昨日は pandas でのデータセット加工について説明しましたがその続きです。
データを正規化する
実は今までの記事でもさり気なく正規化は登場してきたのですがきちんと説明していなかったと思います。
統計における 正規化 (normalize) とは、異なる基準のデータを一定の基準にしたがって変形し利用しやすくすることです。
たとえば国語が 90 点、数学が 70 点だったとしましょう。単純に数値だけを比較すると国語のほうが成績が良いことになってしまいますが、もし国語の平均点が 85 点、数学の平均点が 55 点だったら果たしてどうでしょうか?このように基準が異なるデータを比較できるようになるといったことが正規化のメリットです。
一般的には平均 0 、分散 (及び標準偏差) が 1 になるように値を変換することを指します。
これは以下の数式で算出できます。
Normalized(A(n)) = \frac {(A(n) - μ(A))} {\sigma(A)}
すなわち平均を引き、標準偏差で割れば良いわけです。これにより平均が 0 となり、標準偏差が 1 となります。
正規化を可視化する
何事も手を動かして目で見てみるのが一番です。pandas で同じことをしてみましょう。
まずはデータフレームを列方向の合計値で除算して総合計が 1 になるように正規化してみます。
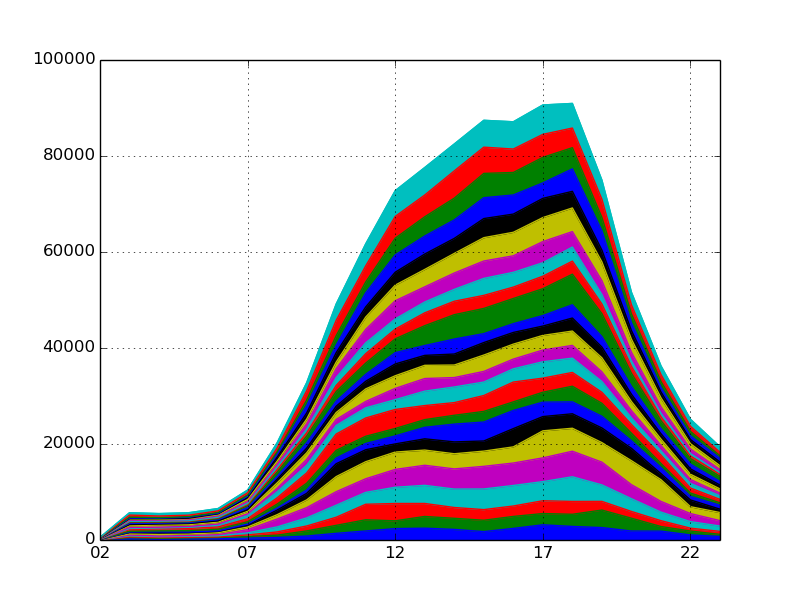
data.div(data.sum(1), axis=0)
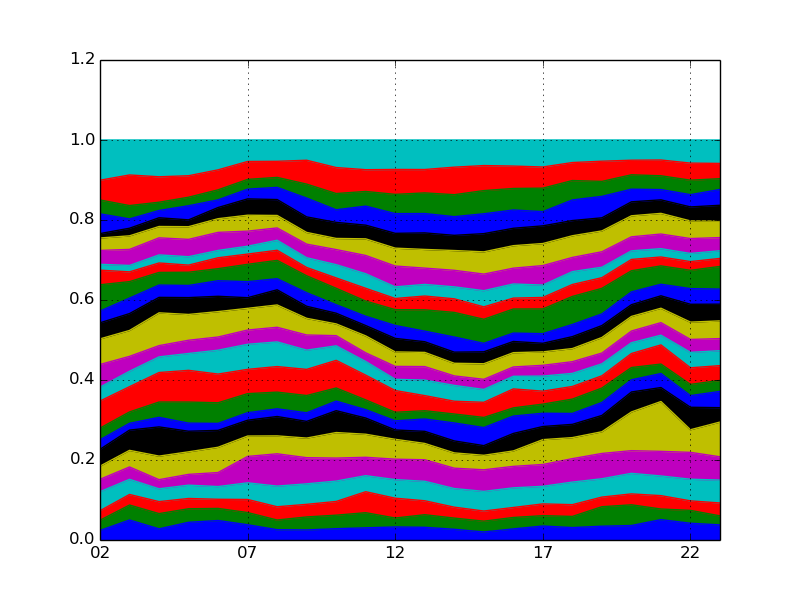
四分位範囲で正規化する
(data - data.quantile(0.5).values) / (data.quantile(0.75)-data.quantile(0.25)).values
