はじめに
本記事の全体構成について
本記事は、ElasticsearchとKibanaを使った環境のセットアップから、データの投入、データの検索・解析までを紹介する目的で作成した。
記事の構成は下記の通り。
以前の記事を確認していない場合は先にそちらをご参照いただくことをおすすめする。
1回目:Elasticsearch+Kibanaでデータ解析(①環境セットアップ編)
2回目(本記事):Elasticsearch+Kibanaでデータ解析(②スキーマ作成&データ登録編)
3回目:Elasticsearch+Kibanaでデータ解析(③グラフ&ダッシュボード作成編)
前回までの振り返りと今回の内容
前回は、ElasticsearchとKibanaの環境設定の方法について紹介した。
今回は、Elasticsearchにスキーマを作成後、データを登録する方法を紹介する。
Elasticsearchの特徴として、スキーマを登録しなくてもデータ登録ができる事が挙げられるが、日付型やMapping型などはスキーマ登録をしないとうまく動作しないことが多い、また、データが誤って混入してしまうと後でのリカバリが大変になってしまうことなどから、スキーマ登録は必ず行うことをおすすめする。
環境セットアップ(HTTPリクエスト送信ツールインストール)
Elasticsearchの操作はすべてRESTで行うことが標準となっている。
RESTコマンドを実行できるツールであれば何でも良いが、ここでは、SenseというChromeプラグインを利用する。インストール手順は下記の通り。
Senseプラグイン インストール手順
-
Chromeで下記URLにアクセスし、画面右上にあるAdd To Chromeボタンをクリックしてインストールする。インストールが完了すると、URL表示フィールドの横にSenseのアイコンが表示される。
[Chrome SenseプラグインURL]
https://chrome.google.com/webstore/detail/sense-beta/lhjgkmllcaadmopgmanpapmpjgmfcfig
-
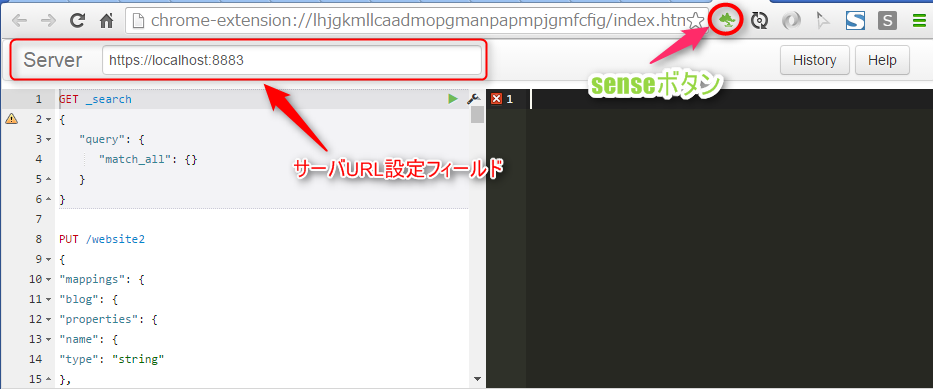
Senseボタンを押すと、下記の様な画面が表示されるので、サーバURL設定フィールドにサーバのURLを記述する。
Mapping(スキーマ)作成
mappingとは?
Elasticsearchのmappingとは、DBでいうところのスキーマ(テーブル型)を指す。
Elasticsearchは、インデックスを作成しなくても、最初に登録されたデータの型を元に型を判断するDynamic mappingという機能を持っている為、必ずしもインデックスを作成する必要はない、しかし、インデックスを作らない場合、後から異なる型のデータを入れることができてしまう。異なる型のデータが登録されると、Kibana等で解析するときにWarningが出たりしてうまく解析ができなくなっていまうことなどがあるため、インデックスはできるだけ作成することをおすすめする。
※座標情報を扱うgeo_pointだけは自動では作成されないことに注意
Mapping作成コマンド例
下記にMapping作成コマンドサンプルを示す。(ちょっと長いが、下記によく利用されそうな型をすべて記述した)
PUT my_index
{
"mappings": {
"blogpost": {
"properties": {
"title_str": {
"type": "multi_field",
"fields": {
"title_str": {
"type": "string",
"index" : "analyzed"
},
"full": {
"type": "string",
"index" : "not_analyzed"
}
}
},
"body": {
"type": "string",
"index": "analyzed"
},
"user_id": {
"type": "string",
"index": "not_analyzed"
},
"category": {
"type": "string",
"index": "not_analyzed"
},
"view_count" : { "type" : "long"},
"update_count": { "type" : "integer"},
"created_date": {
"type": "date",
"format": "YYYY/MM/dd'T'HH:mm:ssZ"
},
"posted_location": {
"type": "geo_point"
}
}
}
}
}
型の決め方
String型を使えばどのようなデータ型のデータも登録することができるが、すべてそうしてしまうとKibanaで解析ができない。(Kibanaを利用するには、インデックス内に1つ以上の日付型のレコードが必要)また、String型では値の集計処理などができない為、データの集計要に応じて型を決める必要がある。
主な型の種類は下記の4つ。
- 文字列型
- 数値型(int, float..)
