はじめに
Watson Knowledge Studio(以下、WKS)は、IBM Watsonにおいて、特定の業界に特化して用いられる言葉のニュアンス、意味や関係を理解する機械学習モデルを、開発者と専門家が協力して作成するクラウド・ベースのアプリケーションです。
Watson Developer CloudにはすでにWKSのチュートリアルが用意されています。本記事では前後編にわたり、このチュートリアルを実施します。
チュートリアルの前に
Watsonはベースとして保有している知識があるため、学習にかかるコストを少なく抑えることができます。しかし、各業界や専門分野(流通、製造、金融、医療、保険、法律・・・)の知識をはじめから完全に習得しているわけではないため、それぞれの分野の専門家の手で新たに学習させる必要があります。WKSはそのような作業を支援するツールです。
WKSには次のような特長があります。
-
直感的なユーザーインターフェース:WKSでは、わかりやすく可視化された直感的な最新のユーザーインターフェースが提供されています。これにより、操作に不慣れな初心者でも、高度なコーディングなどをすることなく、かんたんに機械学習モデルの正解データを作成することができます。
-
共同作業によるモデルの改善:WKSでは、対象分野の専門知識や自然言語の微妙な違いをWatsonに入力する作業を複数の専門家で協力して実施し、各専門家が入力した内容を比較したり妥当性を確認したりすることができます。これにより、機械学習モデルの精度を向上させることができます。
-
機械学習によるモデルの改善:WKSでは、機械学習を活用して学習データの拡張を行います。これにより、人間が一から十まですべてWatsonに覚え込ませる必要はなく、ある程度の量だけを学習させるだけで十分となり、少し異なる知識であれば自動的に類推し応用してくれるようになります。
-
多くのWatsonソリューションとの連携:WKS上で作成したモデルは、他の多くのWatson製品と連携することができます。たとえば、モデルをWatson Explorerにインポートすると、そのモデルをドキュメントの分析に使用することができ、モデル内の単語の種類や単語間の関係などの情報から、様々な角度からの分析結果を自動的に作成してくれるようになります。
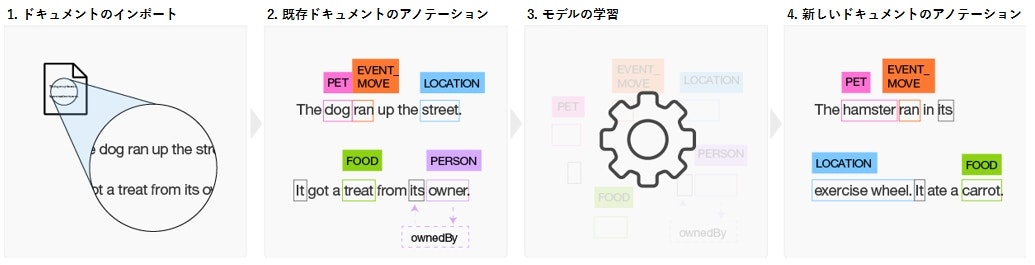
WKSを使用する流れはおおまかに次のようになります。
-
ドキュメントのインポート:対象となる業界のドキュメントを集めたものをWKSにインポートします。
-
既存ドキュメントのアノテーション]:そのドキュメントに登場する単語の分類(entity)と単語間の関係(relation)を定義するtype systemを作成し、このtype systemに基づいてドキュメントに登場する単語に正解データを付与(アノテーション)します。
(例)犬(dog)を「ペット(PET)」に分類する。 -
モデルの学習:正解データを利用してモデルの反復学習を行い、モデルの精度を改善します。
-
