はじめの前に
Qiitaの記事を書く時に”はじめに”(導入というか記事を書いた動機や理由)から始めるのですが、今回のその前に書いている人の前提を書きます。
本記事は、タイトル通りKerasとTensorflowを用いてFXの予想をする記事です。ですが、書いている本人は以下の条件を残念ながら満たしております。
・FXも株もやったことがない(これマジ)
・ディープラーニングの知識はそれほどあるわけではない(Tensorflow 0.10登場時期ぐらいからチャレンジしていたけど、有効なものを作り上げることができなかったので一時期放り投げていた。けど今回Kerasのおかげ復帰)
・あんまりPython書いたことがない(Numpyに戸惑うほど)
こんな人が書いているものですが、気楽に読んでいただけると幸いです。
はじめに
Tensorflowで株やFXの予想をしている記事がいくつかありますが、どうしても腑に落ちないところがありました。それは、購入・売却の判定にopenかcloseで上がった、下がったで判断しているところです。
FX等はいろいろなスタイルなどがあるためそれが必ずしも間違っているわけではないのですが、highやlowを絡めて売買するのが普通ではないかと思うのです。ですが、high/lowを活用された例が私は見つけることができませんでした。
特にLSTMを用いた例は、翌日の上がった・下がったを用いるのが多い気がします。LSTMの悪い例だと、予想の値が結果をx方向にずらしただけのグラフに見えることがあります。こういうのを見ると正しいのかなと思わなくもありません。
この辺り何とか解決できないかなと思いチャレンジしてみました。
あと、Tensorflowをそのまま操作するのは私にとっては敷居が高いのでKerasを用いました。Kerasは初挑戦でしたが、TensorFlowから比べれば簡単でした(Kerasの操作の箇所は参考にしたソースとは違いがほとんどない)。
実行環境
実行環境づくりですが、インターネット上で公開されているのであえて記載しませんが、以下の環境で行いました。
・Windows 10
・PowerShellでJupyterを起動
・Tensorflow r1.1
・Keras
githubに公開しているのはJpythonにアップロードしていただければ動作すると思います。
購入・売却の方法に関して
”はじめに”に書いたように購入・売却方法を少し記載します。
売買を判定する日をx日とします。
予想はx - n_prev~x日までのhigh/lowのそれぞれのデータをもとにします。予想は、x + 1~x + n_next日のhighの最大値もしくはlowの最小値をそれぞれ行います。
予想されたhighの最大値とlowの最小値からx日のcloseとの差が、片方のみ規定以上(この値をyとする)ならば、x + 1日のopenで売買します(highの最大値とlowの最小値の両方ともyと差がついた場合はどちらに動くか不明なため売買しないとする)。
その後、売買価格(x + 1日のopen)からy以上の差がついたら時点で売買します(FXは怖いので防御も一応入れておく)。
もし、x + n_next日経って売買価格との差がy以上発生しない場合は、x + n_next + 1日でopenの価格で売買します。この場合は計算が面倒なので勝敗判定として使用しません(引分扱い)。
最初の売買の判定がx日のcloseをベースにするには、本当に売買価格であるx + 1日のopenと差ができますが、この辺りは仕方ないかなと思います。株よりも当日のcloseと翌日のopenの差が少ないと思いますし、あまりにも差があるようならば購入しないという判定(機能)も導入が必要でしょう(今回は入れていない)。
端的に言えば、LSTMの予想として以下になります。
・highとlowを用いてそれぞれ予想する
・予想も翌日の値ではなく、一定期間後の最大値もしくは最小値を予想する
このような予想をもとに売買判定のシステムを作成してみました(実際には公開しているソースでは売買判定はできず、アルゴリズムの検証だけになります)。
ソース説明
ソースはgithubに置いていますのでgit clone https://github.com/rakichiki/keras_fx.git してください。その後Jythonで起動しアップロードしてください。インターネット環境にさえあればすぐに実行できると思いますが、私がメインで使用しているPC(ThinkPad X260)で1通貨ペアで30分ぐらいかかるので注意してください。
少し解説を。
fxのcsvファイルをダウンロードします。通貨ペアをコメントアウトしていますが、一気に読み込んでそれぞれ行うのがいいかもしれませんが、残念ながら時間がくそかかるためここでは実施したい通貨ペアをコメントインして使ってください。
# ダウンロードする通貨ペア
# https://stooq.com/q/d/?s=usdjpy
# ついでにmxnjpy、sgdjpyとかもありますが、
# 2001/07/31からデータがない(データ的にあってもopen/high/low/closeがすべて一緒)ので
# ここには9通貨ペアしか記載しておりません。日付とか調整して通貨ペアを増やしてみても
# コメントイン・アウトして予想したい通貨ペアを決めましょう
currency_pair = 'usdjpy'
# currency_pair = 'eurjpy'
# currency_pair = 'gbpjpy'
# currency_pair = 'audjpy'
# currency_pair = 'cadjpy'
# currency_pair = 'chfjpy'
# currency_pair = 'nzdjpy'
# currency_pair = 'sekjpy'
# currency_pair = 'nokjpy'
# スタート日付
start_day = "20010101"
