goのコードを生成するpythonのコードを書いてみる -- JSON-to-Goをportingしてみたりなどしてあれこれする
この記事は WACUL Advent Calendar 2016 7日目の記事です。
今年の9月からWACULで働いていて、主にバックエンドでgoのコードを書いていたり時々pythonを書いていたりしています。
ところで、あれこれ書いている内に長くなってしまったので、何をしたかだけ知りたい人は はじめに を読んだ後は、ようやく本題 のあたりまで読み飛ばしてしまってください。
はじめに
最近は業務で日々goのコードを書いているのですが。時折pythonでgoのコードを書いてみたいと思うことがありました。おかしいと思うかもしれません。でも待ってください。一応、以下のような思考のフローを辿った結果です。
- go言語の普通の機能の範囲でできる事があるか確認する
- go言語の少し危ない機能を使ってできるかどうか確認する
- go製のツールの範囲でできることがあるか確認する
- (自分の慣れている)他の言語でgoのコードを生成してしまう
もちろんなるべく以上のステップの上の方で済ませられた方が良いことは確かです。
1. と 2. の差は主観的なものでわかりにくいかもしれませんが。
2. は型の制限を弱めた手抜きのコードを書いたりだとかリフレクションを使ったりなどのような状態のことを指しています。
3. に関してはあればラッキーみたいな感じですね。無ければgoで作るというのでも良いかもしれません。
とは言え、興味本位での探求であったり、ちょっとした作業を手慣れた言語で済ませてしまうとということはあると思います。変に頑張って汎用的なものを作るよりも個人の趣向にあった振る舞いをするものをさくっと作ってしまったほうが早いかもしれません。個人的にはpythonが手に馴染んでいたのでpythonを選んでみました。
普通のコード生成
goのコード生成というと通常は以下の2つを思い浮かべると思います。
-
text/templateなどを使って雑に引数で渡された文字列を埋め込みコードを生成 - ASTを辿りながら必要な形に整形してコードを生成
今回はこれ以外の話です。
goのコードを生成するpythonのコードを書いてみる
prestring?
実は以前からコード生成の様な作業をする時に自作のライブラリを使っています。prestring というライブラリです。たぶん知っている人は誰もいないと思うのでこのライブラリについて少し解説します。
このライブラリはpythonあるいは何らかのDSLからgoのコードを生成するような(transpile)ライブラリではなく、本当にただただpython上で特定の言語Y(ここではgo)のコードを直接手書きするためのライブラリです。コードの自動生成にテンプレートエンジンなどを使うものと同じ感じの位置づけのものですが。フルの言語機能が使える辺りが使用感としては違うかもしれません。
特徴としてはインデントの管理を楽にするという辺りを重要視していました。元々の着想自体は勝利のためのD言語 | プログラミング | POSTDの記事などに出てくるsrcgenというライブラリが由来です。
やがて文字列になるオブジェクト
prestringは各moduleが Module というクラスが用意しています。このクラスのobjectに対してあれこれ操作を加えた結果を出力するとコードが生成されるという仕組みです。ちなみに名前のprestringですが文字列の前の状態という意味を込めていた記憶があります。
m = Module()
m.stmt("hai")
print(m) # => "hai\n"
hello worldを出力するコードを生成するコード
簡単なコードということでhello worldを書いてみましょう。hello worldは以下のような形になります。
from prestring.go import Module
m = Module()
m.package("main")
with m.import_group() as im:
im.import_("fmt")
with m.func("main"):
m.stmt("fmt.Println(`hello world`)")
print(m)
使い方としては、インデントが欲しくなったらwith構文を使う。各言語の予約語に似た名前のメソッドを使うという気持ちで書いていけば良いです。
慣れればそのまま出力先の言語が見えてくる様になります。おそらく。きっと。たぶん。
実際、上記のコードは以下のようなgoのコードを出力します。ちょっと不格好な出力であっても gofmt が整形してくれるので便利ですね。
package main
import (
"fmt"
)
func main() {
fmt.Println(`hello world`)
}
直積を計算するコードを生成するコード
もうちょっと複雑なコードの自動生成してみましょう。あるリストとあるリストの直積を計算するコードを書いてみようと思います。例えばxsとysの2つのリストの直積は以下の様なものです。
xs = [1, 2, 3]
ys = ["a", "b", "c"]
[(x, y) for x in xs for y in ys]
