ファイル名を日本語でダウンロードさせるためには、User-Agentを見てContent-Dispositionヘッダのfilenameの書式や文字コードを書き換える方法1がよく知られていますが、今回はUser-Agentに頼らず日本語ファイル名ダウンロードをクロスブラウザ対応する方法を紹介したいと思います。
概要
- User-Agentで分岐して
Content-Dispositionヘッダを出すことはしない - ブラウザがURLからファイル名を決める仕様を活用する
- ダウンロードURLのPATH_INFOに日本語ファイル名を入れる
ブラウザはファイルを保存するとき、何を参考にしているか?
ブラウザがウェブ上のリソースをローカルに保存するとき、必ずファイル名をつけるわけですが、そもそもブラウザは何を参考にして、ファイル名を決めているのでしょうか?
第一に考えられるのが、HTMLなら<title>タグの文字列 + .htmlです。
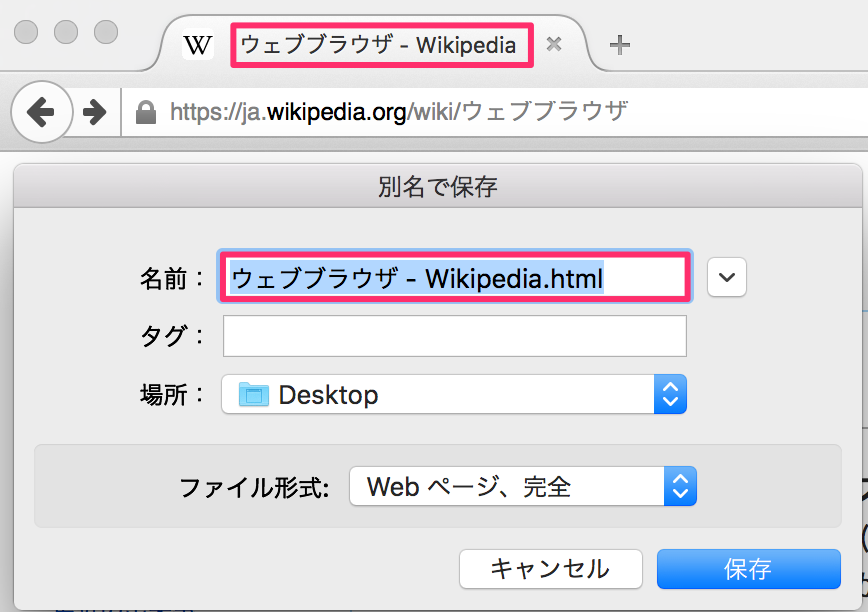
第二に、HTMLでない場合、たとえば画像ファイルはURLに含まれるファイル名です。
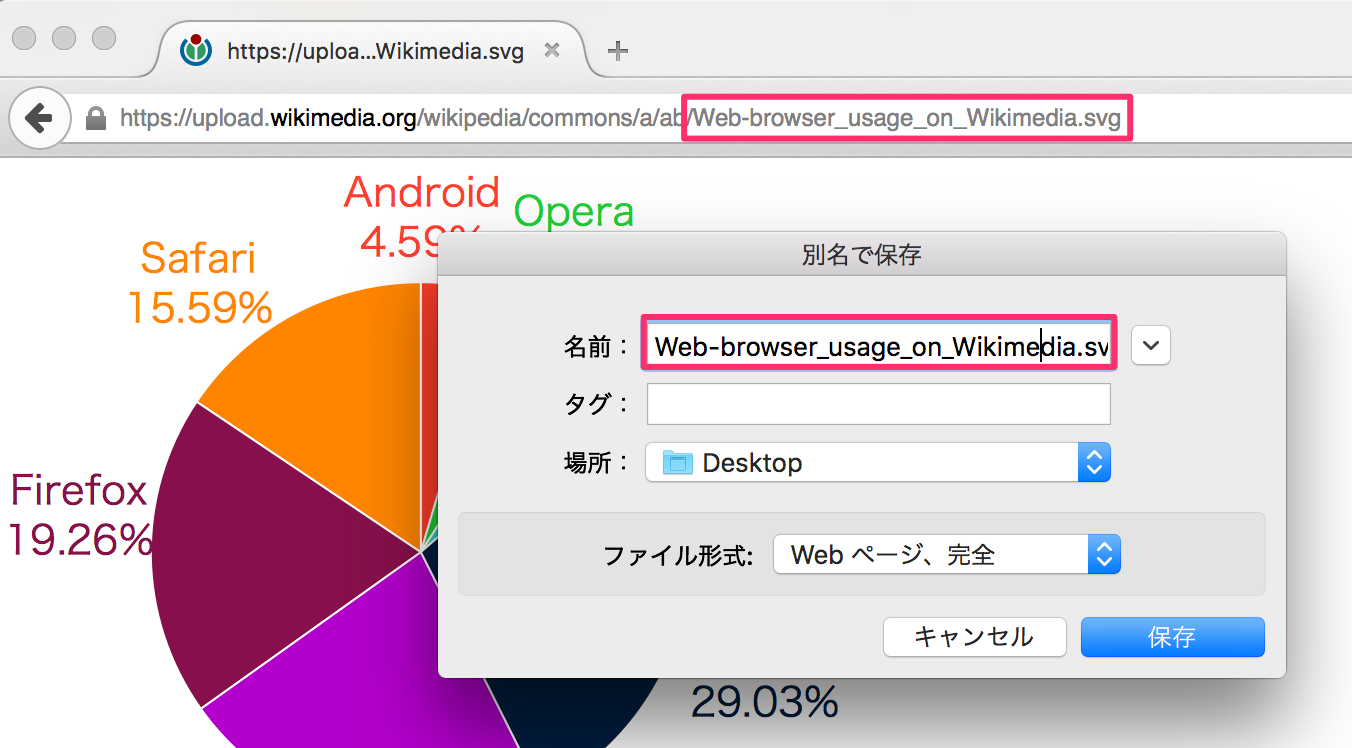
最後に、Content-Dispositionヘッダのfilenameの値です。
他にもあるかもしれませんが、大まかにこの3つのどれかになるわけです。
ここで着目したいのは第二のファイル名決定の仕様です。上の例では、英語のファイル名 Web-browser_usage_on_Wikimedia.svg でしたが、URLにはURLエンコードさえすれば日本語を含めることができるので、日本語ファイル名をURLのパスに含めてしまうという発想です。
$_SERVER['PATH_INFO']の利用
PHPでは、PHPファイル名の後ろにスラッシュをつけるとそれ以降からクエリストリングの手前までのパスを、$_SERVER['PATH_INFO']に格納してくれるという仕様があります。
たとえば、http://example.com/index.php/foo/bar/buz?hoge=123にアクセスした場合、index.phpでは$_SERVER['PATH_INFO'] = '/foo/bar/buz'がセットされます。
この仕様を活用して、PATH_INFOにダウンロード用ファイル名をセットすればいいわけです。たとえば、index.php/請求書-2016年02月-1432.pdf?invoice_id=1432といったURLでPDFを生成してあげれば、ブラウザはそのPDFを請求書-2016年02月-1432.pdfとして保存してくれます。
