はじめに(前編のおさらい)
Watson Knowledge Studio(以下、WKS)は、IBM Watsonにおいて、特定の業界に特化して用いられる言葉のニュアンス、意味や関係を理解する機械学習モデルを、開発者と専門家が協力して作成するクラウド・ベースのアプリケーションです。
本記事は、Watson Knowledge StudioのTutorialをやってみた (前編)に続く後編です。前回に引き続き、WKSのチュートリアルを実施していきます。
前回では、まずチュートリアルに先立ち、WKSの特色や使用の流れ、アノテーションやtype systemといった概念について解説しました。そしてチュートリアルでは、プロジェクトの作成、type systemの作成、ドキュメントの追加、ドキュメントセットの作成、辞書の追加を実施しました。
今回は、ヒューマン・アノテーション、辞書ベースアノテーション、機械学習アノテーションなど、数種類のアノテーションの方法をチュートリアルを通して学習します。
チュートリアルの前に
前回(前編)で解説した用語のひとつに、ドキュメントに対して正解データを付与する作業を意味するアノテーションがありました。WKSでは、このアノテーションを自動的に行ってくれる機械学習アノテーターを作成することを目指すことになります。
今回(後編)では、この機械学習アノテーターを作成するために用いる次の3つのアノテーションを、チュートリアルを通して体験します。
-
ヒューマン・アノテーション:人間の目でドキュメントを確認し、その中の単語や関係に対して手動でentityやrelationを割り当てる方法です。ある意味もっとも確実といえる方法ですが、時間がかかったり人間ならではのミスもある方法です。複数のヒューマンアノテーターで一斉にアノテーションすることにより正確さを高めることもできますが、その場合はアノテーター間で矛盾したアノテーションをおこなう(アノテーションの競合といいます)可能性もあるため、最終的にはその競合を解消する必要があります。
-
辞書ベースアノテーション:辞書とドキュメントを照らし合わせ、辞書にある単語がドキュメント内にもある場合、その辞書に対応するentity typeをその単語に割り当てる方法です。ドキュメントが固有名詞や特殊な用語を持つ場合に有効ですが、逆に多義語の分類を正しくできないことがあります(はし(橋)とはし(端)など)。また、辞書ベースアノテーションではrelationをアノテーションしないため、代わりにヒューマン・アノテーションにより手動で補う必要があります。
-
機械学習アノテーション:既存のドキュメントのみをアノテーションした後、機械学習モデルを作成してアノテーションの結果を学習させ、その学習モデルを使用して後から追加した未知の新しい文書に自動的にアノテーションする方法です。学習に使用されたドキュメントと新しいドキュメントが似ている場合に有効です。
重要なのはこの3つのアノテーションの使い分けです。たとえば、辞書ベースアノテーションを事前に実施しておくことで、ヒューマン・アノテーションを行う際にドキュメントのアノテーションを一からすべて実施する必要をなくし、作業負荷を軽減する、といったことが可能になります。こうしてアノテーションしたドキュメントを機械学習させてモデルを作成したり、逆にそのモデルによって機械学習アノテーションしたドキュメントを再びヒューマン・アノテーションによって修正してモデルを再学習させることによって、機械学習アノテーターの精度を改善する、といった作業をすすめることになります。
チュートリアル
では、前回の続きからチュートリアルを再開します。
- 前編(前回)
- Lesson 1: ユーザーロールの割り当て
- Lesson 2: プロジェクトの作成
- Lesson 3: type system の作成
- Lesson 4: ドキュメントの追加
- Lesson 5: ドキュメントセットの作成
- Lesson 6: 辞書の追加
- 後編(今回)
- Lesson 7: 辞書ベースアノテーターによる事前アノテーション
- Lesson 8: アノテーション・タスクの作成
- Lesson 9: ドキュメントのアノテーション
- Lesson 10: アノテーター間合意分析
- Lesson 11: アノテーション済ドキュメント間の競合の解消
- Lesson 12: 機械学習アノテーターの作成
- Lesson 13: 機械学習アノテーターによる事前アノテーション
なお、Lesson 8からLesson 11は、ヒューマン・アノテーションの作業に相当します。
Lesson 7: 辞書ベースアノテーターによる事前アノテーション
辞書ベースアノテーターを作成して、ドキュメントの事前アノテーションを行います。
Annotator Componentページにて、DictionaryボックスのCreate this type of pre-annotatorをクリックします。
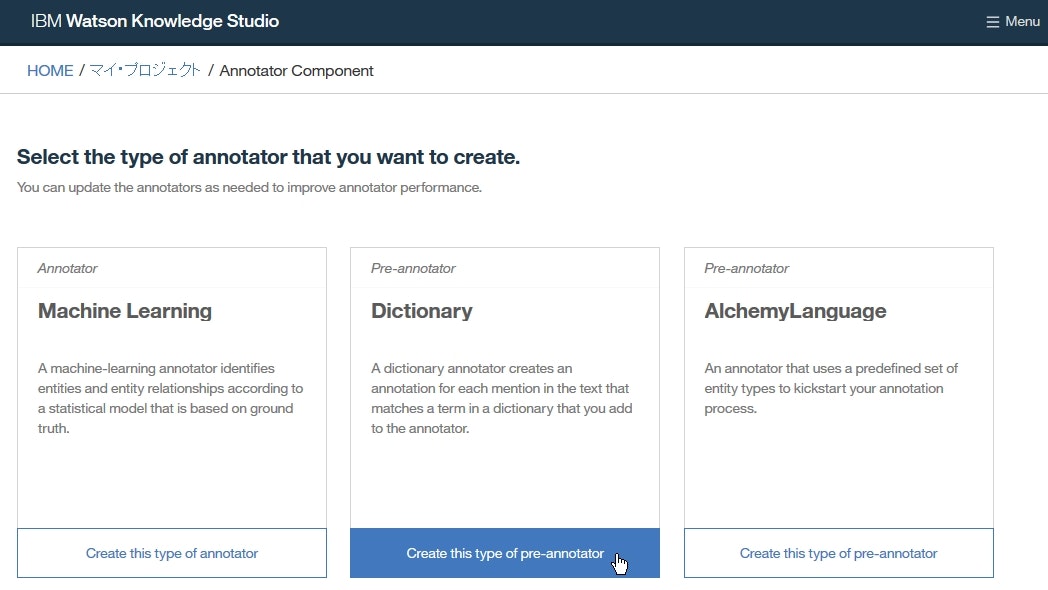
Create Annotatorページにて、前回(前編)の「Lesson 6: 辞書の作成」で作成したTest dictionary辞書の横のチェックボックスを選択します。選択された辞書の単語がプレビューに表示されます。
さらに、Createをクリックして、ドロップダウンからCreate & Runを選択します。

