0. 前書き
今回のプログラムではツイートの文字数を分析します。
1. プログラム実行前に準備すること
Twitterを利用するための下準備をしていきましょう。
- Twitterアカウントを持っていなければ取得してくだい。
- Twitter Appにアクセスします。
- [Create New App]で新規Appを作成します。(URLが聞かれる場合がありますが後からでも変更できるので、最初はなんでも構いません。)
- 各種Keyを発行します。具体的には以下の4つです。
- Consumer Key(API Key)
- Consumer Secret(API Secret)
- Access Token
- Access Token Secret
これらが終われば下準備は終わりです。
2. まずは必要なライブラリのimport
ここからプログラムを書いていきます。
まずはいつも通り必要なライブラリをimportしましょう。
import twitter
import re
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
from pandas import Series
3. 必要な関数の定義
ここで今回読みだしたデータを整形し、必要なデータを持ってくるための関数を定義します。
def parse_tweets(data):
data = [x for x in data if not "@" in x]
for i in range(0, len(data) - 1):
data[i] = data[i].replace(" ", "")
data[i] = data[i].replace("\n", "")
data[i] = re.sub(r'https://[a-zA-Z0-9_./]*', "", data[i])
return [len(s) - 1 for s in data if len(s) != 0]
今回はデータとして、ダイレクトメッセージや写真付きのものは取り除きます。
関数の中身としては、空白、改行、最後にhttps://~の写真をデータの中から削除しています。
4. ツイートを取得
実際にツイートの文字数を取得していきます。
api = twitter.Api(consumer_key='#',
consumer_secret='#',
access_token_key='#',
access_token_secret='#'
)
timelines = api.GetUserTimeline(api.VerifyCredentials().id, count=200)
timelines_texts = [s.text for s in timelines]
result = parse_tweets(data)
ここまでの作業で最新の200件のツイートを取り出し、関数を用いて整形し、result変数に格納しています。