# => [(1, 'a'), (1, 'b'), (1, 'c'), (2, 'a'), (2, 'b'), (2, 'c'), (3, 'a'), (3, 'b'), (3, 'c')]
同様に2つの場合、3つの場合、...Nつの場合などを考えていきます。通常は再帰などを使って任意回のコードを書くと思いますが。今回はそれぞれの場合のコードを出力するコードを書いてみたいと思います。
N=2の場合の直積を計算するコードを計算するコード
まず2つの場合のgoのコードを生成するコードを直接書いてみます。以下の様な形になります。
from prestring.go import GoModule # Moduleと同じもの
# cross product
def cross2(m):
with m.func("cross2", "vs0 []string", "vs1 []string", return_="[][]string"):
m.stmt("var r [][]string")
with m.for_("_, v0 := range vs0"):
with m.for_("_, v1 := range vs1"):
m.stmt("r = append(r, []string{v0, v1})")
m.return_("r")
return m
m = GoModule()
m.package("main")
print(cross2(m))
withが付いていればインデントということを念頭に入れると何となく読めるんじゃないでしょうか。出力した結果は以下になります。
func cross2(vs0 []string, vs1 []string) [][]string {
var r [][]string
for _, v0 := range vs0 {
for _, v1 := range vs1 {
r = append(r, []string{v0, v1})
}
}
return r
}
N=5の場合の直積を計算するコードを計算するコード
今度は、渡されるリストの数が、3つの場合、4つの場合...と任意個のリストが渡された場合を考えていきます。渡されるリストの数によってループのネストの数が変わる辺りがちょっと面倒かもしれません。
こういう場合はそのまま直接は書き下せないのですが、再帰で書くとインデントの構造を保ったまま任意回にネストしたループしたコードを生成できます。
def crossN(m, n):
def rec(m, i, value):
if i >= n:
m.stmt("r = append(r, []string{{{value}}})".format(value=", ".join(value)))
else:
v = "v{}".format(i)
vs = "vs{}".format(i)
with m.for_("_, {} := range {}".format(v, vs)):
value.append(v)
rec(m, i + 1, value)
args = ["vs{} []string".format(i) for i in range(n)]
with m.func("cross{}".format(n), *args, return_="[][]string"):
m.stmt("var r [][]string")
rec(m, 0, [])
m.return_("r")
return m
ちょっと読みづらいですが。外側のwithを抜ける前に内側のwithが書かれている、その呼出しがネストされていくと考えると、一応は以下の様な構造になっているので慣れてください。
with v0の段のループ
with v1の段のループ
with v2の段のループ
...
with vNの段のループ
試しにN=5のときのcrossN(m, 5) の結果を出力してみると以下のようになります。
package main
func cross5(vs0 []string, vs1 []string, vs2 []string, vs3 []string, vs4 []string) [][]string {
var r [][]string
for _, v0 := range vs0 {
for _, v1 := range vs1 {
for _, v2 := range vs2 {
for _, v3 := range vs3 {
for _, v4 := range vs4 {
r = append(r, []string{v0, v1, v2, v3, v4})
}
}
}
}
}
return r
}
Module()に対するsubmodule()
もう1つ特徴的な機能がありました。submoduleという機能です。
この機能は、ある出力中の特定の位置に対してmarkerを付けておき、その位置に挿入したい文字列表現を後で埋め込めるという機能です。
以下の様なものです。
m = Module()
m.stmt("begin foo")
sm = m.submodule()
m.stmt("end foo")
m.stmt("bar")
sm.sep()
sm.stmt("** yay! **")
sm.sep()
print(m)