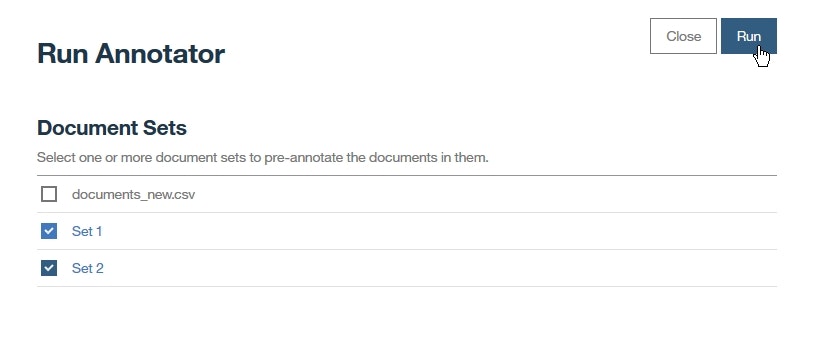
Run Annotatorページにて、前回(前編)の「Lesson 5: ドキュメントセットの作成」で作成した2つのドキュメントセットの横のチェックボックスを選択し、Runをクリックします。
Annotator Componentページに辞書ベースアノテーターが追加され、この辞書ベースアノテーターによる2つのドキュメントセットSet1,Set2への事前アノテーションが行われます。
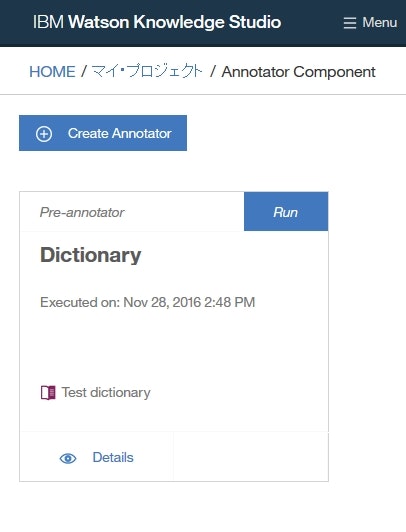
Lesson 8: アノテーション・タスクの作成
ヒューマン・アノテーションを行うために、アノテーション・タスクを作成します。
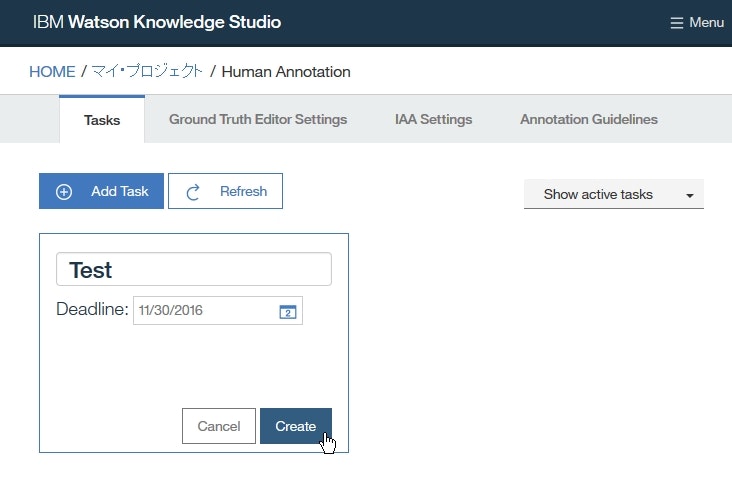
Human Annotationページにて、Add Taskをクリックします。

- タスクを表すボックスにおいて、タスクの詳細を下記のように指定し、
Add Taskをクリックします。
Enter a title欄:TestDeadline欄:未来の任意の日付
Add Document Set to Taskウインドウにおいて、前回(前編)の「Lesson 5: ドキュメントセットの作成」で作成した2つのドキュメントセットの横のチェックボックスを選択し、Create Taskをクリックします。
Testタスクが作成され、Human AnnotationページのTasksタブに表示されます。


Lesson 9: ドキュメントのアノテーション
ヒューマン・アノテーションを行います。
実際のプロジェクトでは、HUMAN_ANNOTATORロールを持つ複数の異なるユーザーにより多くの単語に対してアノテーションを行いますが、本チュートリアルでは話を簡単にするため、単一のユーザーにより2箇所だけアノテーションを行うことにします。
Human Annotationページにて、「Lesson 8: アノテーション・タスクの作成」で作成したTestアノテーション・タスクをクリックします。
- ドキュメントセット
Set 1の横のAnnotateをクリックします。

