はじめに
Keras+Tensorflowを用いてLSTMでFXの予想してみるを書いたときにThinkPad X260(Core i7-6500 2.5GHz(2core 4thread))で計算すると非常に時間がかかりました。ディープラーニングではパラメータが多くいろいろと修正してみようとしてもこれだけ時間がかかってはそれもままになりません。また、FXには複数の通貨ペアがあり、1つの通貨ぺだけよければいいわけでもなく、検証にはさらに時間がかかることが想定されます。
ですが、TensorflowにしろKerasにしろGPUを使用して高速化可能です。ディープラーニングをGPUで実行するのは当然な流れです(後述しますがこの流れは変わる可能性はあります)。そこでGeforce GTX 1070で使って行ってみることにしました。
ハード(2017/6/5 7:00追加)
本当はすでに購入済み(UbuntuでTensorFlowを試すために購入していた)ですが、ハードは以下の構成です。
・Geforce GTX 1070(メモリ8GB)
・Core i5-6500 3.2Ghz(4core 4Thread)
・OS:Windows 10 64bit
・メモリ:8GB
GPUで計算させることをメインとするため、GPU部分はリッチに、けどCPUはどうせ必要ないだろうと思いケチりました(後述しますが、これが失敗するとは...)。ストレージは省いていますが、SSDを使っています(データ量が少なすぎてなんでもいいレベル)。
また、GPUにはメモリを大量に載せたいため8GB搭載している1070を選びました。1080や1080 Tiとか選べばもっと高速化にできると思いますが、どこまでGPUパワーが必要か未知だったため投資はできませんでした。電源もぎりぎりなレベルなので。これで他の用途にも使用するならばいいのですが、ディープラーニングにしか使用する予定がないので、多すぎる投資はできませんでした。お試し程度ならばメモリを6GB搭載した1060あたりがいいのかもしれませんが...
OSはWindowsを選択した理由は、同じような環境を他でも使用したいためです。すでにUbuntuでTensorFlowを試したことがあったのですが(その時はKerasを使っていなかった)、導入は結構大変でして。
また将来的にGPUを搭載したノートPC(Windows)を購入したときにすぐに導入できる程度の経験も欲しいと思ったためです。
準備
まずはTensorflowのGPU版の導入です。TensorFlowのinstallを参考にすればそれほど難しくないと言いたいところですが、私は2つ引っかかりました。
1つ目は、scipyのインストールです。基本的にはpipなどでインストールできませんでした。Unofficial Windows Binaries for Python Extension Packagesにあるscipy-0.19.0-cp35-cp35m-win_amd64.whlを持ってきました。これを持ってきて以下のようにファイル名指定でインストールすればいけます。
# pip install scipy-0.19.0-cp35-cp35m-win_amd64.whl
2つ目は、VSのライブラリです。実は先々週(2017/5/28前後)まではここにあったのですが、なぜかない...ちょっと調べてみます。
実は以前にUbuntuでTensorFlowのGPU環境を準備したことがあるのですが、どちらが楽かは微妙でした。どちらもすんなりできません。今はUuntu環境のほうが楽かもしれませんね。
これにNVIDIAのcuDNNのライブラリをパスが通っているところに配置など細かい手順がサイトにないところは残念ですが。
けど、CPUでは計算でいないほど時間がかかるので実質はGPU導入しないといけないのですが。
ソース
ソースですが、githubに登録済みです。git clone https://github.com/rakichiki/keras_fx.git して、keras_fx_gpu.ipynbになります。以前とはバグ修正とかもしています。ファイル名にGPUとついていますが、CPUのみの環境でも動作します。これをjupyterで起動しアップロードしていただければ動きます。
keras_fx_gpu.ipynbは以下の箇所が変わっています(どこかから参考にしたのですが忘れてしまいました...参考にさせていただいた方リンクを張らずにすいません)。
import tensorflow as tf
from keras import backend as K
config = tf.ConfigProto(allow_soft_placement=True)
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
K.set_session(session)
実行と考察のところに記載する予定でいますが、GPUは本体よりもメモリを持っていないものです。例えば、Geforce GTX 1070では8GBのメモリを搭載しています。昨今の開発用PCの本体のメモリは16GB搭載していてもおかしくはありません(私のメインのThinkPad X260は16GB搭載している)。
ですが、ディープラーニングはメモリを大量に消費しますし、指定がないと最初に大量にメモリを取ってしまうことがあります。このため、上記のように使う分使用することを最初に書いておかないと、いろいろ問題が生じることがあると思います。
以前にLinuxでGPUでTensorFlowを使っているときに並行して計算させようとしたらGPUのメモリが足りなく新規のタスクを起動できないことがありました。ご利用は計画的にってところでしょうか。
実行(速度のみ)と考察(2017/06/06 07:15大幅修正)
では、実行させてみましょう。ただ今回はFXの収益アップをめざすのではなく、9通貨ペアを計算するのにどれくらい時間を短縮できるかを念頭に置いています。チューニングやソース修正しても結果をみるのにどれくらいかかるかはわかりませんしね。
では結果は以下になります。GPUロードとメモリ転送帯域に関しては計算中の最も高い数字を出しています。
