本語も入力したいとなれば、
オートで写経、のようなGijiHenkanを作るのは面倒だし
クリップボード経由のほうが楽に作れるためだ。
変換を経由せずに直接日本語が出て不自然なのは、今回は許容する。
また、Colaboratoryでは
「改行」を打つと自動インデントされてしまうため、
クリップボード以外のキーエミュレート的な方法の場合は、
タイピングするコード文字列を加工しないとインデントがずれる。
クリップボード経由方法ではそれを考慮せずに、
元のコードをそのまま引数にコピペして良いのは大きなメリット♪
さあ、これで誰でもLTでライブコーディングできる!?
と思ったのだが、一度作ってみて自動タイピングを眺めてみると、
最大の誤算があった。
完全に等間隔で1文字ずつ出現するため、
全く人間味が感じられないのだ!
お経のごとく同じペースでタイピングが進んでいく。
お経の方を作っていた時には全く気づかなかった
バレる前提(最後に自分でバラすし)でウケを狙うといっても、
いとも簡単にバレてしまっては面白くない。
ということで自然な雰囲気になるようにチューニングを考えた。
自動タイプのチューニング(失敗例)
当初考えた方法は、
pyautogui.hotkey や pyautogui.typewrite の
タイピング間隔をランダムにするために、
intervalの設定や、sleepを、乱数で入れる方法。
しかし、タイプが遅くなりすぎるという問題が生じた。
pyautoguiには「最小の操作間隔」が存在するようで、
1操作ごとに必ず一定以上の待ちが入る。
1文字ごとの操作だとタイプが遅くなりすぎてしまうのだ。
intervalやsleepなどの待つ方法、
hotkeyやtypewriteなどの打つ方法、
待ち時間乱数の設定範囲など、
いくつか組み合わせたがどうも自然に見えない。
自動タイプのチューニング(採用例)
自動タイプ処理を眺めていると、
適当な間隔を空けてタイプされていくよりも、
複数の文字が一緒に出現するほうがむしろ自然に見える、
ということに気づいた。
人間は数文字ごと単位でまとめて一瞬で打つ、という感じ。
ということで、適当な確率ごとに複数の文字を結合して
(つまりctrl+vを実行する前にクリップボードに出力用文字列を貯めて)
一括で出力するような実装とした。
詳細な実装は後述の全コードでご参照。
実際はあり得ないスピード(複数のキー入力が一括出力)でも
こちらのほうがより自然に見えたのだ。(個人の感想です)
これで、人間のタイピングに近いような感じで、
自動タイピングを実装することが出来た。
もはやもともとの自然言語処理より自然タイピングにがんばりはじめていた
テーマ決めた時点で三日前だったので危険な兆候であった
オートでライブコーディングする仕組みの全コード
このような様々な検討を経て、出来上がったのが下記のコードである。
入力対象の文字列の部分を差し替えれば、
これで誰でもLTでライブコーディングしている風デモを実現出来る!