- ドキュメント一覧のページにて、ドキュメント
Technology - gmanews.tvをクリックします。

- アノテーションページが開きます。
すでに単語IBMがORGANIZATIONentity typeとしてアノテーションされています。このアノテーションは、「Lesson 7: 辞書ベースアノテーターによる事前アノテーション」にて辞書ベースアノテーターによって事前に追加されたものです。この事前アノテーションは正しいので変更の必要はありません。
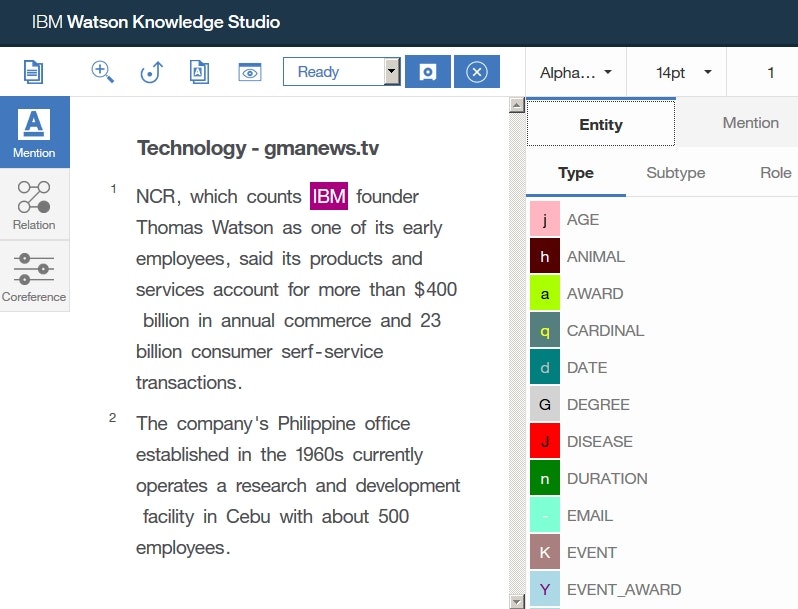
- 左側の
Mentionアイコンをクリックし、entityのアノテーションを開始します。
ドキュメント内のテキストThomas Watsonを選択して、右のEntity-TypeリストのPERSONをクリックします。これにより、テキストThomas WatsonがPERSONentity typeとしてアノテーションされます。
※ショートカットコマンドとして、右側のリスト内のentity/relationをクリックする際、代わりにリスト内のentity/relationの左側に表示されている文字(PERSONentityの場合はp、PRODUCTentityの場合はQなど)を入力することによってもアノテーションを行うことができます。

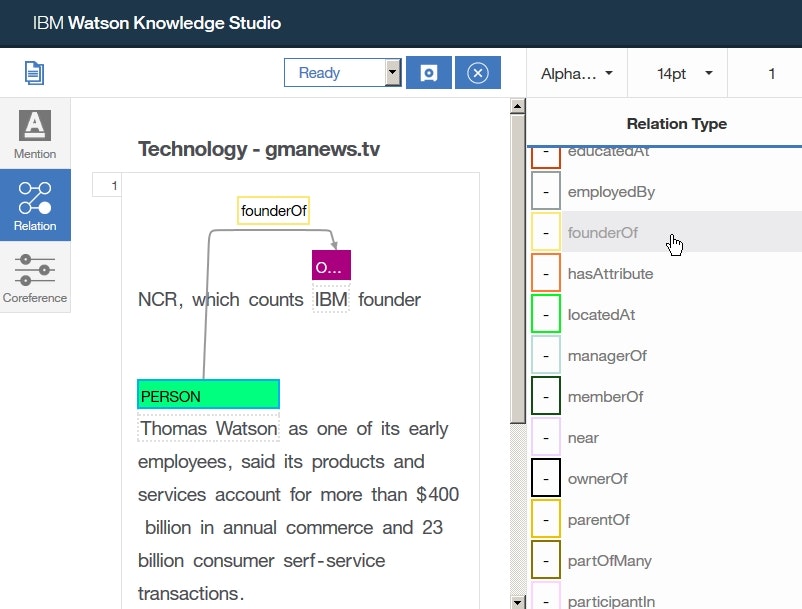
- 左側の
Relationアイコンをクリックし、ドキュメント内の2つのテキストThomas WatsonとIBMのrelationのアノテーションを開始します。
この2つのテキスト上部に表示されたentity typeのラベルPERSONとORGANIZATIONをこの順番で選択します。さらに、右のRelationリストのfounderOfをクリックします。これにより、2つのテキストThomas WatsonとIBMとの間の関係がfouderOfrelation typeとしてアノテーションされます。
- 上部のメニューから
Completedを選択し、Saveをクリックします。

- 戻ってきたドキュメント一覧のページにて、
Submit Allをクリックします。

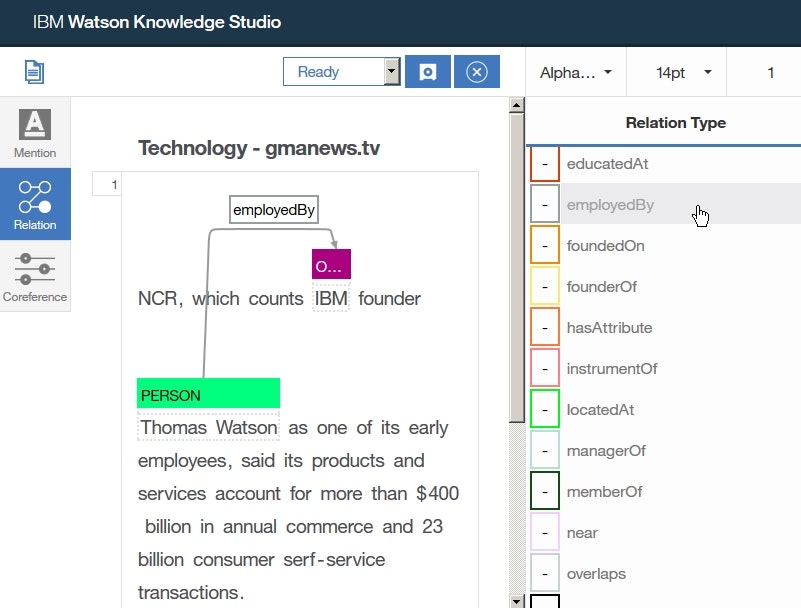
- ドキュメントセット
Set 2に対しても、手順2.-8.を繰り返します。ただし、手順6.においてのみ、founderOfrelation typeの代わりにemployedByrelation typeを選択します。
Lesson 10: アノテーター間合意分析
複数のヒューマン・アノテーターによるアノテーションを比較する方法を見ます。
「Lesson 9:ドキュメントのアノテーション」により、ヒューマン・アノテーターからアノテーションが提出されました。異なるヒューマン・アノテーターが同じドキュメントに対して矛盾なくアノテーションしている(アノテーションに競合がない)かどうかを確認するには、アノテーター間合意(Inter-Annotator Agreement)スコア(以下、IAAスコア)を確認します。スコアが許容範囲内であれば、提出されたアノテーションを承認し、そうでない場合は、提出されたアノテーションを却下して、再度ヒューマン・アノテーターに差し戻します。
Human Annotationページにて、Testタスクをクリックします。

