InfluxDB とは Black Duck Open Source Rookies of the Year 2013 にも選ばれた今注目の Time series metrics database である。
ということでちょっと触ってみた。
インストール
http://influxdb.org/download/ ページを見て、環境にあわせてインストールする。
例えば CentOS x86_64 の場合
$ wget http://s3.amazonaws.com/influxdb/influxdb-latest-1.x86_64.rpm
$ sudo rpm -ivh influxdb-latest-1.x86_64.rpm
influxdb process is not running [ FAILED ]
Starting the process influxdb [ OK ]
influxdb process was started [ OK ]
おぉ、これだけなのか。
http://influxdb.org/docs/ Introduction ページを見て、アクセスする。API が 8086 ポート、Web UI が 8083 ポートで動いているらしい。
ちなみに lsof -p してみると他にもいくつか LISTEN しているようだ。
$ sudo lsof -p 16288 -P | grep TCP
influxdb 16288 root 5u IPv6 988300294 0t0 TCP *:8090 (LISTEN)
influxdb 16288 root 7u IPv6 988300298 0t0 TCP *:8099 (LISTEN)
influxdb 16288 root 9u IPv6 988300742 0t0 TCP *:8086 (LISTEN)
influxdb 16288 root 10u IPv6 988300744 0t0 TCP *:8083 (LISTEN)
GUI で遊ぶ
実際に運用しようと思ったら、HTTP API を使うとは思うが、せっかくなので GUI から遊んでみる。
http://localhost:8083 にアクセスして、デフォルト root/root でログインする。ログインしたら GUI から database を作ったりできるようだ。