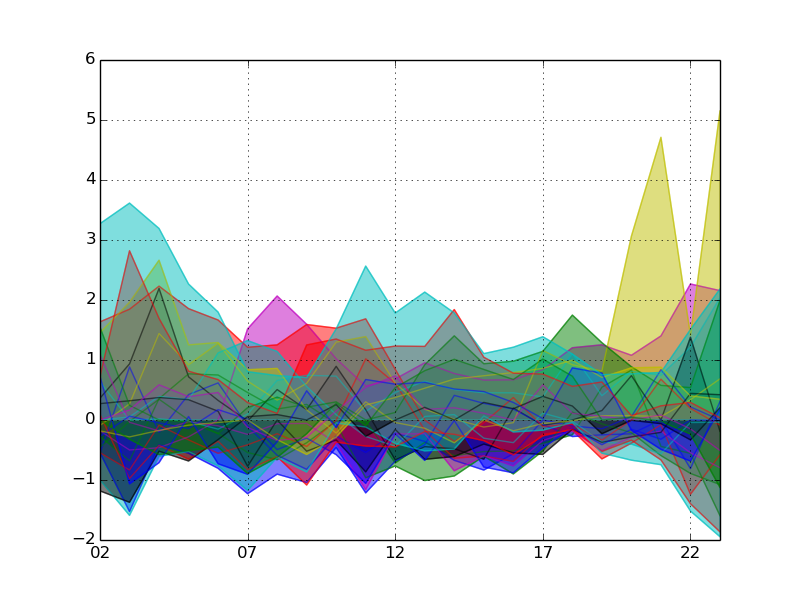
対数変換
対数変換とは、対数正規分布にしたがう変数の対数をとって正規分布に従う変数を作ることです。
対数変換により、少数や、巨大な数値などを整理・表現しやすくすることができます。
コードで表現したほうがわかりやすいかもしれません。
data.apply(np.log)
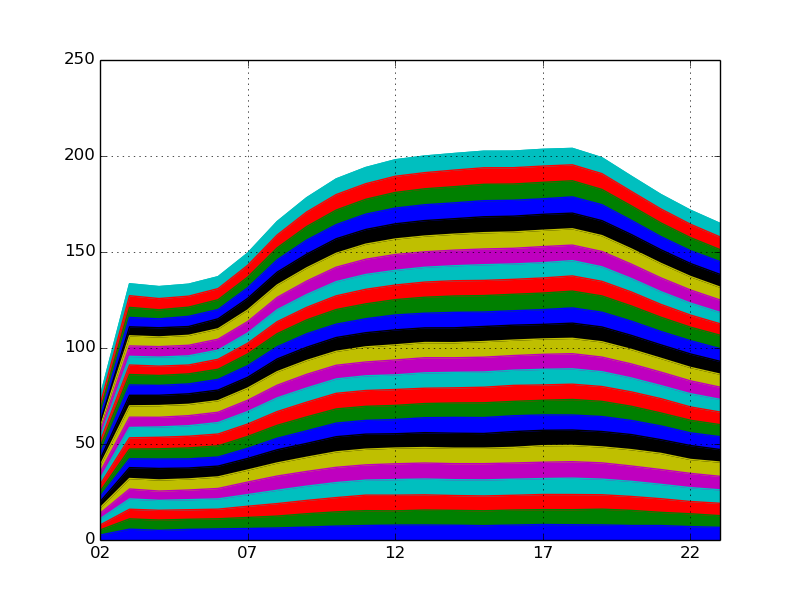
移動率を求める
移動率 (増加率) とは、ある基準となる値に対し、どれだけ変化したのかを示す数値です。
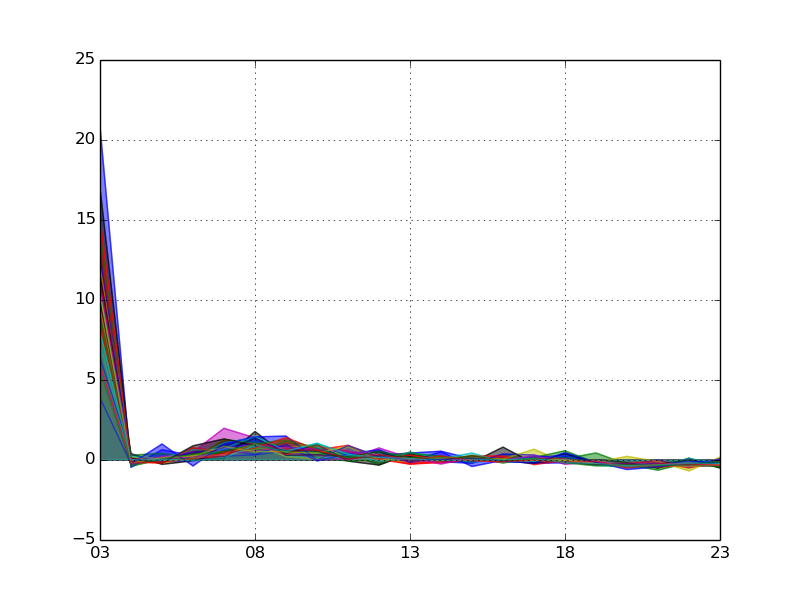
pct_change() はデータフレームの値を移動率に変換します。気をつけるべきポイントとしては、最初の数値はその前がないので移動率が NaN になる点です。移動率もさりげなく以前の記事に登場していました。
data.T.pct_change().dropna(axis=0)
昨日紹介したように、欠損値を削除すると一応は表にできます。ただグラフの最初の値が大きくなってしまうので少し紛らわしいですね。
IPython の作業履歴を保存する
データセットの加工とは直接は関係ありませんが、 IPython で試行した結果をファイルに出力して保存できれば便利です。もし正しい試行をしていたなら、そのままスクリプトとして利用できますし、作業履歴からコードを取り出すなど再利用性が高まります。
import readline
readline.write_history_file("history.py")
これにより IPython に入力したコードの履歴が history.py として保存されます。とても便利ですね。
まとめ
今回もデータセットを加工する上でよく使うさまざまな処理をまとめました。