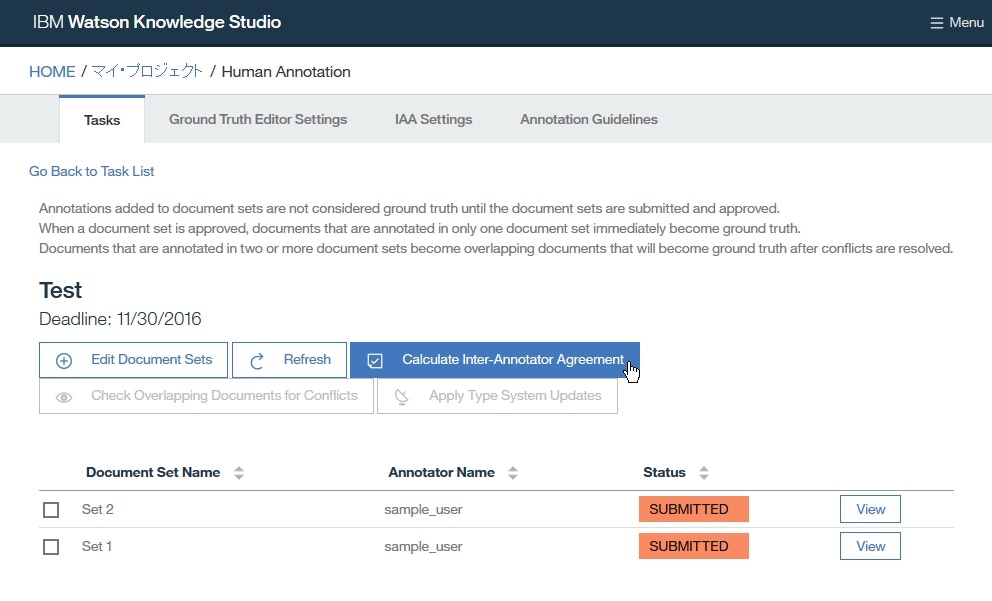
- 2つのドキュメントセット
Set 1とSet 2の状態がSUBMITTEDになっていることを確認した上で、Calcurate Inter-Annotator Agreementをクリックします。
- IAAスコアを表示します。このとき、画面上部の
Mention-Pairと表示されたドロップダウンを選択することで、表示を切り替えます。
Mention/Relation:entity/relationごとのIAAスコアを表示Pair/Document:アノテーター/ドキュメントごとのIAAスコアを表示
※上記画面では、Mention/RelationのドロップダウンでMentionを選択したことにより各entityごとのIAAスコアが表示され、さらにPair/DocumentのプルダウンでPairを選択したことによりアノテーターごとの比較をおこなっています(青枠部分に2人のアノテーターの名前が表示されます)。

- スコアを確認後、状態が
SUBMITTEDになっているドキュメントの隣に表示されているチェックボックスを選択して、Approve(承認)またはRejectを(却下)をクリックします。本チュートリアルではApproveを選択します。