新しいドキュメントのアノテーション:得られたモデルを利用して、未知の新しいドキュメントをアノテーションします。
(例)犬(dog)を「ペット(PET)」に分類していたことから、ハムスター(hamster)も「ペット(PET)」に分類する。
ここで、いくつか出てきた用語について解説します。
※entity, relationは以下の記事でも登場しましたが、後述する通り、本記事で登場するものは同じ概念と考えて差し支えないものです。
アノテーション
アノテーションとは、ドキュメントに含まれるテキストに対して「正解データ」を付与する作業です。
例として、チュートリアルで用いるドキュメントdocuments-new.csv(英語)のTechnology - gmanews.tv`の一部(日本語訳)を以下に示します。
NCR, which counts IBM founder Thomas Watson as one of its early employees,...
IBMの創始者であるトーマス・ワトソンを初期の従業員の1人として数えているNCRは、・・・
WKSにおけるアノテーションは、たとえば、上記ドキュメントのテキストに対して、
-
IBMは「組織(ORGANIZATION)」の一種である。→分類 -
トーマス・ワトソン(Thomas Watson)は「人(PERSON)」の一種である。→分類 -
トーマス・ワトソン(Thomas Watson)はIBMの創始者(founder)である。→関係 - ……
といった、単語の分類(entity)や単語間の関係(relation)といった情報を付与する作業になります。このような、単語の分類や単語間の関係の種類を定義するのが、後述のtype systemと呼ばれるものです。
アノテーションを行う主体をアノテーターといいます。とくに、人間の手でアノテーションを実施する場合はヒューマン・アノテーター、機械学習によりアノテーションを実施する場合は機械学習アノテーターなどと呼びます。
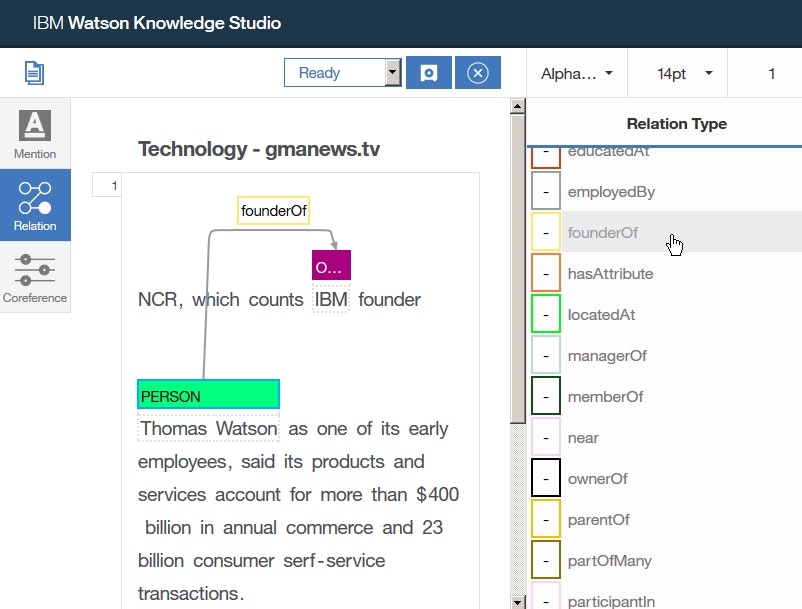
WKSではドキュメントのアノテーションをGUIで行うことができます。各単語の分類は色分けして表示され、各単語間の関係は単語を結ぶ矢印によって表示されます。これらの設定はマウスによるテキスト選択やボタン操作によって手軽に実施することができます。下の図は、先ほどご紹介したテキストを実際にアノテーションしている例です。IBMは組織(Organization)、トーマス・ワトソン(Thomas Watson)は人(PERSON)に分類され、トーマス・ワトソン(Thomas Watson)はIBMの創始者(founder of)として矢印で関連付けられています。
Type System
type systemは、アノテーションの際にドキュメントに付与する情報の種類の定義であり、単語の分類を表すentity typeと、異なるentity間の関係を表すrelation typeからなります。

Entity Type