# 終了日を今日に指定
url = "https://stooq.com/q/d/l/?s=" + currency_pair + \
"&d1=" + start_day + "&d2=" + dt.today().strftime("%Y%m%d") + "&i=d"
file_name = currency_pair + '_d.csv'
# 取得して、ファイルに保存(よくよく考えると保存しなくてもいいな)
urllib.request.urlretrieve(url, file_name)
予想データの作成です。上でも説明していますが、起点の日からさかのぼってデータをxを積み込みます。yに関しては、起点の日の翌日から数日分で最大値もしくは最小値を調べます。
# data:配列
# n_prex:さかのぼる日数
# n_next:最大値・最小値の範囲
# flag:Ture->最大値、False->最小値 を取得します
def _load_data(data, n_prev=10, n_next=1, flag=True):
docX, docY = [], []
for i in range(n_prev, len(data)-n_next):
#起点の箇所からn_prevだけ戻った日数分をデータとする
docX.append(data.iloc[i-n_prev:i].as_matrix())
#起点の翌日からn_next日数分進んだデータのmax or minをyデータとする
if flag == True:
docY.append(max(data.iloc[i+1:i+n_next].as_matrix()))
else:
docY.append(min(data.iloc[i+1:i+n_next].as_matrix()))
alsX = numpy.array(docX)
alsY = numpy.array(docY)
return alsX, alsY
購入からどれくらい伸びたら売買を行う判断の数字ですが、私は以下のように求めることにしました。
トレーニング・テストの両期間内で一定以上の割合でアップもしくはダウンした値をもとに、売買の基準の値とします。この割合はコンフィグとして0.666(全体の3分の2)としました。この数字は根拠がある数字ではなく、とりあえず決めただけでの数字です。ただし、アップ、ダウン、それ以外がそれぞれ3分の1前後になるような数字が妥当かなと考えただけです(実際はアップとダウンの率は一緒ではない)。
一定の割合に関しては好きな値(0.9とか)に必ずしもできるわけではありませんので注意してください。この値の適切なところは私にはわかりません。低すぎればノイズ以外何ものでもないですし、高すぎる値は設定はできないでしょう。
while loop_flag:
up_count = 0
down_count = 0
even_count = 0
check_percent += check_add_percent
for i in range(train_start_count, test_end_count):
#起点の日の翌日のopenの値
open_value = data.loc[i+1, 'open']
#起点の日から翌日からn_next日数分のhighの最大値
max_value = max(data.loc[i+1:i+n_next, 'high'])
#起点の日から翌日からn_next日数分のlowの最小値
min_value = min(data.loc[i+1:i+n_next, 'low'])
#ここは起点の日の翌日のopenの値と起点の日の翌日から
#n_next日数分のhighの最高値かlowの最小値が規定の値上に
#差が広がったカウントを調べる。これで上がった・下がったを
#回数を調べる
if abs(max_value - open_value) >= check_percent and \
abs(open_value - min_value) < check_percent:
up_count += 1
elif abs(open_value - min_value) >= check_percent and \
abs(max_value - open_value) < check_percent:
down_count += 1
else:
even_count += 1
#(上がった日+下がった日)/全体の日数でcheck_thresholdを超えたか調べる
#超えていればその値をベースにする
print('(U+D)/(U+D+E): ' + str(math.floor((up_count + down_count) / \
(up_count + down_count +even_count) * 100)) + '%')
if (up_count + down_count) / (up_count + down_count +even_count) > check_threshold:
break
データの正規化です。この方法が正しいのかは私には判断できておりません。
複数の通貨ペアのデータをトレーニングとして用いるならば必須ですが、1つの通貨ペアのみでトレーニングと用いるならば正規化は効果は大きくはないと考えています(ただ、高い値と低い値では意味合いは違うため、一概に正規化は意味がないわけではないと思います)。
この辺りも正規化の方法と効果を調査してから決めないといけないと私は思っていますが時間の関係上まだ調査できておりません。