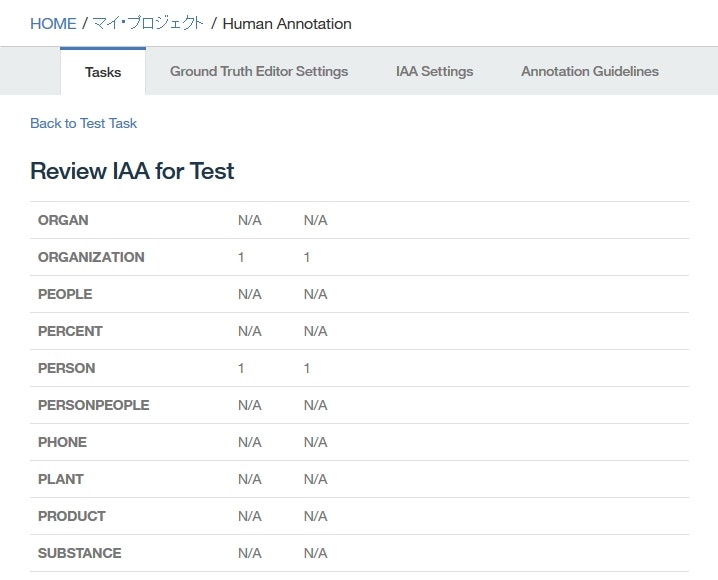
完全合意、すなわち2人のヒューマン・アノテーターがそのentityやrelationに対して同じアノテーションをした場合、IAAスコアは1となります。アノテーションを行わなかったものに対しては、IAAスコアはN/Aとなります。
チュートリアルの結果からは、2つのアノテーション間のIAAに関して、下記のことが読み取れます。
-
ORGANIZATION,PERSONentity typeのIAAには1(Set 1,Set 2で同じアノテーションを行ったため)
-
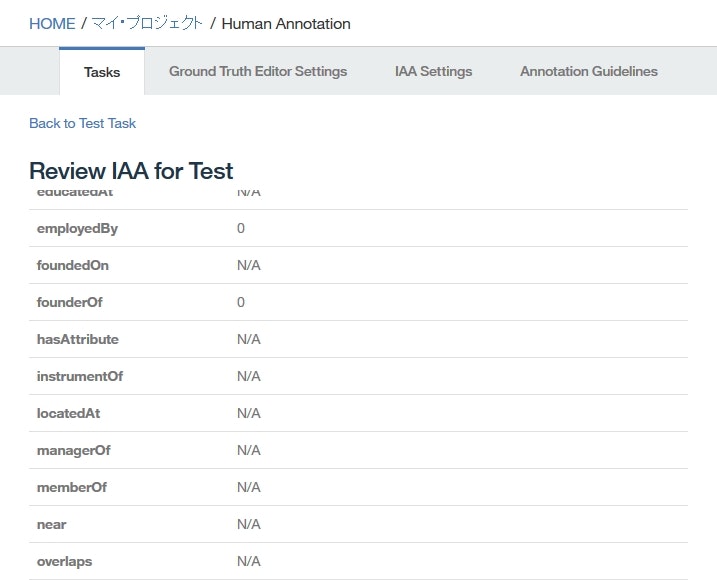
employedBy,founderOfrelation typeのIAAには0(Set 1,Set 2で異なるアノテーションを行ったため)
Lesson 11: アノテーション済ドキュメント間の競合の解消
ドキュメント間のアノテーションの競合を解消する方法を学習します。
「Lesson 10: アノテーター間合意分析」においてアノテーションを承認する場合、もしアノテーションに競合がある場合は承認前に競合を解消する必要があります。
Human Annotationページにて、Testタスクをクリックします。
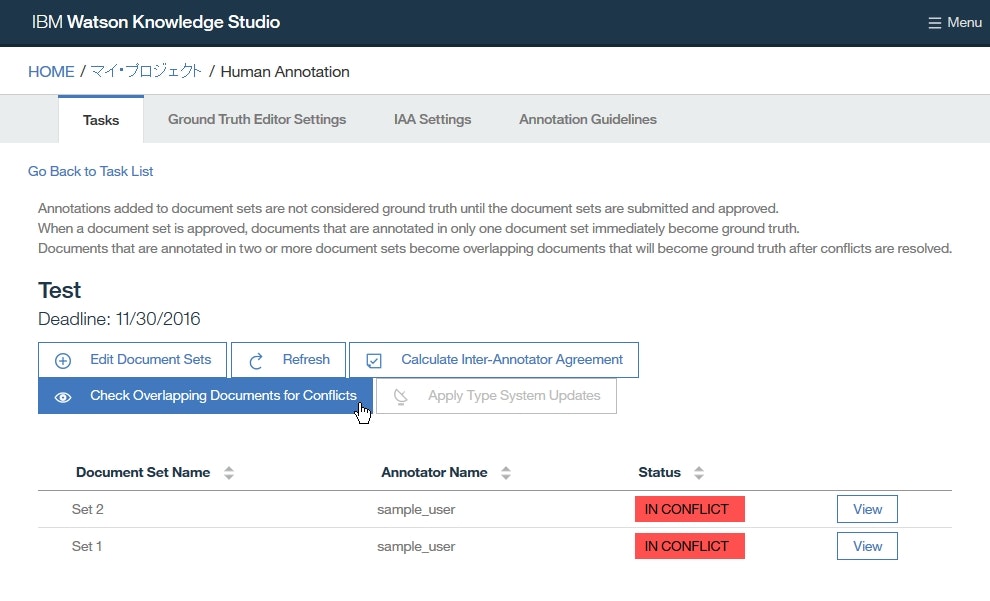
- 2つのドキュメントセット
Set 1とSet 2の状態がIN CONFLICTになっていることを確認した上で、Check Overlapping Documents for Conflictsを選択します。
Overlapping Documents in Task Testページにて、1つのドキュメントの横のCheck for Conflictsをクリックします。
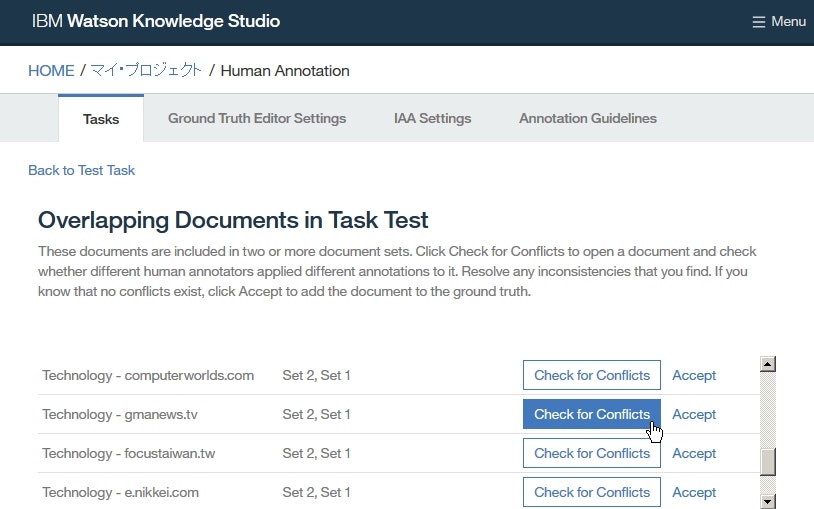
Set 1とSet 2を選択して、Check for Conflictsをクリックします。
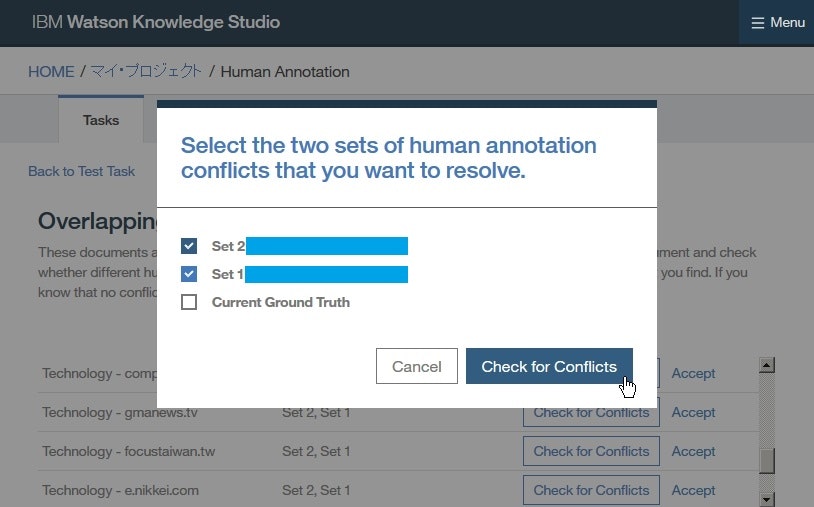
- 競合しているアノテーションの数を確認し、競合が存在した場合、そのアノテーションを削除または修正することにより競合を解消します。
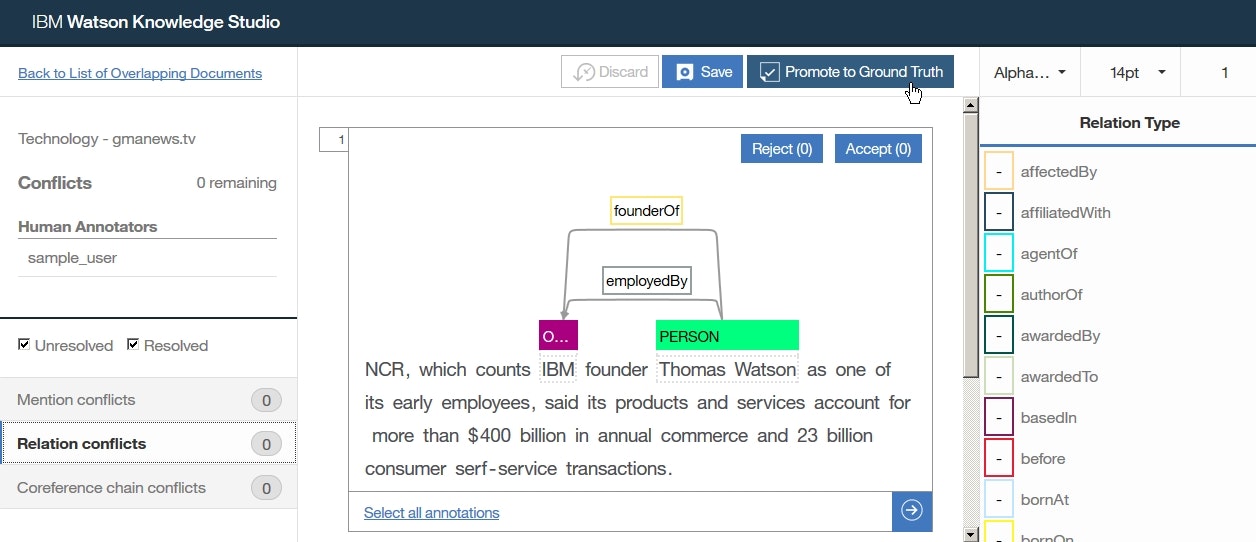
- 他のドキュメントに対しても、手順3. ~ 7.を繰り返し、アノテーションの競合を解消します。