entity typeは単語の種類を分類したものです。以下例を示します。
-
メアリー(Mary),ボブ(Bob),トーマス・ワトソン(Thomas Watson),オバマ大統領(President Obama)などは、人(PERSON)entity typeとしてアノテーションされます。 -
IBM,Google,Microsoftは、組織(ORGANIZATION)entity typeとしてアノテーションされます。
entity typeは以下2つの属性によって、さらに細かく分類されます。
- Role: entity typeを文脈によって定義づけるものです。
- Entity Subtype: entity typeをさらに分類するものです。
例として、チュートリアルで用いるKLUE type system(※)en-klue2.zipの52個のentity typeのうち一部を以下に示します。
※KLUE(Knowledge from Language Understanding and Extraction)はニュース記事のコレクションに基づいたtype systemであり、多くの機械学習モデルにおける基本的なtype systemとして利用されています。
| Entity Type Name | Roles | Subtypes |
|---|---|---|
| GPE(※1) | GPE, LOCATION, ORGANIZATION, PEOPLE, PERSON, PERSONPEOPLE | OTHER, UNSPECIFIED, AREA, COUNTRY |
| MONEY | MONEY | OTHER, UNSPECIFIED, WORTH, GAINLOSS |
| ORGANIZATION(※2) | ORGANIZATION, FACILITY, PEOPLE, PRODUCT, TICKER, TITLEWORK | OTHER, UNSPECIFIED, MULTIGOV, GOVERNMENT, COMMERCIAL, EDUCATIONAL, POLITICAL, RELIGIOUS, SPORTS, MILITARY |
| … | … | … |
※1 GPE(Geo-Political Entity):なんらかの政治的構造に関連する地理的領域のこと。
※2 1つのentityに対して、複数のentity subtypeやroleを定義できます。以下例を示します。
-
組織(ORGANIZATION)entityのroleには、組織(ORGANIZATION)の他にも施設(FACILTY)などが含まれています。IBMという単語は組織(ORGANIZATION)entity typeとしてアノテーションされますが、IBMで研修をおこなうという文では施設という役割を果たしています。
-