max_value = max(data['high'])
min_value = min(data['low'])
average_value = (max_value+min_value)/2
diff_value = max_value - average_value
print ('max: ' + str(max_value))
print ('min: ' + str(min_value))
print ('ave: ' + str(average_value))
print ('dif: ' + str(diff_value))
for i in range(len(data['high'].index)):
data.loc[i, 'high'] = (data.loc[i, 'high'] - average_value) / diff_value
data.loc[i, 'low'] = (data.loc[i, 'low'] - average_value) / diff_value
data.loc[i, 'open'] = (data.loc[i, 'open'] - average_value) / diff_value
data.loc[i, 'close'] = (data.loc[i, 'close'] - average_value) / diff_value
data = data.sort_values(by='date')
data = data.reset_index(drop=True)
data = data.loc[:, ['date', 'open','high', 'low', 'close']]
Kerasで予想します。と言ってもmodelを作成して、トレーニングをfitさせて、その後にtestをpredictさせればおしまいです。high/low別々に行っていますが、それが必須かは私にはわかりません。
ActivationとlossなどのKerasで指定するモデルに関しては何が正解か今のところわかっていないため今後試行錯誤する予定でいますが、これも時間がかかるので今回はとりあえず動くモデルだと思ってください。
# ニューラルネットの定義
# LSTMの定義/high/lowの両方を別々に保持したけど
# modeは共用してfitだけ違えればいい気がしないでもない
high_model = Sequential()
high_model.add(LSTM(hidden_neurons, \
batch_input_shape=(None, l_of_s, in_out_neurons), \
return_sequences=False))
high_model.add(Dense(in_out_neurons))
# high_model.add(Activation("linear"))
# high_model.compile(loss="mean_squared_error", optimizer="rmsprop")
high_model.add(Activation("sigmoid"))
high_model.compile(loss="binary_crossentropy", optimizer="adam")
low_model = Sequential()
low_model.add(LSTM(hidden_neurons, \
batch_input_shape=(None, l_of_s, in_out_neurons), \
return_sequences=False))
low_model.add(Dense(in_out_neurons))
# low_model.add(Activation("linear"))
# low_model.compile(loss="mean_squared_error", optimizer="rmsprop")
low_model.add(Activation("sigmoid"))
low_model.compile(loss="binary_crossentropy", optimizer="adam")
print("High Fit")
# 学習
high_model.fit(X_high_train, y_high_train, batch_size=100, epochs=100, validation_split=0.0)
# テスト結果表示
high_predicted = high_model.predict(X_high_test)
print("Low Fit")
# 学習
low_model.fit(X_low_train, y_low_train, batch_size=100, epochs=100, validation_split=0.0)
# テスト結果表示
low_predicted = low_model.predict(X_low_test)
予想をしてもそれが正しいか判定が必要です。そこで判定と結果を表示させます。
# 使わないデータも保持しているが
# 予想したHighの最大値とLowの最小値を起点の日の翌日のOpenの
# と比較し、最初sに決定した差よりも大きい場合は上がり・下がりと
# 判断する
# ただし、同時超えた場合はどちらが先に上がるか不明なためカウントしていない
# もしかすると
for i in range(len(low_predicted)):
high_temp = high_predicted[i] * diff_value + average_value
low_temp = low_predicted[i] * diff_value + average_value