mのfooで囲まれた位置にsmというsubmoduleを作成し。後々に改行と何らかの文言を埋め込んでいます。出力結果は以下の様になります。
begin foo
** yay! **
end foo
bar
この機能はimportの部分に使われています。なので後々必要になるpackageのimportを後で書く事ができます。
from prestring.go import Module
m = Module()
m.package('main')
with m.import_group() as im:
pass
with m.func('main'):
im.import_('log')
m.stmt('log.Println("hmm")')
print(m)
main関数の中で初めて "log" がimportされていますが。出力された結果を見ると import_group() で指定した位置に挿入されています。
package main
import (
"log"
)
func main() {
log.Println("hmm")
}
もっとも、 gofmt の代わりに goimports を使ってimport部分を自動で挿入してしまえば良い話しでもあるのであまりgoでは使わないかもしれません。
コードを生成するコードのabuse
コードを生成するコードを生成する能力を手にしたのだから、何でもコード生成で済ませちゃおうと思う気持ちがあった時もありましたが。結論から言うとあまりおすすめしません。実行時に計算できるものは実行時にやるというのが良いです(reflection使おうという話ではないです)。
例えば、以下のような まじめな人が書いたfizzbuzz などのようなことをやっても嬉しさはあまりありません。
いくらできるからといってやって良いことと悪いことの区別は自身の怠け心を元に判断してください。
個人的には、以下のような判断基準が良いと思っています。
- コード生成に手を染める前に本当に必要かどうか考えてみる
- アプリケーションコードの自動生成はオススメしない。自動生成するならグルーコード
- 自動生成されたコードは絶対に編集しない。手を加えた瞬間自動生成は負債になる。
一番最後のはジェネレーション ギャップ パターン(この言葉は最近知りました)を少し汎用的な物言いに変えたものです。
あと、付け加えておくと、不足している言語機能を補おうとするのもおそらく失敗に終わることが多いです。
一例としてgenericsをあげておくと、Container<T> に対応する単相の TContainer 的な定義は生成できますが。Container<T>を引数として取る関数のようなものが定義できません。
本来のgenericsであれば型変数Tとして扱われるTが生成と同時に消えてしまい伝搬しないからです。真面目に動作させるにはすごい泥臭い作業が必要になり結局頑張ってもさほど価値が無いみたいな感じになります。
ようやく本題
長かったですがようやく本題です。ここでちょうど半分位の位置です。
JSON-to-GO?
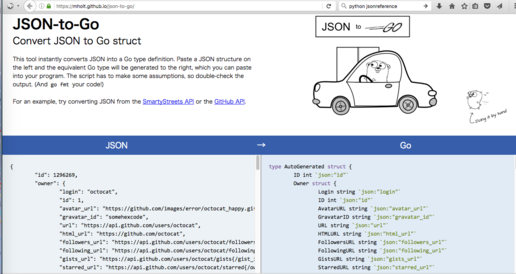
Qiitaに以下の様な記事があったようです。
上の記事を読んで知ったのですが。JSON-to-Goという便利なサービスがあるようです。これはAPI ResponseのJSONを渡してあげると対応するgoの型定義を出力してくれるというものです。
GitHubのAPIのsampleのリンクをクリックしてみるとどのような形でどういうものかわかると思います。
ちなみにこのサービスで使われている変換部分の実装はGithubにあるようです。jsで書かれたコードでした。
1. JSON-to-GOをpythonにporting
これをそのまま使うのも良いのですが。丁度良い題材なのでpython上にportingしてみようと思います。と言っても完全なportではなくおおよそ同じような出力になるものを前述したprestringというライブラリを使って作ろうという試みです。
portingしたコードは以下のリンク先のようなコードになります。
120行程度なのでそんなにつらいコードというわけでもないです。元のjsのコードも230行位で少しpythonのコードよりも多いですがそんなに大きなコードではありません。コードサイズの差異の原因は、元のjsの実装ではgo用の名前に変換する処理を自前で定義しているためです。その分が削減されているので120行程度ということです。(ちなみに元のjson-to-goで使われているgo用の名前に変換する処理が便利そうだったので。同様のものをprestringの内部に取り込んだという経緯があります)
さて、実際にporting作業をしてみようと思うのですが、以下の操作が行えればJSONからgoのコードへの変換ができそうです。
- go用の名前の変換
- JSONの各フィールドの値からgoの型を推測
- goの型定義を生成
それぞれについて、元のjson-to-go.jsのコードを覗いてみて面白いなと思ったことを書いてみます。
go用の名前への変換
goにより適した名前の変換というのは以下のようなものです。
>>> from prestring.go import goname
>>> goname("foo_id")
'FooID'