組織(ORGANIZATION)entityのsubtypeには、政府(GOVERNMENT)、教育(EDUCATIONAL)、宗教(RELIGIOUS)などが含まれています。国会(parliament)、大学(university)、教会(church)などは組織(ORGANIZATION)entity typeとしてアノテーションされるとともに、国会(parliament)は政府(GOVERNMENT)、大学(university)は教育(EDUCATIONAL)、教会(church)は宗教(RELIGIOUS)entity subtypeとしてアノテーションされます。
Relation Type
2つのentity間の順序付けられた関係を定義します。以下例を示します。
-
メアリーはIBMで働いている(Mary works for IBM)という文からは、~で働いている(employedBy)relation typeがアノテーションされます。 -
IBMの創始者であるトーマスワトソン(IBM founder Thomas Watson)という文からは、~の創始者である(founderOf)relation typeがアノテーションされます。
例として、チュートリアルで用いるKLUE type systemen-klue2.zipの2177個のrelation typeのうち一部を以下に示します。
| Relation Type | First Entity Type / Role | Second Entity Type / Role |
|---|---|---|
| colleague | PEOPLE, PERSON, PERSONPEOPLE | PEOPLE, PERSON, PERSONPEOPLE |
| employedBy | PEOPLE, PERSON, GPE, PERSONPEOPLE | GPE, WEB, PERSONPEOPLE, PERSON, PEOPLE, ORGANIZATION |
| founderOf | GPE | ORGANIZATION |
| founderOf | PERSON, PEOPLE, PERSONPEOPLE | FACILITY, ORGANIZATION, WEB, GPE |
| … | … | … |
一部のrelation typeでは、entityの順序が重要になります。以下、例を示します。
-
~で働いている(employedBy)relation typeでは、メアリーはIBMで働いている(Mary employedBy IBM)は有効ですが、IBMはMaryで働いている(IBM employedBy Mary)は無効です。 -
~の同僚である(colleague)relation typeでは、メアリーはボブの同僚である(Mary colleague Bob)もボブはメアリーの同僚である(Bob colleague Mary)も有効です。
辞書
辞書には、ドキュメントで使用される単語の見出し語とその類義語、品詞が含まれています。
例として、チュートリアルで用いる、ORGANIZATIONentityに対する辞書データdictionary-items-organization.csvの一部を以下に示します。