open_temp = data.loc[i+test_start_count+1, 'open'] * diff_value + average_value
close_temp = data.loc[i+test_start_count, 'close'] * diff_value + average_value
if high_temp - close_temp >= check_treshhold and \
close_temp - low_temp < check_treshhold:
pre_check.append(1)
temp_check.append(high_temp - open_temp)
temp_close_open.append(abs(close_temp - open_temp))
elif close_temp- low_temp >= check_treshhold and \
high_temp - close_temp < check_treshhold:
pre_check.append(-1)
temp_check.append(low_temp - open_temp)
temp_close_open.append(abs(close_temp - open_temp))
else:
pre_check.append(0)
temp_check.append(0)
通貨ペアを一斉に回すことができるようにすれば面白いかもしれませんが、時間がかかるため、対策しない状況で行ってはいけません。
結果
実施した通貨ペアをコメントインし、Jupyterを実行すると結果が下に表示されます。
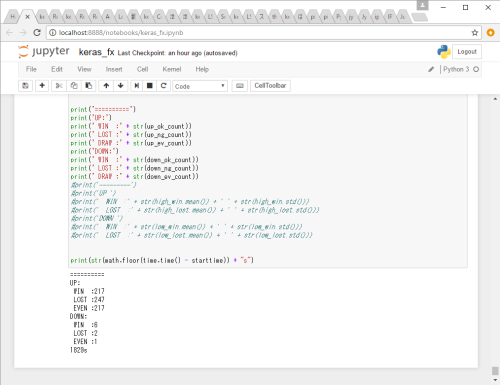
トレーニング期間は2002/01/01~2013/12/31(12年間)までテスト期間は2014/01/01~2016/12/31(3年間)まで行った結果をいかに示します。
・usdjpyペア
| アップ/ダウン | 的中/外れ/引分 | 回数 |
|---|---|---|
| アップ | 的中 | 131 |
| 外れ | 115 | |
| 引分 | 132 | |
| ダウン | 的中 | 60 |
| 外れ | 36 | |
| 引分 | 38 |
引分を除くと的中率は約55%。
・eurjpyペア
| アップ/ダウン | 的中/外れ/引分 | 回数 |
|---|---|---|
| アップ | 的中 | 110 |
| 外れ | 142 | |
| 引分 | 123 | |
| ダウン | 的中 | 52 |
| 外れ | 27 | |
| 引分 | 29 |
引分を除くと的中率は約48%。
・gbpjpyペア
| アップ/ダウン | 的中/外れ/引分 | 回数 |
|---|---|---|
| アップ | 的中 | 217 |
| 外れ | 247 | |
| 引分 | 217 | |
| ダウン | 的中 | 6 |
| 外れ | 2 | |
| 引分 | 1 |
引分を除くと的中率は約47%。
とてもいいとは言えない数字ですが...
最後に
結果はよくありませんでした。
ですがチューニングを十分でないならば壊滅的に最悪というわけでもないと思います。
ディープラーニングで設定する項目は多岐にわたっている上に、計算に時間がかかります。
ソース説明にも書きましたがThinkPad X260でCPUでKeras+Tensorflowでは1通貨ペアを検証するのに30分もかかります。たった30分ならばとなりますが、パラメータはKerasの設定箇所もたくさんありますし、予想するためのデータも可変ですし、通貨ペアは1つだけではありません。
このため、n_prevが20日が最も適切かと言われれば私が断定できませんし、n_nextも5日としていますが、これも最も正しいかと言われればわからないと答えざるを得ません(FXや株価ではよく使用される日数ではありますが、それとディープラーニングと相性はいいかは確定されたわけではないと思います)。
また、一番懸念である当日closeと翌日openの差があると予想自体に破綻するにも関わらず対応していないなど修正が必須です(単にどこで除外するかわからないのでやっていないだけ。これも数字次第でどうとでもなる)。
ですが、1つの計算で30分もかかっていては、少しパラメータ変更してみようと思っても簡単ではありません。
この辺りがディープラーニングがCPUで計算が実質不可能な所以だと思います。このため、Googleはテンソル計算用にTPUを自作しましたし、NVIDIAがVlotaでTensor Unitを追加した製品を出荷しました。今のところディープラーニングに向けてハードの対応が進み始めていると思います。
このため、ThinkPad X260でソースを書いていましたが、チューニングができない状況まで来ました。もうあきらめてリッチなGPU(個人で使うにはNVIDIAのGeforce 1080あたりが限界かな?)を用いてチューニングしないといけないかなと思ったりしています。もう少しチューニングした結果で本記事を書いたほうがよかったですが、今回はさわりということで。
また、Amazonを見ていると詳解 ディープラーニング ~TensorFlow・Kerasによる時系列データ処理~が出るようなので(中身は知りませんが)、この辺りを参考にKerasで解析できるようになればいいなと思っています。
できはまだまだ十分ではありませんが、素のTensorflowで操作するよりもKerasのほうがやっぱり簡単だと思います。
リンク
参考にさせていただきましたページをリンクさせていただきます。
・深層学習ライブラリKerasでRNNを使ってsin波予測
・LSTM で株価予測してみる
次のページ