悪用厳禁、と書いておくが、悪用しか出来なそうなコード
import pyautogui
import pyperclip
import time
import random
# キーボードイベントの追加
import keyboard
# https://github.com/boppreh/keyboard#keyboardon_press_keykey-callback-suppressfalse
# '''トリプルクォートで改行ありのそのまま文字列になる。
# ここに任意のコード群を記載すれば、
# ホットキーを押下するたびに、そのテキストが記載される
# 日本語の疑似変換は未対応(対応は容易だが面倒なので)
my_str_list = [
'''!pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"
''',
'''import pkg_resources, imp
imp.reload(pkg_resources)
''',
'''import spacy
nlp = spacy.load('ja_ginza')
''',
'''
doc = nlp("今日は東京でピザパーティー。権兵衛さんの赤ちゃんが風邪ひいた。")
''',
'''for s in doc.sents:
for t in s:
info = [t.orth_, t._.reading, t.tag_]
print(info)
''',
'''from spacy import displacy
displacy.render(doc, style='dep', jupyter=True, options={'distance': 90})
''',
'''
displacy.render(doc, style='ent', jupyter=True, options={'distance': 90})
''',
'''doc = nlp("NHKから国民を守る党から国民を守る党から国民を守る党から国民を守る党")
displacy.render(doc, style='dep', jupyter=True, options={'distance': 90})
''',
'''doc1 = nlp('このラーメンは美味しいなあ')
doc2 = nlp('カレーでも食べに行こうよ')
doc3 = nlp('ごめん、同窓会には行けません')
''',
'''print(doc1.similarity(doc2))
print(doc2.similarity(doc3))
print(doc3.similarity(doc1))
''',
]
# グローバル変数
now_counter = 0
# 主要実行用関数(引数は未使用)
def my_auto_func(arg_val):
global now_counter
#ホットキー設定に使ったキーが押しっぱなしのまま処理が進むのを防止。少しwait
#特に、コントロールキー等を押しっぱなしの場合、別の動作が入りやすいので注意
time.sleep(1.5)
print("called: "+str(now_counter))
#キーが押されて出力する際に、次の出力すべきものが無い場合は処理終了
if now_counter >= len(my_str_list):
print("END: finish")
exit()
cp_str = ""
#コピペ版
for my_char in my_str_list[now_counter]:
#緩急をつけるために、特定条件なら複数文字同時貼り付け使用にした。
sl_time = random.uniform(-0.03, 0.10)
cp_str += my_char
if sl_time < 0 :
#貼り付けを実行せず継続
continue
else :
#クリップボードに文字をコピーしておく
pyperclip.copy(cp_str)
#すべての文字列は貼り付けて登録
pyautogui.hotkey('ctrl', 'v')
#貼り付けに使ったものはクリア
cp_str = ""
#乱数で生じたスリープ分眠り
time.sleep(sl_time)
#ループから抜けたあと、残りがあれば貼り付け実行
if len(cp_str) > 0 :
#クリップボードに文字をコピーしておく
pyperclip.copy(cp_str)
#すべての文字列は貼り付けて登録
pyautogui.hotkey('ctrl', 'v')
#貼り付けに使ったものはクリア
cp_str = ""
now_counter += 1
print("END: my_auto_func : "+str(now_counter))
# オマケ。実演中に間違った際などに対応するための関数
# 一個前にカウンタを戻して再度同じコードを書いたり、終了させたり。
def my_sub_func(arg_val):
global now_counter
print("called: "+"for_before")
now_counter -=1
#キーが押されて出力する際に、負数になっていた場合は処理終了
if now_counter < 0:
print("END: finish")
exit()
print("END: my_sub_func : "+str(now_counter))
# 以下、メインルーチン
# 途中で全角半角切り替えると、ホットキー追加がバグる模様なので触らないこと。
# (半角モードで実行する)
# 停止する時は、「ctrl +c」で本Python側を強制終了で良い。
if __name__ == "__main__":
try:
#ホットキーとそのイベントを追加するのは一回のみ。
#メインホットキーの設定:使用するアプリの他のショートカットと重複しないように
keyboard.add_hotkey('ctrl+q', my_auto_func, args=(1, ) )
#サブホットキーの設定:使用するアプリの他のショートカットと重複しないように
keyboard.add_hotkey('ctrl+i', my_sub_func, args=(1, ) )
print("Press ESC to stop.")
keyboard.wait('esc')
print("esc-END")
except:
import traceback
print(traceback.format_exc())
exit()
exit()
自動ライブコーディングの魅力とは?