| Lemma(見出語) | Surface Forms(類義語) | Part of Speech(品詞) |
|---|---|---|
| Apple | Apple Inc., Apple | Noun(名詞) |
| British Academy | BAFTA/LA, British Academy | Noun(名詞) |
| Burger King | Burger King Holdings Inc., Burger King | Noun(名詞) |
| … | … | … |
チュートリアル
いよいよ、チュートリアルを実施します。
チュートリアルは下記のような13個のLessonから構成されています。
本記事ではこのチュートリアルを下記の通り前後編に分けて実施します。
- 前編(今回)
- Lesson 1: ユーザーロールの割り当ての確認
- Lesson 2: プロジェクトの作成
- Lesson 3: type system の作成
- Lesson 4: ドキュメントの追加
- Lesson 5: ドキュメントセットの作成
- Lesson 6: 辞書の追加
- 後編(次回)
- Lesson 7: 辞書ベースアノテーターによる事前アノテーション
- Lesson 8: アノテーション・タスクの作成
- Lesson 9: ドキュメントのアノテーション
- Lesson 10: アノテーター間合意分析
- Lesson 11: アノテーション済ドキュメント間の競合の解消
- Lesson 12: 機械学習アノテーターの作成
- Lesson 13: 機械学習アノテーターによる事前アノテーション
推奨環境は次のとおりです。
- ブラウザ:Mozilla Firefox, Google Chrome(最新版)
Lesson 1: ユーザーロールの割り当ての確認
WKSユーザーとして登録されているすべてのユーザーIDを一覧表示させ、チュートリアル中の作業を実施する上で必要な権限が付与されているか確認します。
各ユーザーIDは、次の3つの役割のいずれかを持ちます(権限は上にいくほど強くなります)。
- SUPER_USER:WKSインスタンス上のすべてのプロジェクトで「アノテーションプロセスマネージャ(※)」として機能し、さらにヒューマン・アノテーターとしても機能します。
- MASTER_ADMINISTRATOR:WKSインスタンス上の自分が作成したプロジェクトで「アノテーションプロセスマネージャ」として機能し、さらにヒューマン・アノテーターとしても機能します。
- HUMAN_ANNOTATOR:ヒューマン・アノテーターとして機能しますが、割り当てられたドキュメントセットのみを表示できます。
※アノテーションプロセスマネージャは、プロジェクトの作成にはじまり、ドキュメントセットに対するヒューマン・アノテーターの割り当て、アノテーションの承認や競合の解消、機械学習アノテーションの実行などを行うことができます。
実際のプロジェクトでは複数のHUMAN_ANNOTATORによってアノテーションが実施されますが、このチュートリアルではSUPER_USER権限をもつユーザーID1つのみを使用することとします。