サーバ側のindex.phpはPATH_INFOの値は無視してもいいですが、URLはユーザが決められるので、もし勝手にファイル名をつけてほしくない場合は、$_GET['invoice_id']をキーにとってきた請求データと比較して、開発者が意図したファイル名と同じか、PATH_INFOをチェックしてもいいです。
サンプルコード: 日本語ファイル名で保存する例
次のサンプルコードは、ウェブ上のリソースを任意のファイル名で保存する例です。ご覧いただけるとわかりますが、User-Agentによる分岐はありません。
$filename = isset($_SERVER['PATH_INFO']) ? trim($_SERVER['PATH_INFO'], '/') : '';
$file = isset($_GET['file']) ? $_GET['file'] : '';
if (empty($filename) or empty($file)) {
header('HTTP', null, 400);
header('Content-Type: text/plain');
die('Invalid request');
}
// ファイルの内容をとってくる処理
$contents = @file_get_contents("http://$file"); // ここはもう少し安全にする必要があるがサンプルなので割愛
if ($contents === false) {
header('HTTP', null, 500);
header('Content-Type: text/plain');
die(error_get_last()['message']);
}
// ファイルをダウンロードさせる処理
header('Content-Type: application/octet-stream');
header('Content-Disposition: attachment');
header('Content-Length: ' . strlen($contents));
echo $contents;
このサンプルの使い方ですが、http://example.com/download.php/[ファイル名]?file=[リソース名]といったURLにユーザをアクセスさせて使います。ファイル名はダウンロード時のファイル名を指定し、リソース名にはURLからプロトコルを除いた部分を指定します。2
たとえば、ユーザにQiitaのMarkdown記法 チートシートのMarkdownファイルをダウンロードさせたいなら、下記のようなURLにアクセスさせます。