Lesson 12: 機械学習アノテーターの作成
機械学習アノテーターを作成し、学習を行い、その結果を確認します。
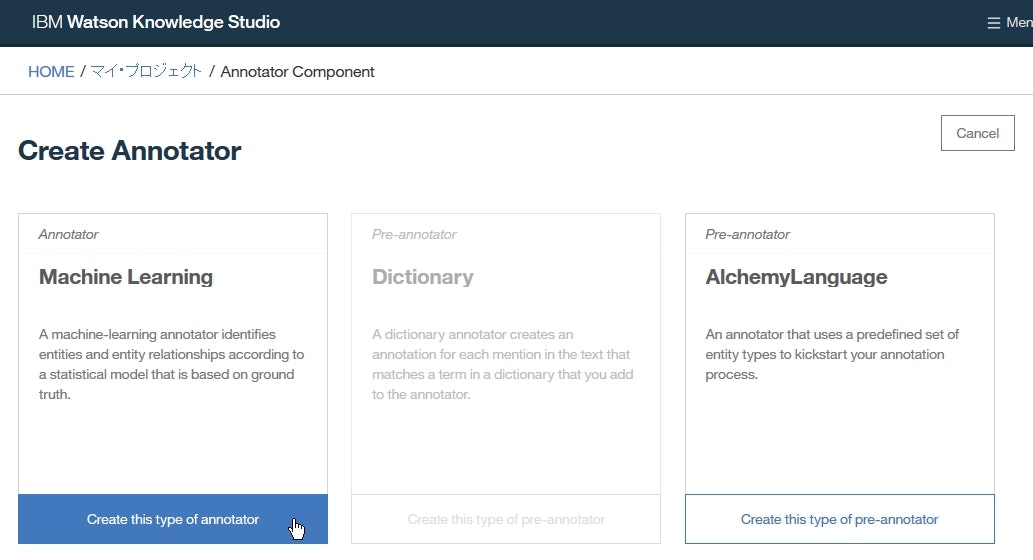
Annotator ComponentページにてCreate Annotatorをクリックします。
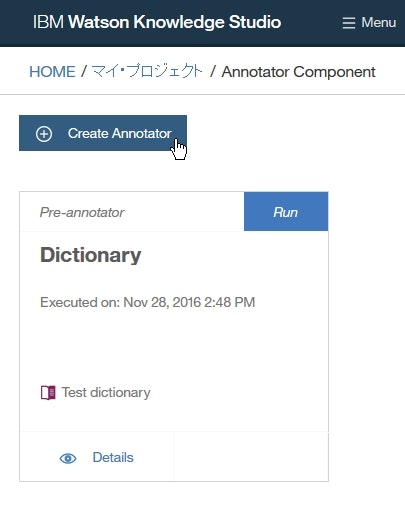
Create Annotatorページにて、Machine LeaerningボックスのCreate this type of pre-annotatorをクリックします。
- 学習に使用するドキュメントセットを指定するため、
Set 1とSet 2のチェックボックスを選択します。
さらに、これらのドキュメントセットを下記3種類のドキュメントに分けるため、それぞれの割合を指定し、Train & Evaluateをクリックします。
Training Set:まだ学習を行っていないアノテーターの学習を行うために使用されるドキュメントセット。Test Set:すでに学習を行ったアノテーターのテストを行うために使用されるドキュメントセット。Blind Set:アノテーターのテストと改善を何度か反復した後で、定期的にシステムのテストを行うために使用されるドキュメントセット。
※数値を入力するテキストボックスには推奨値(70%, 23%, 7%)がデフォルトで入力されていますが、ユーザーの判断で変更の必要がある場合には改めて入力し直します。
機械学習アノテーターの学習がはじまります。
ドキュメント内の単語の量やアノテーションの個数により、十数分から数時間程度かかることがあります。
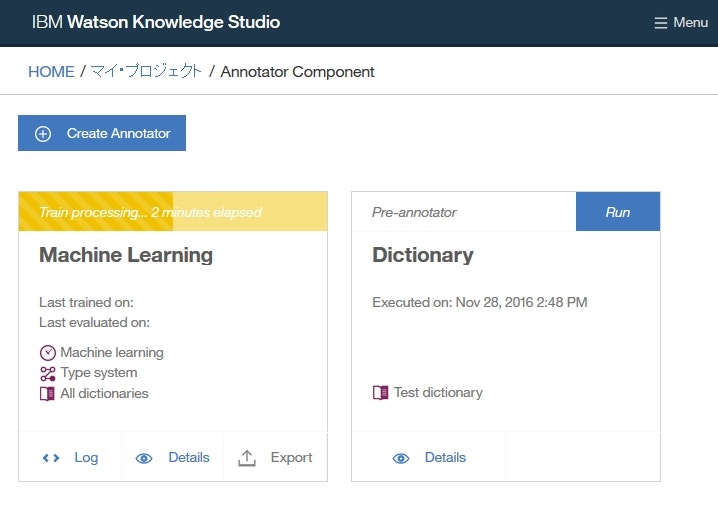