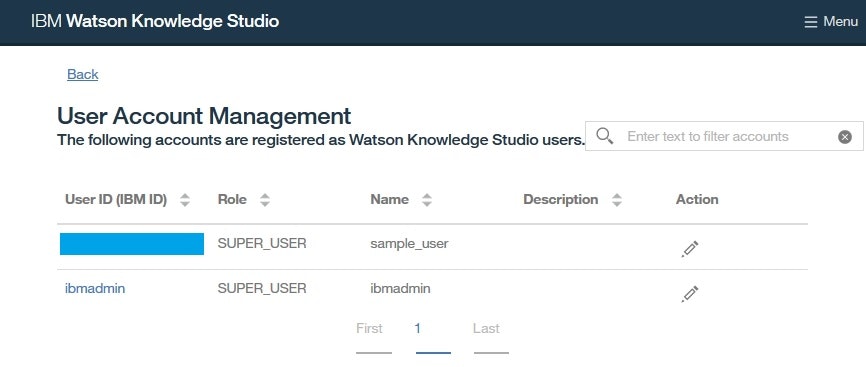
- WKSインスタンスにアクセスします。
- 右上の
MenuからSettingsをクリックしてUser Account Managementページを開きます。

- 自分のユーザーIDが
SUPER_USERロールをもつことを確認します。
Lesson 2: プロジェクトの作成
プロジェクトを作成します。
プロジェクトは、type system、ドキュメント、辞書、ヒューマン・アノテーターによって追加されるアノテーションなど、機械学習アノテーターを作成するために必要なすべての要素を定義するものです。
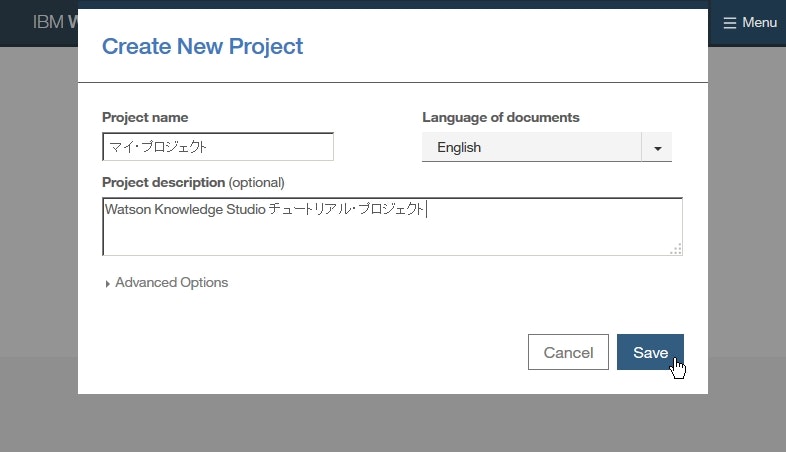
Create New Projectをクリックします。

- プロジェクトの詳細を下記のように設定し、
Saveをクリックします。
Project Name欄:マイ・プロジェクトProject descrription欄:Watson Knowledge Studio チュートリアル・プロジェクトLanguage of Documents:English
Lesson 3: Type Systemの作成
type systemを作成します。本チュートリアルではサンプルとしてKLUE type systemen-klue2.zipをダウンロードしてインポートします。
さらにそれに対して編集をかけてみます。ここでは、MONEYentity typeのroleからAWARDroleを削除してみます。
en-klue2.zipをダウンロードします。
Type SystemページにてImportをクリックします。
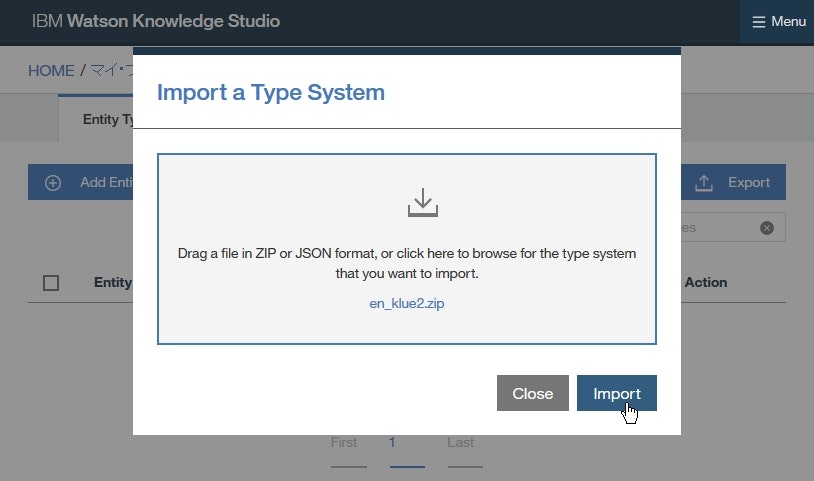
- ダウンロードした
en-klue2.zipをウインドウ内へドラッグアップドロップして、Importをクリックします。
インポートされたtype systemが表に表示されます。
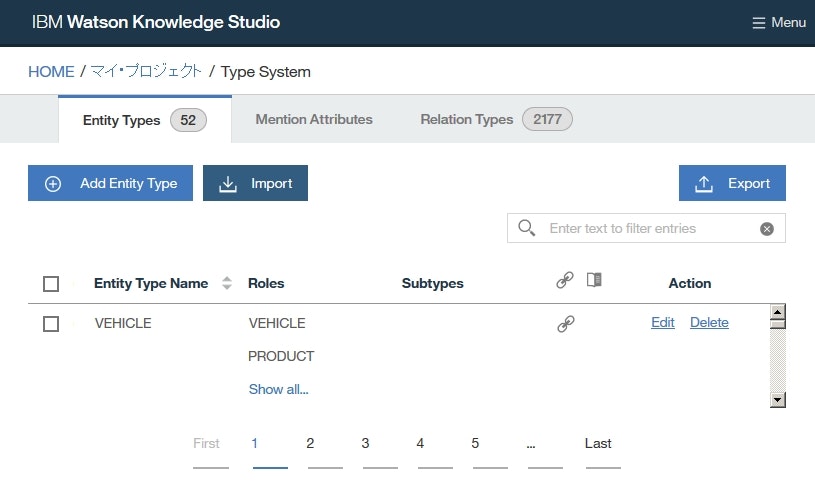
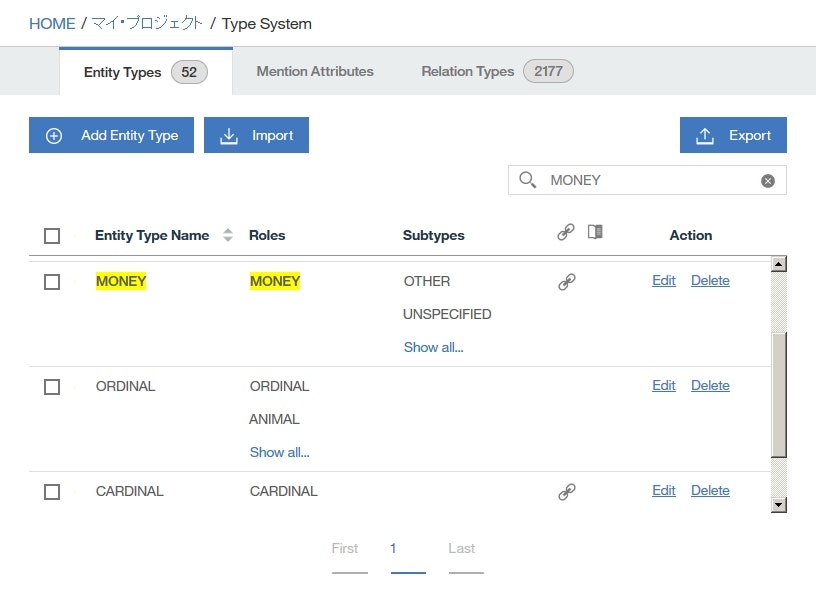
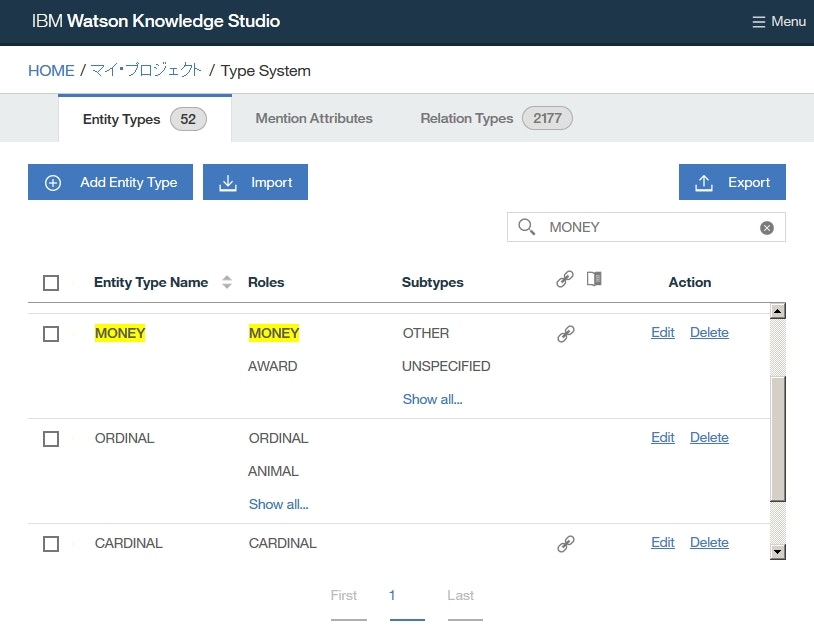
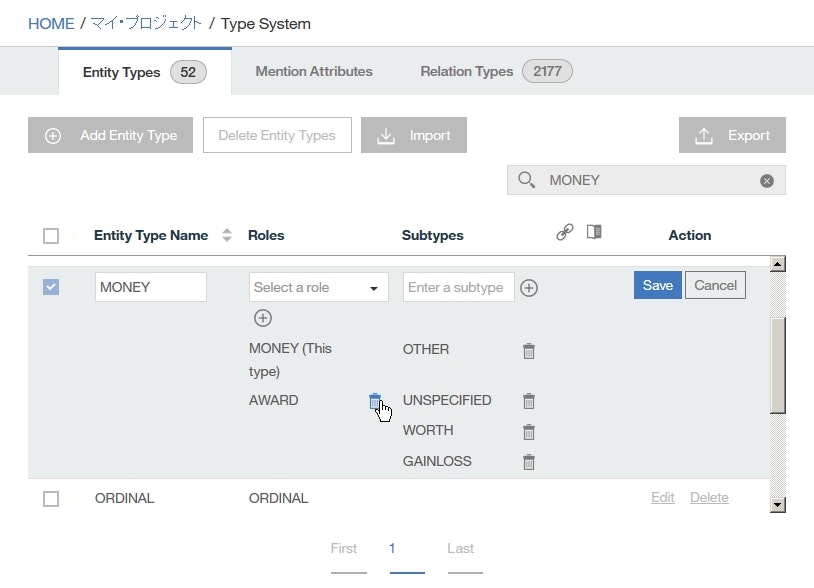
MONEYentity typeを検索して表示し、MONEY行内をダブルクリックします。
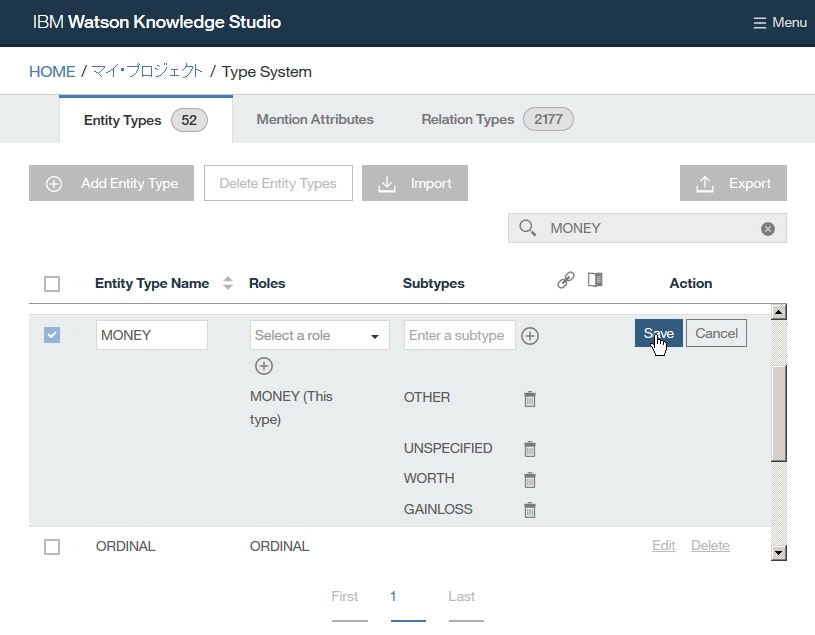
Roles列のAWARD行の削除(Delete a role)アイコンをクリックして、Saveをクリックします。
↓
↓
↓
Lesson 4: ドキュメントの追加
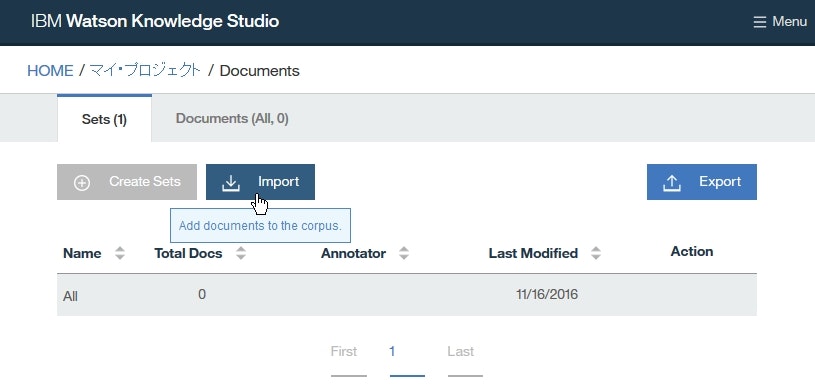
ドキュメントを追加します。本チュートリアルではサンプルとしてドキュメントdocuments-new.csvをダウンロードしてインポートします。