http://example.com/download.php/Markdown%E8%A8%98%E6%B3%95%20%E3%83%81%E3%83%BC%E3%83%88%E3%82%B7%E3%83%BC%E3%83%88.md?file=qiita.com/Qiita/items/c686397e4a0f4f11683d.md
^ この部分がダウンロード向けファイル名
このURLにアクセスした、ブラウザの挙動は次のようになります。
Google Chromeは問題なく意図したファイル名で保存されました。

Firefoxも問題なさそうです。
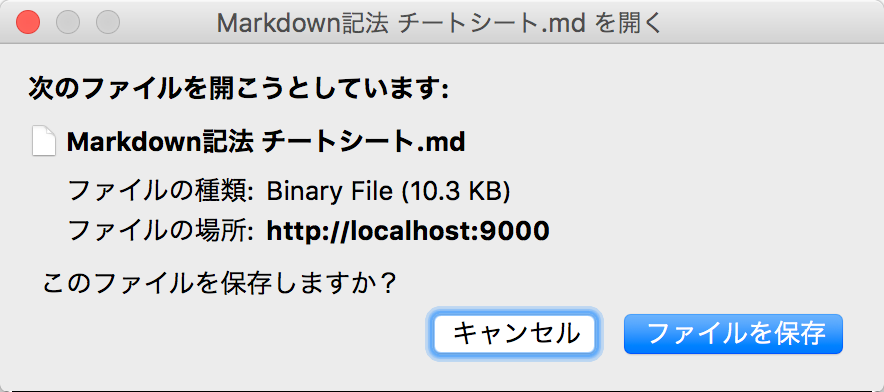
Safariも大丈夫です。

懸念のIE11も問題なさそうですね。

URLエンコードの注意点
注意点として、日本語ファイル名をURLに含める以上、URLエンコードする必要があるわけですが、エンコードする関数はrawurlencodeを使うという点です。urlencode関数を使ってしまうと半角スペースが+にエンコードされますが、ファイル名にそのまま+が現れてしまうからです。
ルーターを使えばURLはもっとすっきりする
今回 紹介したサンプルコードではクエリストリングからファイルのリソースを探す実装になっていましたが、MVCフレームワークのルータを使えば、URLがもっとすっきりしたものになるかと思います。
たとえば、Silexで次のようなルーティングを設定しておけば、/invoices/1432/請求書-2016年02月-1432.pdfといったURLでファイルをダウンロードさせることができます。
$app = new Silex\Application();
$app->get('/invoices/{invoiceId}/{filename}', function($invoiceId, $filename) use($app) {
// ここで $invoiceId から請求データを取得し、PDFを出力する
})->assert('filename', '.+\.pdf');
$app->run();
おわり
今回は、User-Agentで分岐しない日本語ファイル名ダウンロードの方法を紹介しました。検証したブラウザは多くないので、うまく動作しないブラウザはご報告いただけると助かります。
続き: User-Agent分岐無しに日本語ファイル名でファイルをダウンロードさせる (完全版)
-
このコードはあくまで日本語URLを簡単に試せるよう、「ファイルの内容をとってくる処理」の部分はどんなURLからでも取得してくるようにしていますが、実際はもっと制約的な実装の方が安全です。実践的な実装は@mpywさんのUser-Agent分岐無しに日本語ファイル名でファイルをダウンロードさせる (完全版)をご覧ください。 ↩