Database を作って、Explore リンクをクリックすると、次のような画面に入る。
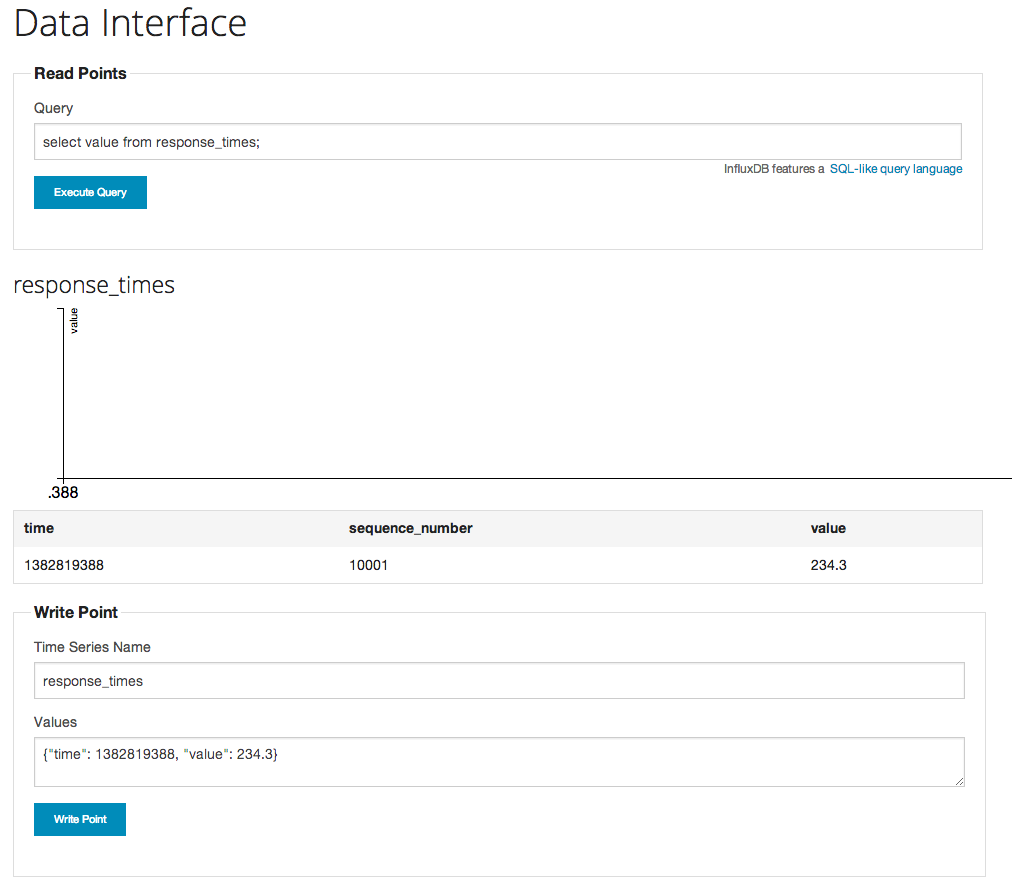
MySQL でいうところの table に相当するものを series と呼ぶらしい。試しに以下のようなデータを series に登録してみる。
Time Series Name: response_times
values: {"time": 1382819388, "value": 234.3}
で、Query を
select value from response_times;
としてみると、なんか出た。
もっと入れてみる。ほうほう。
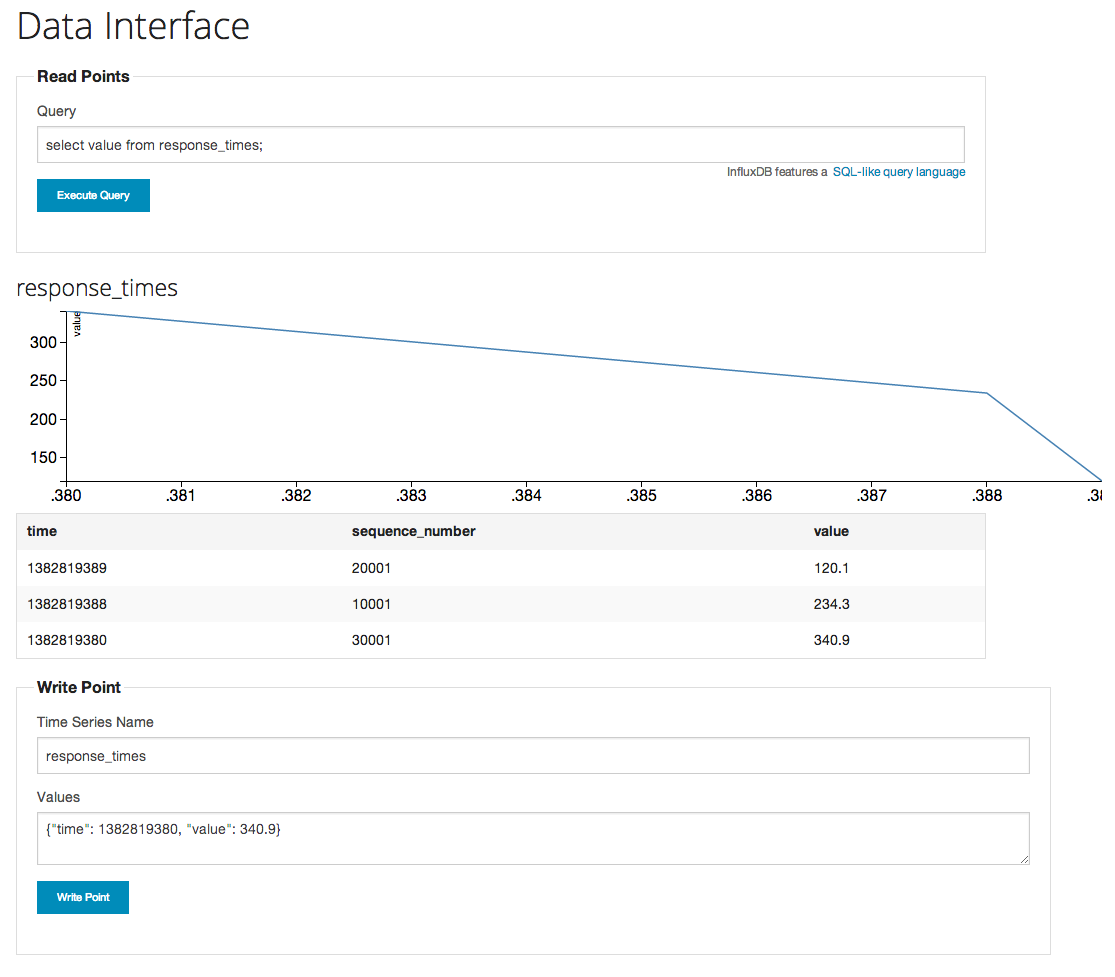
SQL-like query language
あとは、SQL-like query language を使って色々ごにょごにょできるようだ。
select value from response_times where time > now() - 1h limit 1000;
のようにして1時間以内、1000個のみに絞るとか、
select max(value) from response_times group by time(10m);
のようにして、10分ごとの max 値の値のみを取るとか。
Time Series SQL 楽しい ^^
おわりに
GUI を使ったのでグラフが表示されたが、実際に API 経由で使う場合は、json でデータが返ってくるだけなので描画ツールは自分で実装しなければならないはず。Elasticserach に対する Kibana のようなものが、InfluxDB にもあると捗るので、誰か作ると良いですね。
追記:そういえば最近 twitter のタイムラインに流れてた Grafana を使えるのかな。今、鋭意実装中みたいだけど期待できますね。cf. https://github.com/torkelo/grafana/wiki/InfluxDB
With version 1.5 Grafana now supports InfluxDB. The support is pretty basic with this first version.
追記の追記:触ってみました => Grafna on InfluxDB をちょっとだけ触ってみた