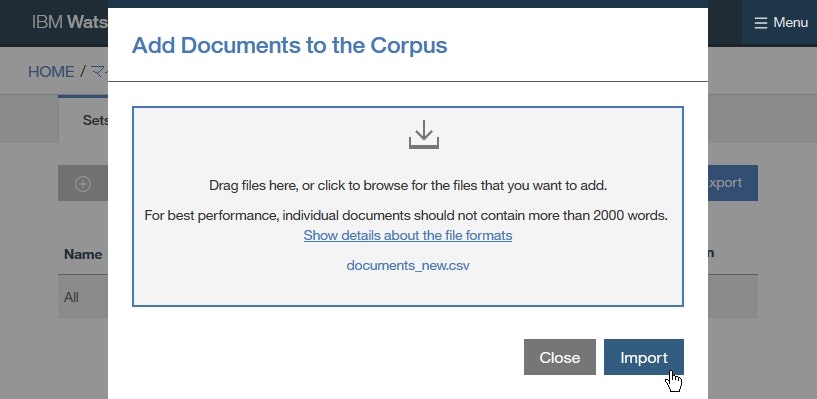
documents-new.csvをダウンロードします。DocumentsページにてImportをクリックします。
- ダウンロードした
documents-new.csvをウインドウ内へドラッグアップドロップして、Importをクリックします。
インポートされたドキュメントが表に表示されます。
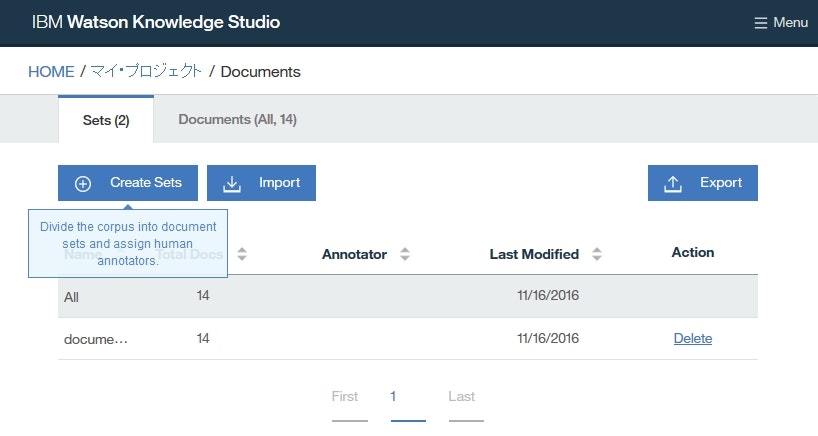
Lesson 5: ドキュメントセットの作成
Lesson 4でインポートしたドキュメントからドキュメントのひとかたまり(ドキュメントセット)を作成し、そのドキュメントのひとかたまりに対して、それをアノテーションする担当者(ヒューマン・アノテーター)を割り当てます。
実際のプロジェクトでは、ヒューマン・アノテーターごとにアノテーションの差異が出るため、同一ドキュメントから複数のドキュメントセットを作成してそれぞれを異なるヒューマン・アノテーターに割り当てることがよくあります。しかし、複数のユーザーIDが使用できない場合は、複数のドキュメントセットを同じヒューマン・アノテーターに割り当てることができます。このチュートリアルでは、2つのドキュメントセットを作成し、同じユーザーを2つのドキュメントセットに割り当てています。
なお、次回(後編)で扱うLesson 10: アノテーター間合意分析において、アノテーター間スコアを使用して各アノテーターごとのアノテーションを比較するには、少なくとも2人のヒューマン・アノテーターを異なるドキュメントセットに割り当てる必要があります。また、ドキュメントの一部がドキュメントセット間で重複するように指定する必要があります。
DocumentsページにてCreate Setをクリックします。
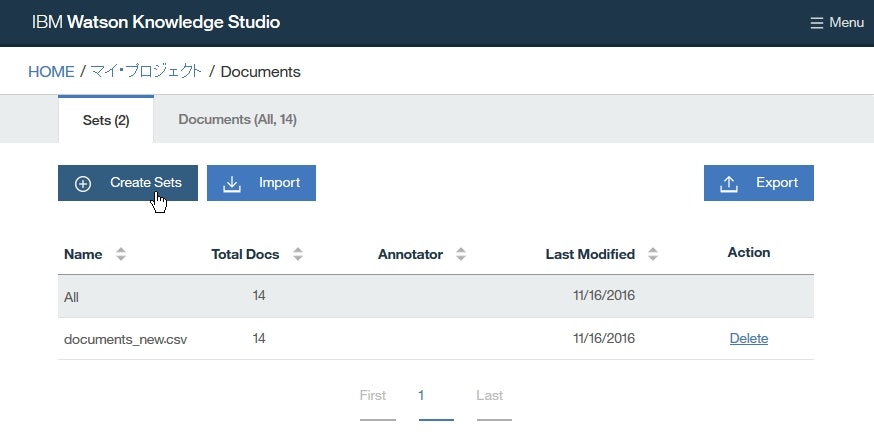
Create Documents Setsウインドウにて、(+)Add another set and human annotatorをクリックして新たなドキュメントセット用の欄を追加します。
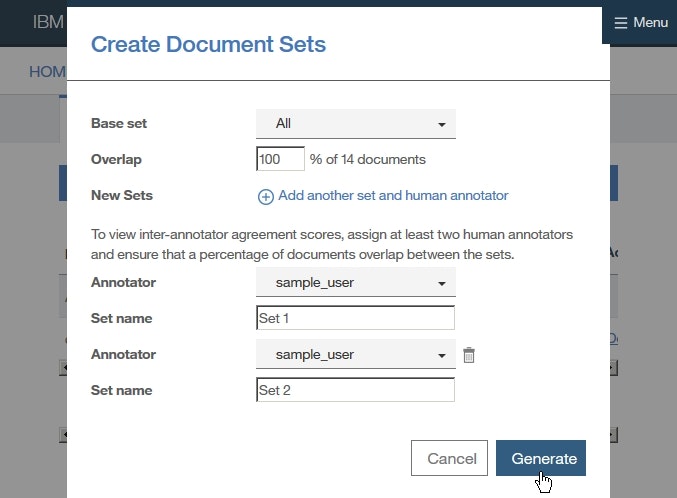
さらに、作成する新しいドキュメントセットごとに、必要な情報を下記のように指定し、Saveをクリックします。
Overlap欄:100Annotator欄:sample_userSet Name欄:Set 1Annotator欄:sample_userSet Name欄:Set 2
新しいドキュメントセットが作成され、
Documentsページの表に表示されます。
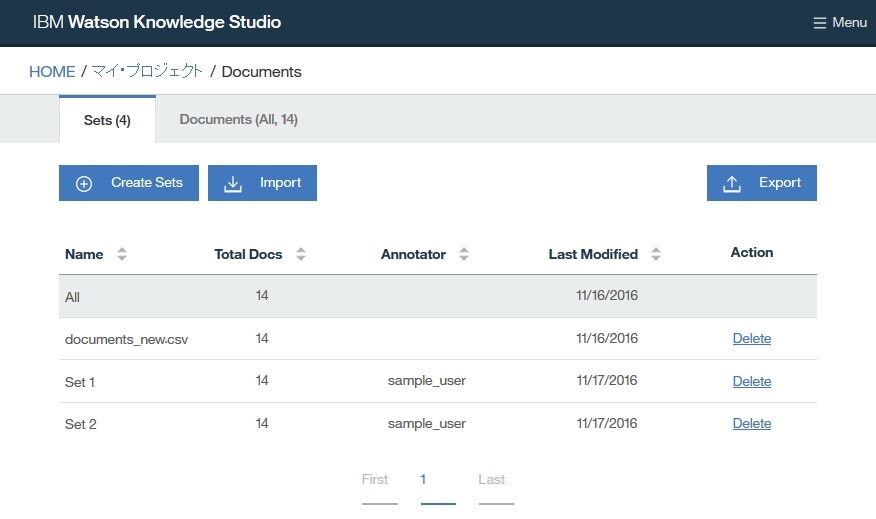
上記設定では、2つのドキュメントセットSet 1、Set 2が作成され、それぞれにヒューマン・アノテーターとしてsample_userを割り当てています。さらにOverlap欄に100を指定することにより、すべてのドキュメントが新しいドキュメントセットに含まれて、すべてのアノテーターによってアノテーションされるようになります。