'#'は各自が取得した、各種キーで置き換えて利用してください。
count=の数を変えることで取得するデータ量を変更できます。最高で200件です。
5.分析と可視化
それではデータを分析し、可視化していきましょう。
と言っても分析することはそれほどありません。
まずはSeries型へと変換しましょう。
また、変換する前に昇順でソートしてあります。
これはデータを見やすくするためのものなでなくても問題ありません。
ここまで終わったならば、代表値を表示して見ましょう。
Series型はメソッドとしてdescribe()を持ち、それを用いることにより代表値を計算してくれます。
result = sorted(result)
analysis = Series(result)
print(analysis.describe())
'''
count 157.000000
mean 16.656051
std 8.443411
min 2.000000
25% 11.000000
50% 16.000000
75% 21.000000
max 53.000000
dtype: float64
'''
次にmatplotlibで表示していきましょう。
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
analysis.hist(ax=ax, bins=60)
ax.annotate('Mode',
xy=(16, 11),
xytext=(20, 10),
arrowprops=dict(facecolor='red'),
horizontalalignment='left',
verticalalignment='top')
ax.annotate('Mode',
xy=(18, 11),
xytext=(20, 10),
arrowprops=dict(facecolor='red'),
horizontalalignment='left',
verticalalignment='top')
ax.set_xlabel('length')
ax.set_ylabel('frequency')
plt.savefig('analysys60.png')
plt.show()
plt.close()
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
analysis.hist(ax=ax, bins=20)
ax.annotate('Mode',
xy=(11, 28),
xytext=(13, 26),
arrowprops=dict(facecolor='red'),
horizontalalignment='left',
verticalalignment='top')
ax.set_xlabel('length')
ax.set_ylabel('frequency')
plt.savefig('analysys20.png')
plt.show()