- 機械学習アノテーターの学習が終了した後、
Machine LeaerningボックスのDetailsをクリックします。

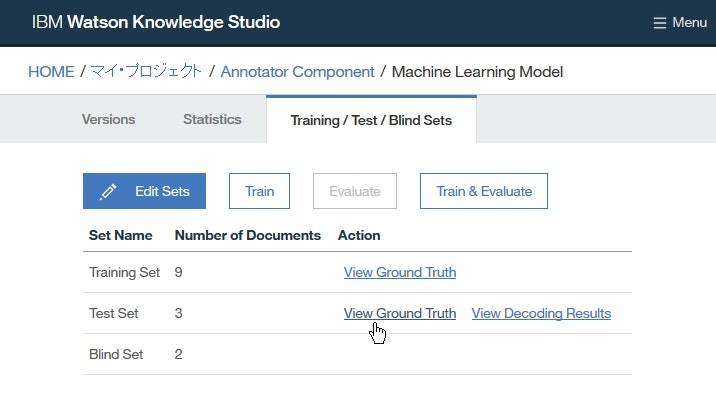
Train/Test/Buildページにて以下のボタンをクリックすると、それぞれ下記の操作をすることができます。
View Ground Truth:ヒューマン・アノテーションしたドキュメントの内容の確認View Decoding Result:学習済みの機械学習アノテーターが行ったアノテーションの確認
Statisticsページにて、各entityに対する機械学習アノテーションの精度(Precision)と再現度(Recall)、F1値(後述)といった統計情報を表示します。

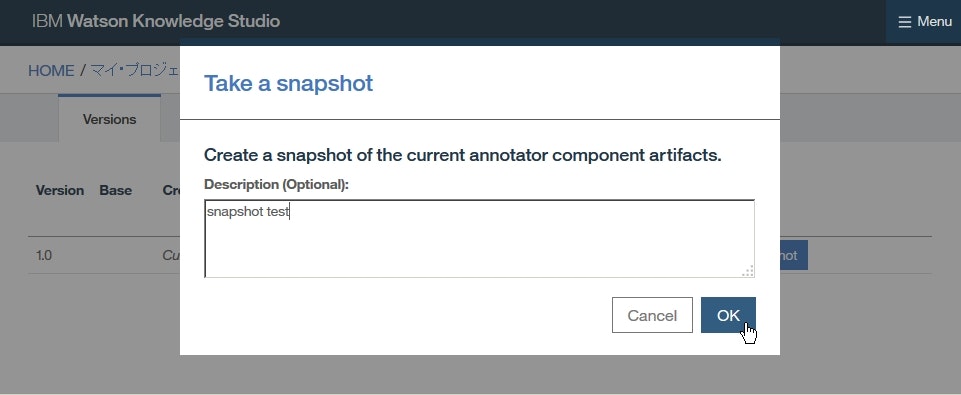
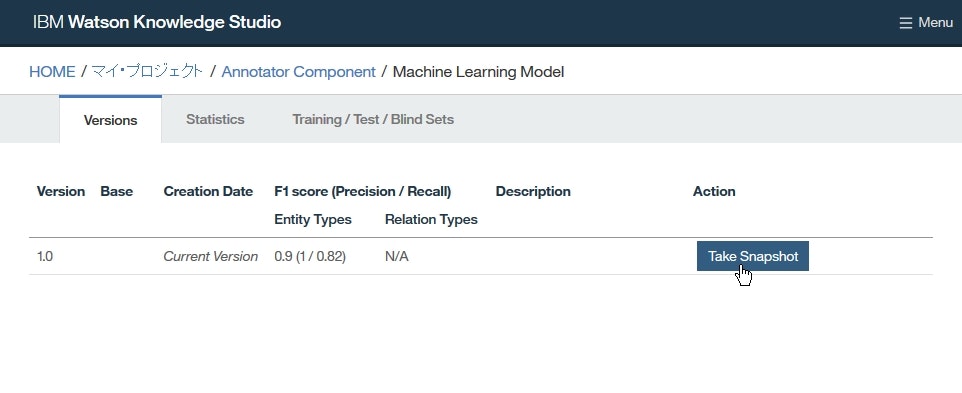
Versionページでは、アノテーターとその作成に使用されたリソース(辞書やアノテーション・タスクを除く)のスナップショットを作成できます。
たとえば、アノテーター変更前にスナップショットを作成し、アノテーション変更後に統計情報が悪い場合は、古いバージョンに戻し新しいバージョンを削除する、といった使い方ができます。
なお、各entityに対するアノテーションの精度と再現度、F1値の定義は下記のとおりです。
| 名称 | 変数(※) | 意味 |
|---|---|---|
| 精度 | $\displaystyle \mathrm{Precision}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}}$ | 実際にそのentityにアノテーションされた単語のうち、本来そのentityにアノテーションされるべきである単語の割合 |
| 再現度 | $\displaystyle \mathrm{Recall}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}}$ | 本来そのentityにアノテーションされるべきである単語のうち、実際にそのentityにアノテーションされた単語の割合 |
| F1値 | $\displaystyle \mathrm{F1}=\frac{2\cdot\mathrm{Precision}\cdot\mathrm{Recall}}{\mathrm{Precision}+\mathrm{Recall}}$ | 精度と再現度の調和平均 |
※ここで、各変数の定義は以下の通りです。
| 名称 | 変数 | 意味 |
|---|---|---|
| True Positive | $\mathrm{TP}$ | 本来そのentityにアノテーションされるべきであり、実際にそのentityにアノテーションされた単語の数 |
| True Negative | $\mathrm{TN}$ | 本来そのentityにアノテーションされるべきでなく、実際にそのentityにアノテーションされなかった単語の数 |
| False Positive | $\mathrm{FP}$ | 本来そのentityにアノテーションされるべきでなく、実際にそのentityにアノテーションされた単語の数 |
| False Negative | $\mathrm{FN}$ | 本来そのentityにアノテーションされるべきであり、実際にそのentityにアノテーションされなかった単語の数 |
Lesson 13: 機械学習アノテーターによるドキュメントの事前アノテーション
学習させた機械学習アノテーターを使用して、後から追加したドキュメントを機械学習アノテーションします。
さらに、機械学習アノテーションしたドキュメントにヒューマン・アノテーションによる修正を行い、修正したそのドキュメントを使用して機械学習アノテーターを再度学習させてみます。
- ドキュメント
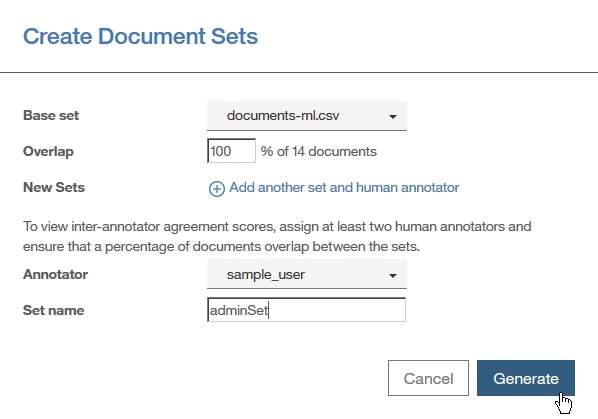
documents-ml.csvを追加し、下記設定でドキュメントセットを作成します(参考:Lesson 4: ドキュメントの追加、Lesson 5: ドキュメントセットの作成)。
Base Set欄:documents-ml.csvOverlap欄:100Annotator欄:sample_userSet Name欄:adminSet
Annotator Componentページにて、Machine LeaerningボックスのRunをクリックします。