LTは時間が限られている性質上、
Colaboratoryをデモするにしても、
どー考えても最初からコードを準備しておくほうが妥当であり、
ライブコーディングするなんて狂気の沙汰である。しかし、
狂気の沙汰ほどおもしろい (by アカギ)
でも実は予めコードは準備しており、危険なように見えて
セーフティという名の悦楽、安全という名の愉悦 (by トネガワ)
を味わえるという仕掛け。
これで誰でも、
**「一見するとすーぱえんじにあ」**に見せかけることが出来るかも。
※なお本来はこのレベルの実装であれば、Windowsならば、
「UWSC」などの自動化ツールを使ったほうが多分楽である。
あとでMacでも使いまわせるように、Pythonで実装してみた。
(Macでは試していない)
(オマケ)手品として演じる際のミスディレクションの方法
ミスディレクションとは、主に手品で使われる、
観客の注意を意図していない別の所に向かせる現象やテクニックのこと。
「ライブっぽく」見せるためには、観客の思い込みをうまく「作る」と良い。
・最初のColaboratoryの立ち上げまでは、あえて手動で行う
ブラウザでColaboratoryとタイプして検索するなど。
・実行時 shift+enter のモーションを大きくして手動感をアピール
・自動タイプしているときに、手はキーボードの上(当たり前)
・いきなりライブコーディングから入るのではなく、
コイツなら超速で実装してもおかしくないかも?と思わせるような、
なんかすごいっぽいことをした雰囲気を出す前フリ、など
あとがき
いともたやすく行われるえげつない自然言語処理
GiNZAを使えば、
いともたやすく(ブラウザだけ/環境不要)
えげつない(高精度/多機能)
自然言語処理が出来るということが、
表現できたぜェ~ 万雷の拍手をおくれ世の中のボケども
(by レッド・ホット・チリペッパー)
今回は実はLTといわれながら時間が15分とかなり長く、
既にLTと呼ぶ範囲じゃなくね?
「面白いアイデアの出し方」
「技術でなんとかするための学習方法」
の二つのお話をさせていただいた。
その「技術でなんとかするための学習方法」として挙げた
「HB鉛筆法」を例示するため、
今回のライブコーディング実演をした。
HB鉛筆法とは?
HBの鉛筆をベキッ とへし折る事と同じようにッ
出来て当然だと思うだけの学習方法
大切なのは「認識」すること
例えば、自然言語処理なんて簡単だぜ、
出来て当然だぜ、って認識するだけで良いという学習方法。
何かのオリに(アイデアを思いつく際に)
そういえばGiNZAで調べれば「出来る」よね、って思っておくだけ。
本当に知りたければ、やろうと思ったあとで、
改めて本稿を見たり、GiNZAを調べれば良いでしょう。
今回のLTを見るだけで、すでに学習は終わっているッ!
その言葉を頭のなかに思い浮かべた時には
既に終わっているからだ
『学習した』なら使ってもいいッ!
●入門書/カリキュラム/資格試験などの学習方法
⇒ やる人はいいけど、私は途中で寝ちゃうのでダメ。つらい。
●手を動かして自分で何か作る学習
⇒ 最終的にはコレかもしれない。
ただ、人間の時間が有限である以上、全ては無理。
やるモチベーションは何か、も問題。
●遅延評価勉強法
⇒ 必要になったらやる、はHB鉛筆法に近いが、
「もし学べばどんなことが出来そうか?」の情報が無いと、
アイデアを考える時に発想が出てこない。
また、「必要になったら」というのが、
やらされ感があるため、表現だけ、個人的に好みではない。
●HB鉛筆法
⇒ 本稿で言うと、GiNZAの実行結果の画像だけ見て知っておく、
という程度の学習方法。
これくらい3分でできるのね、って認識だけしておく。
メリットは、楽であること。
詳細を見る時間がなくても、漠然と何が出来るか分かるので、
未学習の技術も含めてアイデアを思いつきやすくなる効果がある。
後日、アレを学ぼうかな?というモチベーションが生じやすくなる。
空気を吸って吐くことのように!
スタンドを操るという事はできて当然と思う精神力なんですぞッ!
まさに、世界を支配する学習方法
まとめ
ということで今回は、
「ブラウザだけで高精度自然言語解析が出来るんだと認識しよう!」
「LTで半自動ライブコーディングが実演出来るんだと認識しよう!」
という二つの例を紹介させていただいた。
みなさまにアイデアの天啓がおりる時、
本稿が多少でもプラスに働けば、こんなに嬉しいことはない。
最後に、GiNZA開発者の方々と、
イベント関係者の方々に、多大なる感謝を捧げます。
以上です。