なお一般に、ドキュメント$N$個をドキュメントセット$M$個に分割する場合にOverlap欄に$p(=0,1,…,100)$を指定すると、元のドキュメント$N$個のうち$p$%がすべてのドキュメントセットに含まれ、残りが$M$等分されて各ドキュメントセットに含まれるようになります。
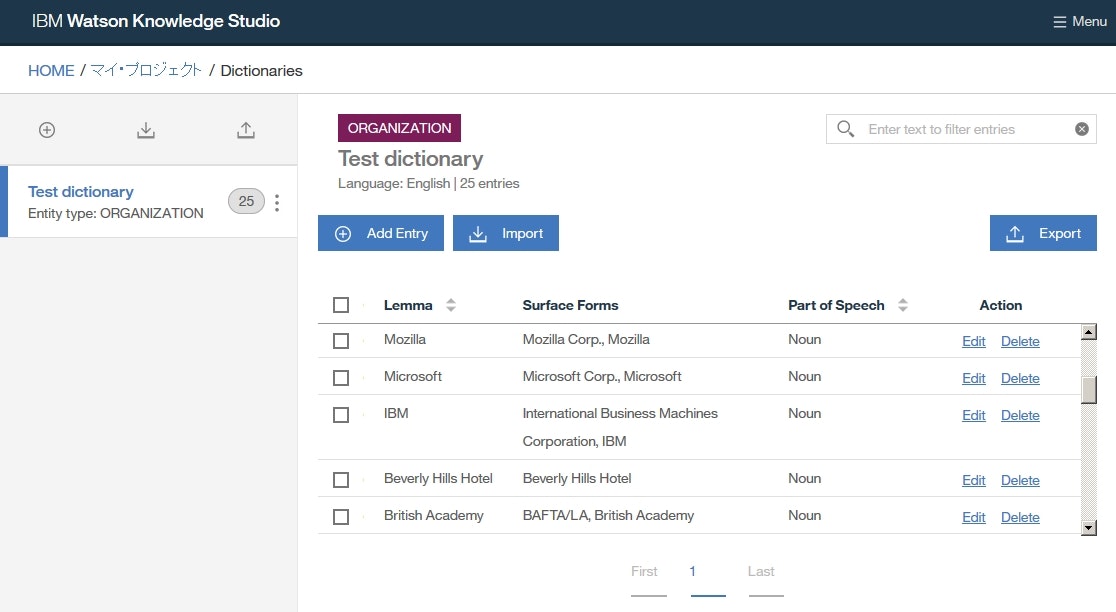
Lesson 6: 辞書の追加
辞書を追加します。さらに、追加した辞書に、見出語のIBMを新たに追加します。
WKSに辞書を追加する際は、CSV形式のファイルを用意します。
今回のチュートリアルでは、dictionary-items-organization.csvという辞書ファイルをダウンロードして使用します。
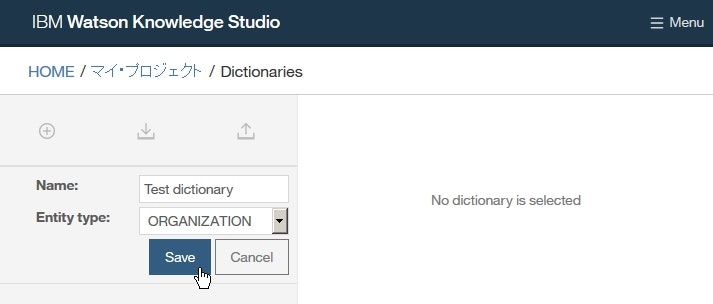
dictionary-items-organization.csvをダウンロードします。Documentsページにて+アイコンをクリックして辞書を追加し、各欄に以下を入力して、Saveをクリックします。
Name欄:Test DictionaryEntity Type欄:ORGANIZATION
Importをクリックします。
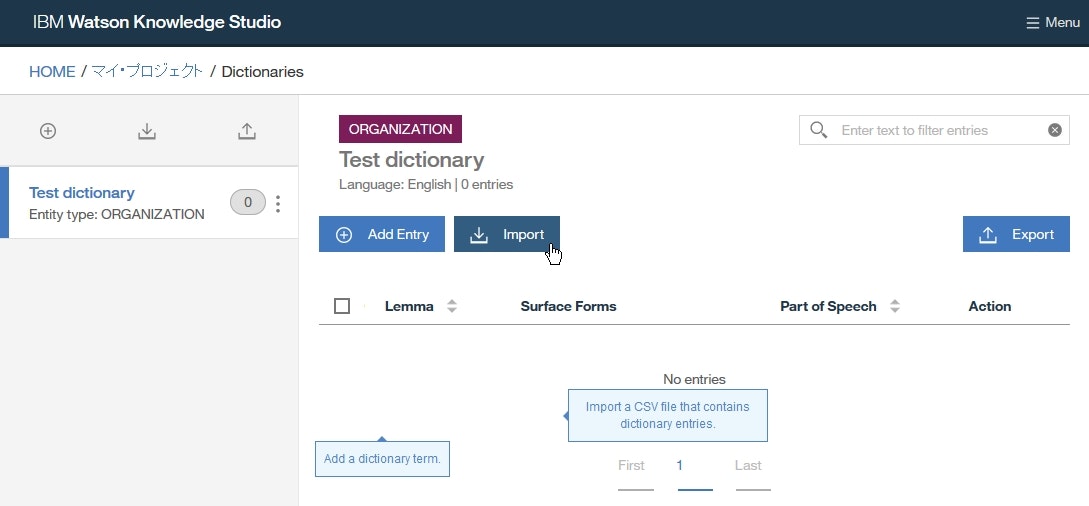
- ダウンロードした
dictionary-items-organization.csvをウインドウ内へドラッグアップドロップして、Importをクリックします。
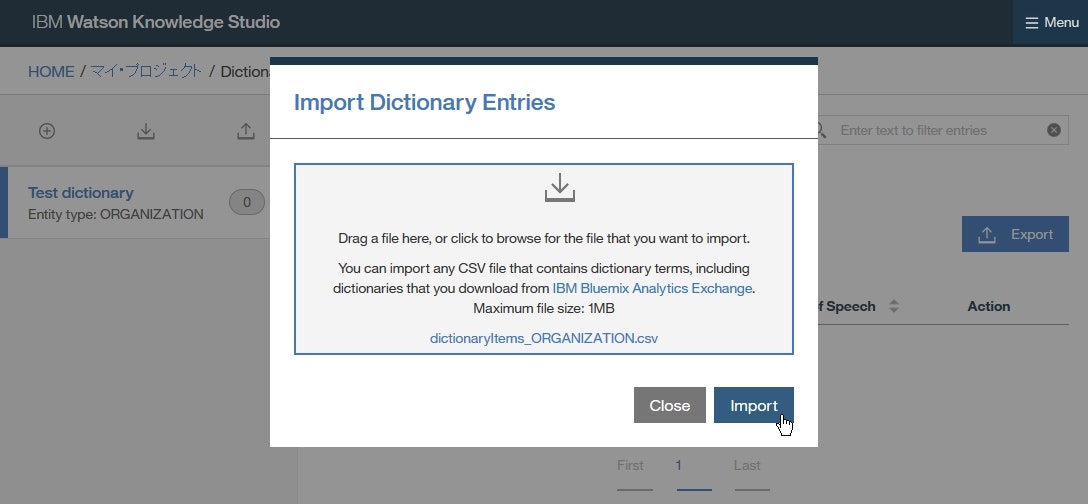
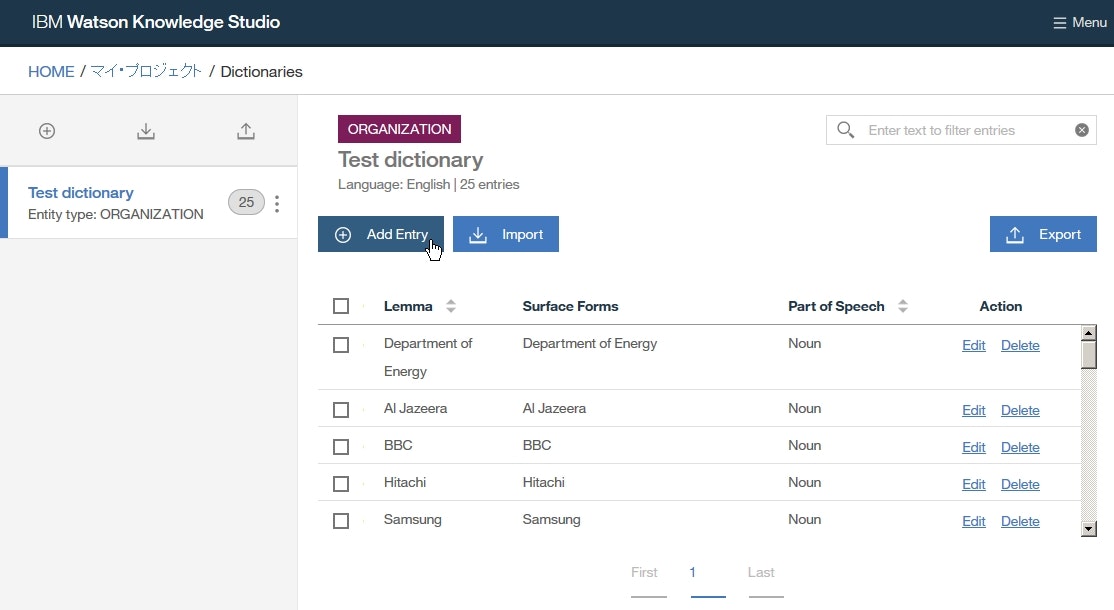
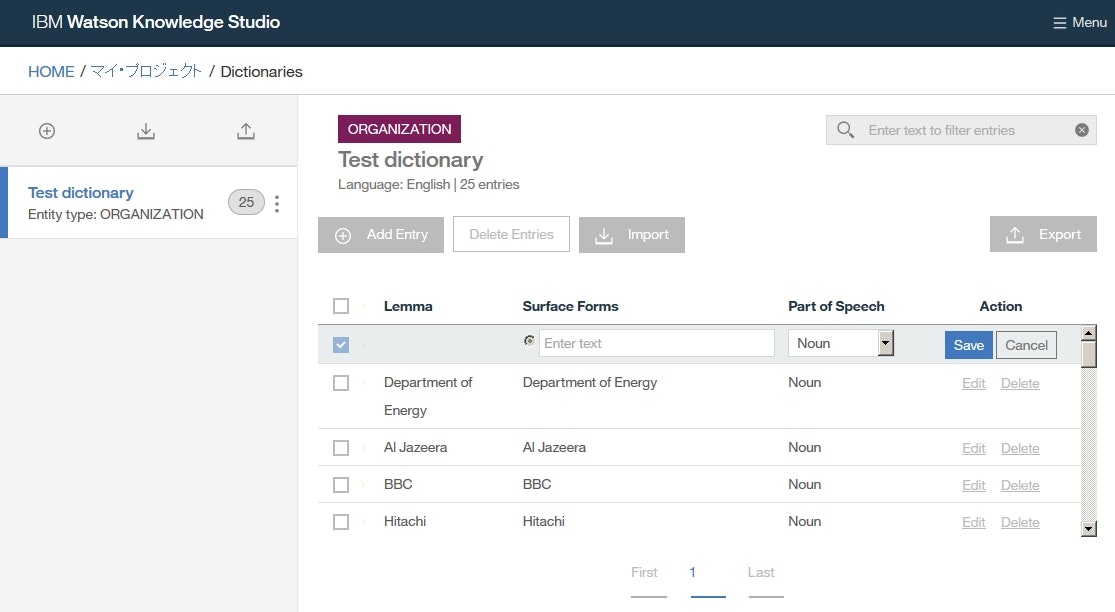
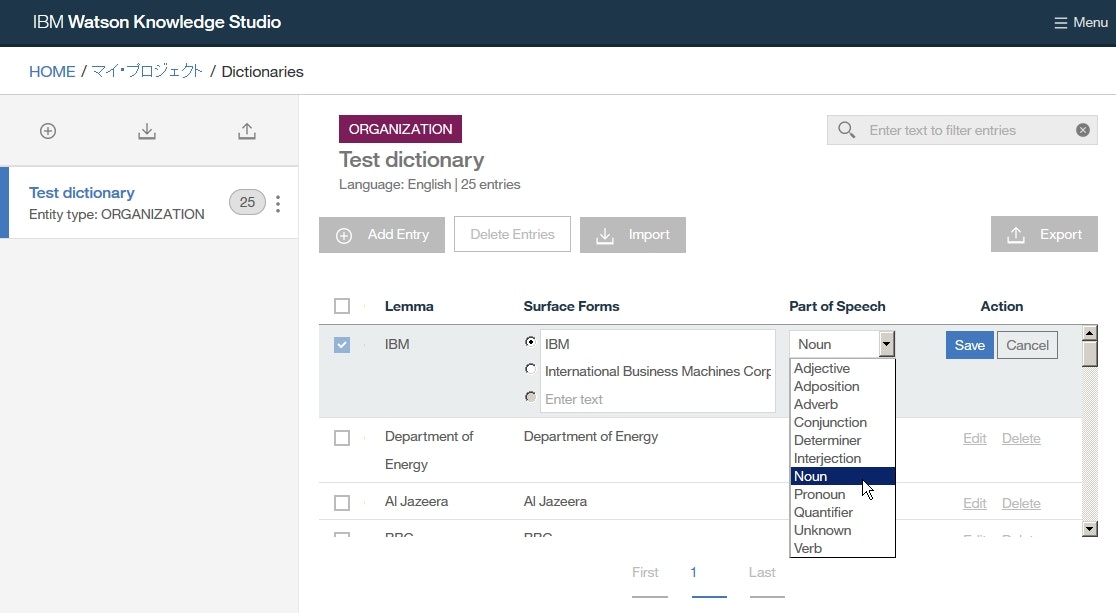
Add Entryをクリックし、各欄に以下を入力して、Saveをクリックします。
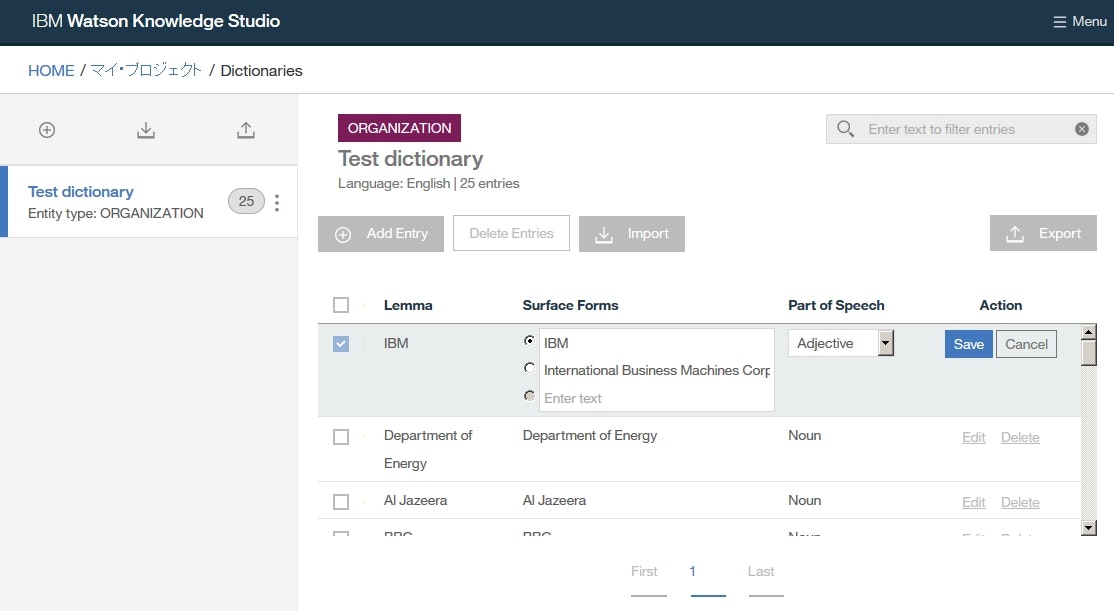
Surface Forms列にIBMおよびInternational Business Machines Corporationと入力します。- ラジオボタンを
IBMにセットします。Part of Speech欄にてNounを選択します。
↓
↓
↓
↓
↓
おわりに(後編に向けて)
今回(前編)では、WKSプロジェクトを作成して、type system作成、ドキュメント追加、ドキュメントセット作成、辞書の追加を実施しました。ここまでの手順で、ドキュメントのアノテーションの準備が整ったことになります。
次回(後編)では、この状態からアノテーションを実施します。
お問い合わせ
ご質問がございましたら、こちらにもお問い合わせいただけます。
すくすくワトソン編集室: eb17685@jp.ibm.com