plt.close()
上記のプログラムを実行すると以下のようになります。
結果は個人ごとに違うので、あくまで参考画像です。
階数値が違うので表示結果は異なります。
階数値は自分のデータにあったものを指定してください。
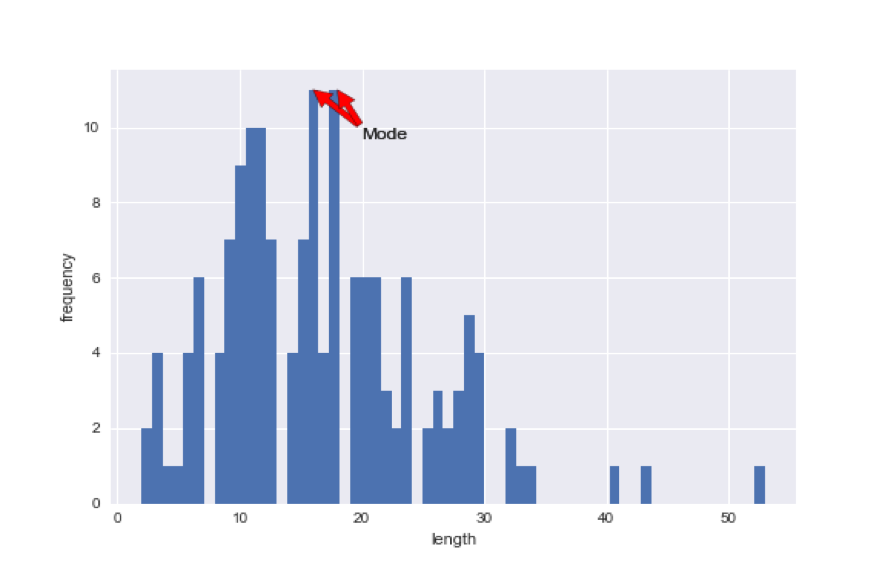
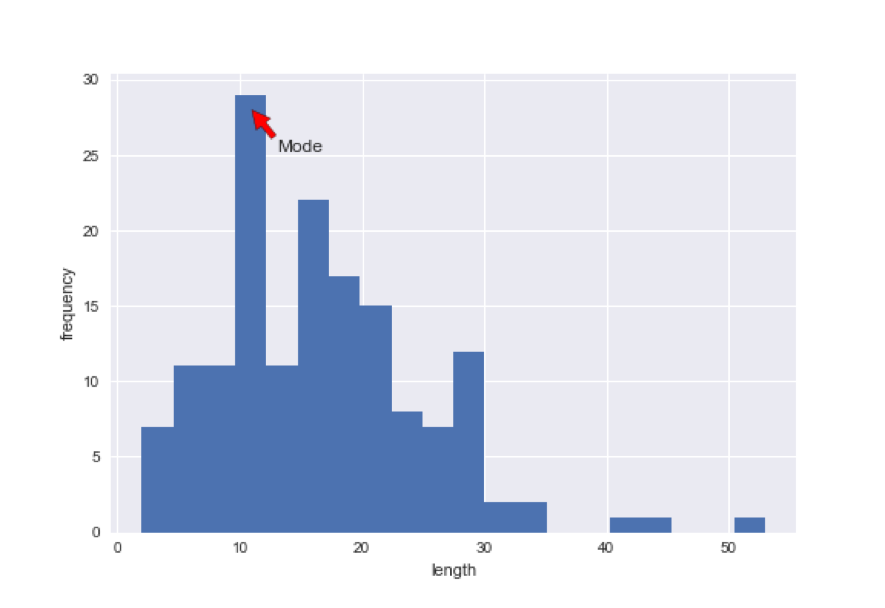
矢印は以下のxy=(,)とxytext=(,)の部分を変更することで場所変えることができます。
また、表示したい名称は'Mode'となっているところを変更すれば変えられます。
*もし、日本語を入力したい場合は環境によってはこれ以外にも設定が必要となります。
ax.annotate('Mode',
xy=(18, 11),
xytext=(20, 10),
arrowprops=dict(facecolor='red'),
horizontalalignment='left',
verticalalignment='top')
最後にカーネル密度推定したグラフを追加したいと思います。
カーネル密度推定について気になる方は参考リンクを見るか、ググってみてください。
analysis.hist(bins=60, alpha=0.1, normed=True, color='k', grid=True)
analysis.plot(kind='kde', style='k--', grid=True)
plt.savefig('kde60.png')
plt.close()
analysis.hist(bins=20, alpha=0.1, normed=True, color='k', grid=True)
analysis.plot(kind='kde', style='k--', grid=True)
plt.savefig('kde20.png')
plt.close()
表示される例としては以下のようなものになります。
先ほどのグラフに密度関数が追加されているのがわかると思います。
また、analysis.hist(bins=60, alpha=0.1, normed=True, color='k', grid=True)のコードにあるようにnormed=Trueにして正規化して使うようにしてくだい。
横軸と縦軸のラベルは密度関数に関連するものとなっております。
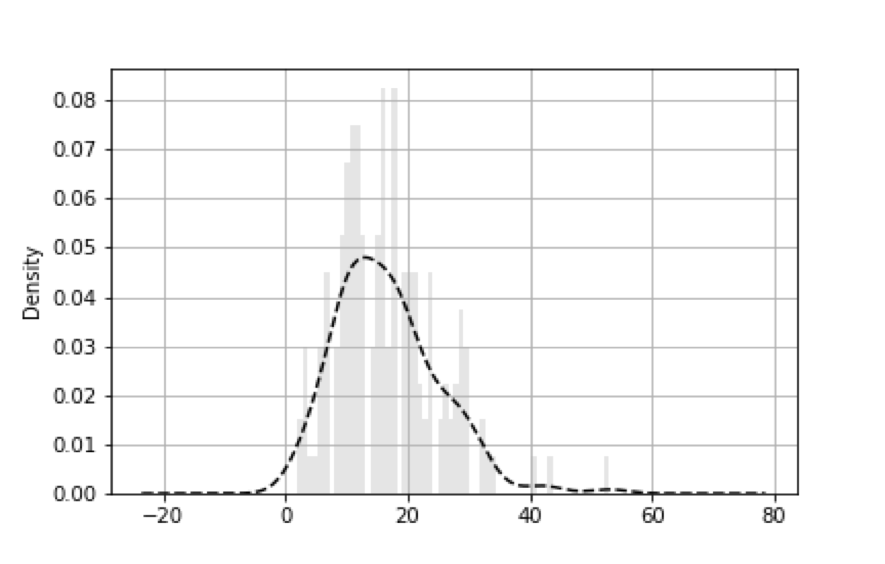
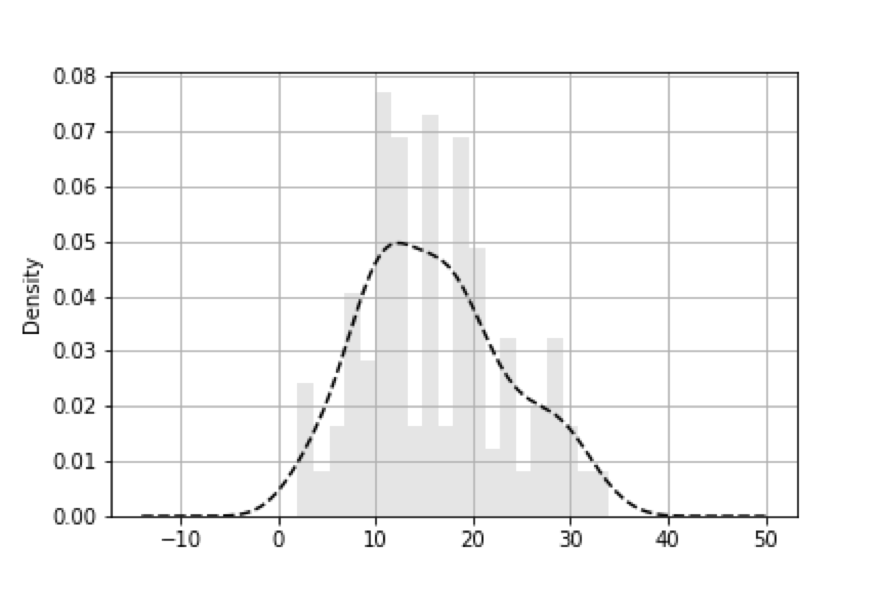
一応分析も簡単に書いておく。
この結果から、分布をt分布だとみなすと信頼係数95%の信頼区間は15.3文字~18文字と推定される。
推定の仕方は調べて見てください。
その他
この要領でやれば他の人のツイートの文字数を可視化したり、Twitter全体の平均を予測したりするモデルが作れるかもしれないので、そのうちやろうと思う。
簡単にですが作りました。