Run Annotatorページにて、adminSetを選択して、Runをクリックします。
機械学習アノテーションが開始されます。


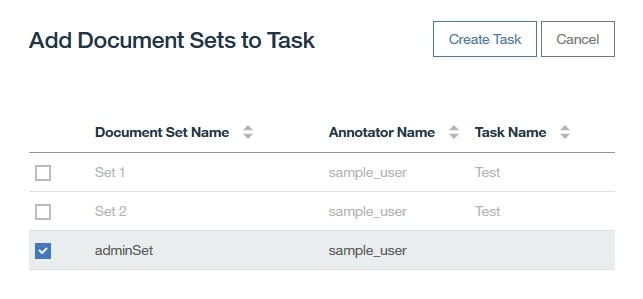
- 機械学習アノテーションが完了した後、アノテーション・タスク
Test2を作成し、ドキュメントセットadminSetをヒューマン・アノテーションして結果を保存した後、そのDocument Setを承認します(参考:Lesson 8: アノテーション・タスクの作成、Lesson 9: ドキュメントのアノテーション、Lesson 10: アノテーター間合意分析、Lesson 11: アノテーションしたドキュメント内の矛盾の解消)。


Annotator Componentページにて、Machine LearningボックスのDetailをクリックします。
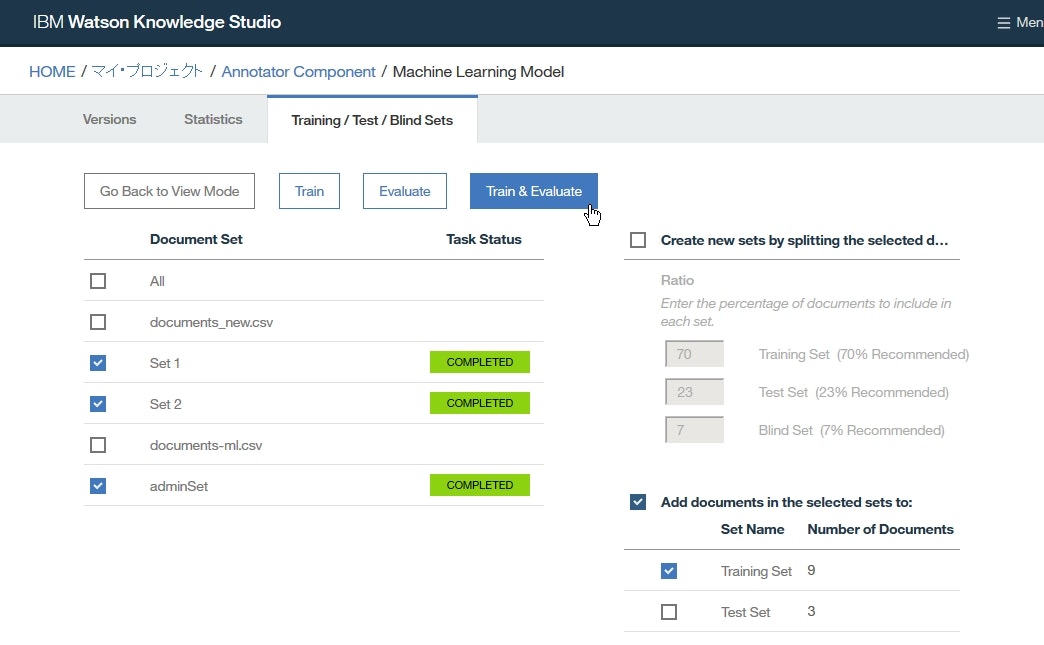
Train/Test/BuildページにてEdit Setsをクリックします。

- 追加したドキュメントセット
adminSet横のチェックボックスを選択して学習データに追加し、TRAINまたはTRAIN & EVALUATEをクリックします。
これにより、追加したドキュメントセットを含めて再度機械学習アノテーターの学習が始まります。
おわりに
前回(前編)と今回(後編)を通して、以上でWKSのチュートリアルを完了しました。type system、ドキュメントセット、辞書、アノテーションといった基本概念に始まり、アノテーションの種類(ヒューマン・アノテーション、辞書ベースアノテーション、機械学習アノテーション)、およびアノテーションの競合やその解消といった、WKSを使う上での基本的な流れをひととおりご覧いただけたかと思います。
前回(前編)で紹介したとおり、WKSで作成したモデルは、Watson ExplorerやAlchemy APIなどの他の多くのWatson製品と連携することができます。これに関しては、別記事にて詳しく紹介したいと思います。
お問い合わせ
ご質問がございましたら、こちらにもお問い合わせいただけます。
すくすくワトソン編集室: eb17685@jp.ibm.com