| 環境 | 通貨ペア数 | 時間(分) | GPUロード (%) | GPUメモリ 転送帯域 (%) | GPUメモリ 使用量 (MB) |
|---|---|---|---|---|---|
| Core i7-6500 2.5GHz (2core 4thread) | 1 | 27.9 | - | - | - |
| Core i7-6500 2.5GHz (2core 4thread) | 2 | 48.8 | - | - | - |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 1 | 3.1 | 50 | 15 | 526 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 2 | 4.4 | 72 | 20 | 793 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 3 | 5.5 | 75 | 22 | 1,069 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 4 | 7.0 | 76 | 23 | 1,345 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 5 | 9.0 | 76 | 23 | 1,620 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 6 | 11.1 | 77 | 23 | 1,891 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 7 | 12.6 | 76 | 23 | 2,079 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 8 | 14.7 | 77 | 23 | 2,355 |
| Geforce GTX 1070 & Core i5-6500 3.2Ghz (4core 4Thread) | 9 | 16.5 | 76 | 23 | 2,664 |
ThinkPad X260(Core i7-6500 2.5GHz(2core 4thread))とデスクトップPC(Geforce GTX 1070&Core i5-6500 3.2Ghz(4core 4Thread))になります。
通貨ペア数は同時にノートを開いて実行した数になります。CPUは時間がかかりすぎるので2通貨ペアまでしか試していません。
まず最初に1通貨ペアで比較するとCPUとGPUでは、9倍近く差があります。2通貨ペアで11倍近いです。だいたい速度差が1桁違えば、移行に大きな課題ががあってもチャレンジしようと意欲がわく数字ではないかと思います。また、CPUで9通貨ペアを計測していないのは時間がかかりすぎそうだったので諦めました(3時間オーバーでしょう)。
計算するものによっては重い処理ならばもっと差が開くと思います。ただ、目安としてこの程度の計算でもCPUでやるのは馬鹿らしいと考えるでしょう。
※:GPUを用いた箇所の考察しなおし(よく考えたらGPUの関係の情報をログとっていました。それ見ればもう少しわかりやすい説明ができました。)
この数字を見てみるとGPUで1通貨ペアではGPU全体を使用していないことがわかります。
ですが、3通貨ペア以上で75%前後で推移しそれ以上GPUが活用されていないことがわかります。
ただ、メモリ転送帯域やメモリ使用量(上限8GB)が足かせになっている数字は見えません。GPUの温度は記載しておりませんが9通貨ペアでも70度しか到達していないためサーマルストップしているわけではありません。
ここで9通貨ペアの状況を見てみました。
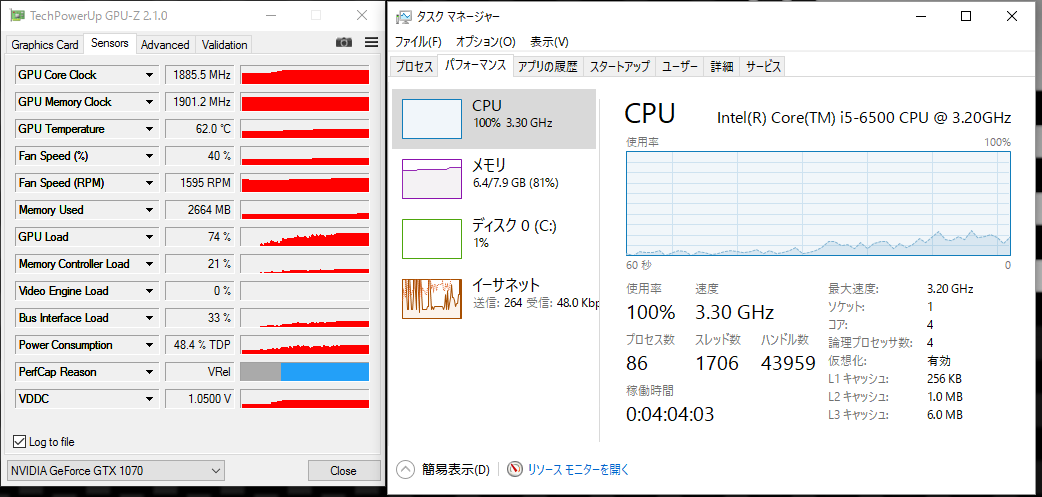
なんとCPUが100%に到達しています。TensorFlow/KerasのGPU版ではGPUしか計算していないと思っていたのですが、そうでもないのですね。loss等の計算のところとかでしょうか。
GPUの導入で一定の高速化の目途は立ちましたが、一部足を引っ張るところがあり十全に使用できているとは言えない状況です。
このPCを購入するときに、”どうせGPUで計算するからCPUはケチった構成にしたろ”、と思って構成を決めたのですが...失敗だったようです。
それでも9通貨ペアを一気に計算できるというものです。まぁ、その前にEarlyStoppingを入れろと言われそうですが...
感想
CPUがネックになって思いのほか計算速度が上がらないというあほらしい結果になりましたが、それでもGPUを活用することでものによっては1桁前後の高速化ができそうです。
ですが、この世の中はGPUでもやっぱりだめなのではないかと想定され各社対策が取られています。
Gooleは専用のTPUを作成しましたし、NVIDIAは最新のGPUにTensor Unitを搭載しましたし、QualcommはSnapdragon 835のDSPにTensorflowの対応をしていまし(ただ、TensorFlowはCPUとCUDA以外に動かないので、Qualcommの言い分はいまいちわからないのですが...)、AMDの最新のGPUであるVegaではFP16とINT8とかで計算できるようにして細かい計算能力を上げられるようにしています。各社今よりもディープラーニングの高速化に力を入れているように見えます。
ただ、GoogleのTPUもSnapdragon 835も一般販売されないでしょうし、Tensor Unit搭載のGPUもまだ販売されていないし(いや販売されてもこれは買えないだろうし)、AMDのVegaもいまだに販売されないうえに、TensorFlowがいまだにCUDAしかサポートしてくれないから使うこともできないし...
今以上に簡単に性能アップはなかなか難しそうな感じがしますが、この辺りは、来年(2018年)あたりには少し改善しているといいなと思う次第です。
最後に
とりあえず動くソースと簡易に試すことができる環境が整いました。これでようやくスタートできるというものです。これから結果はどうあれ少しずつチャレンジしみようと思います。