- 日付型
- Geo型(位置座標)
下記にそれぞれの型の特徴と指定の仕方を記述する。
String:文字列型
文字列を格納するフィールドに指定する。検索時に完全一致で検索したいか、部分一致で検索したいかによって"index":の値を決める必要がある。
analyzed
部分一致に対応させたい場合に指定する。コレを選択すると、インデックス作成時に文字列を構文解析する。デフォルトの構文解析エンジンはEnglish。
not analyzed
完全一致に対応させたい場合に指定する。
multi_field
部分一致・完全一致両方に対応させたい場合に指定する。
下記の例のように"type": "multi_field"の中にanalyzed, not analyzedの両方指定する。
"value_name" : {
"type": "multi_field",
"fields": {
"title_str": {
"type": "string",
"index" : "analyzed"
},
"full": {
"type": "string",
"index" : "not_analyzed"
}
}
}
数値型
数や金額等、集計をしたい値には数値型を使う。フォーマット例は下記。
"field_name(日本語OK)" : { "type" : "integer"}
数値型には下記の6つがあるので、必要に応じて使い分ける。
整数型: byte, short, integer, long
浮動小数点数型: float, double
日付型
日付や時間を扱う場合には日付型を使う。kibanaを利用する場合、最低1つの日付型が存在している必要が有ることに注意する。
"日付フィールド名": {
"type": "date",
"format": "YYYY/MM/dd'T'HH:mm:ssZ"
}
formatには登録する日付のフォーマットを記述する。
日本の時刻に合わせる場合、登録時に下記の様に登録する。(日本時間の2015/01/10 15:30:30を登録する場合)
"日付フィールド名":"20150110T153030+0900"
上述のとおりに登録時間に加えて+9:00を記述しないと、入力した値と表示する値が変わってしまうことに注意。(登録が標準時刻±0だが、表示時は+9:00のため、9時間ズレる)
他にも、事前に登録されている文字列を記述することで様々なフォーマットに対応可能。詳しくはここを参照。
座標
地図上にデータを表示したい場合は、座標型を指定する。
他の数値や日付型とは異なり、座標型はmappingを利用しない限りは自動で適用されることはない。
"フィールド名": {
"type": "geo_point"
}
データ登録(コマンド実行)
ここでは、作成したスキーマ(mapping)に適応したデータを登録する方法を紹介する。登録の方法には一件登録と一括登録の2つがあるが、数万件のデータを一気に登録する場合などに一件ずつデータ登録をすると非常に時間がかかってしまう。
そのため、たくさんのデータを一括で登録する場合、必ず一括登録を利用する必要がある。
参考:9000万件のデータ登録する場合、一括登録を使った場合は3時間程度で完了したが、一件登録をした場合、16時間以上経過しても処理が終わらなかった。
一件登録
insert
POST my_index/blogpost
{
"title_str": "電子たばこ、米で18歳未満に販売禁止へ 利用急増で",
"body": "米食品医薬品局(FDA)は5日、米国の中高生の間で利用が急増している電子たばこについて、18歳未満への販売を禁じることなどを盛り込んだ規制の最終案を発表した。製造業者に対してFDAから製造許可を得ることなども義務づける。90日後に導入される。(朝日新聞デジタル)",
"user_id": "tanaka",
"view_count" : 23,
"update_count": 2,
"category": "A2333",
"created_date": "2015/12/11T16:22:51+0900",
"posted_location": [ 111.129, 31.31 ]
}
一括登録(Bulk insert)
複数のデータを更新したい場合、下記の記法でコマンドを一括で送ることにより、実行時間を大幅に短縮することができる。下記のコマンドの場合、
doc_as_upsert" : trueが指定されている為、対象のデータが存在する場合は、データ更新、存在しない場合はそのデータを登録するupsertを行う。
doc_as_upsert" : falseにすると、対象データが存在しない場合はエラーとなる。
POST my_index/blogpost/_bulk
{ "update" : {"_id" : " AVSD94RsUUOy2pCWY5f0", "_retry_on_conflict" : 2} }
{ "doc" : { "title_str": "バルクテスト1","body": "一括更新テストデス。","user_id": "tanaka", "category":"A1111", "view_count" : 100, "update_count": 2,"created_date": "2015/12/20T13:22:51+0900", "posted_location": [ 111.129, 31.31 ]},"doc_as_upsert" : true }
{ "update" : {"_id" : " AVSD93blUUOy2pCWY5fv33", "_retry_on_conflict" : 2} }
{ "doc" : {"title_str": "バルクテスト2","body": "一括更新テスト2デス。","user_id": "ito","category":"A1811","view_count" : 200,"update_count": 2,"created_date": "2015/12/31T16:22:51+0900","posted_location": [ 111.129, 31.31 ]},"doc_as_upsert" : true }
{ "update" : {"_id" : " AVSD93blUUOy2pCWY5f444", "_retry_on_conflict" : 2} }
{ "doc" : {"title_str": "バルクテスト3","body": "一括更新テスト3デス。","user_id": "yamada","category":"A1191","view_count" : 300,"update_count": 2,"created_date": "2015/11/11T16:22:51+0900","posted_location": [ 111.129, 31.31 ]},"doc_as_upsert" : true }
データ検索
GET my_index_test1/_search?q=user_id:tanaka
GET my_index_test1/_search?q=view_count:100
URL検索
GET my_index/blogpost/_search
{
"from": 0,
"size": 10,
"query" : {
"simple_query_string" : {
"fields": ["user_id"],
"query": "ito yamada",
"default_operator": "or"
}
}
}
レンジで指定
GET my_index/blogpost/_search
{
"query" : {
"range" : {
"view_count" : {
"gte": 100,
"lte": 250
}
}
}
}
その他クエリ参考ページ
その他のクエリ例は、下記のページを参照。
http://qiita.com/Hatajoe/items/3c8851f4813ccc5907c7
まとめ
ここまでで、Elasticsearch上にスキーマを作成、登録と簡単な検索例を紹介した。
PDIを使ってCSVデータを登録する場合はこちら
http://qiita.com/windows222/items/b9226e1b39549b0a59e4
Kibanaを使ってグラフ&ダッシュボード作成する場合はこちら
http://qiita.com/windows222/private/098ded70fb6a6b3c49d2