>>> goname("404notfund")
'Num404Notfund'
>>> goname("1time")
'OneTime'
>>> goname("2times")
'TwoTimes'
>>> goname("no1")
'No1'
アンダースコアが取り除かれたり、数値で始まる名前に特別なprefixが付いていたりと言うような変換です。CamelCaseっぽい何かです。
例えばURL,API,ASCII,...など特定のacronymに関しては特別な処理をしているようです。頑張ってます。
これらの特別扱いするacronymのリストに関してはgolintのコードから取ってきたようでした。
JSONの各フィールドの値からgoの型を推測
基本的にはJSONをdeserializeした結果の値から型を一対一でif文で分岐している感じです。
なるほどと思ったのは以下の3つでした。
- 渡されたJSONの文字列をdeserializeする前に".0"を".1"に変換する
- intとfloatに関しては型に順序的なものを設けてより良い型の方を選択するようにしている
- structの各フィールドについてフィールドの出現頻度が親のstruct自身の出現頻度と一致していなければomitempty
1. に関してはfloatでありそうな数値をintとparseすることを避けるためのhackっぽいです。
goの型定義を生成
こちらはそれなりに綺麗に書けます。と言うかまじめに元のjsのコードを読んでいません。短いのでこちら載せようと思います。以下の様な手順で生成しています。
- json load
- struct infoの生成 jsonをparseした結果を扱いやすい中間状態に変換
- コードの生成
1. のjson loadに関しては渡されたjsonをloadするだけです。この前処理として上の".0"を".1"に変換する処理を入れておきます(たぶんpythonでは不要なのですが念のためみたいな感じです)。
2. のstruct infoの生成ですが。struct infoと言っても大げさなものではなく以下のような辞書です。一度JSON全体をparseして以下の様な情報を取るイメージです。
{"freq": 1, "type": "int", "children": {}, "jsonname": "num"}
freqは出現頻度、typeはgoでのtype、childrenには辞書(struct)であれば子要素が入り、jsonnameは元のjsonでの名前(辞書のkeyがgoの型名です)。
3. のコード生成の部分ですが。ここがそれなりに綺麗に書けると言った部分です。それなりに読めるレベルのコードなのではないでしょうか。
def emit_code(sinfo, name, m):
def _emit_code(sinfo, name, m, parent=None):
if sinfo.get("type") == "struct":
with m.block("{} struct".format(name)):
for name, subinfo in sorted(sinfo["children"].items()):
_emit_code(subinfo, name, m, parent=sinfo)
else:
m.stmt('{} {}'.format(name, to_type_struct_info(sinfo)))
# append tag
if is_omitempty_struct_info(sinfo, parent):
m.insert_after(' `json:"{},omitempty"`'.format(sinfo["jsonname"]))
else:
m.insert_after(' `json:"{}"`'.format(sinfo["jsonname"]))
with m.type_(name, to_type_struct_info(sinfo)):
for name, subinfo in sorted(sinfo["children"].items()):
_emit_code(subinfo, name, m, parent=sinfo)
return m
そんなわけでJSONからgoのstructへの変換器を手にする事ができました。
実際に、portingしたコードを使って、githubのAPI responseを変換した結果はこのようになります。長い出力なので別リンクにしました。
せっかく手に入れたJSONからgoへの変換器、どうせなのでちょっと改造してみましょう。
以降も、JSON-to-Goでも使われていたgithubのAPI responseのJSONを利用して出力結果を確認していくことにします。
2. 型の対応関係を変えてみる(e.g. strfmt.Uriを使うようにする)
URIやEmailアドレスなど特定の文字列に対しては別の型に割り当てたいと思う事があると思います。
例えばstrfmtのUriを使うように変えてみます。
試しに "://" が含まれていたらstrfmt.Uriを使うようにしてみます。ついでにstrfmt.Uriが使われるときにはimportも追加するようにしてみました。変更は数行程度で済みます。
真面目に色々な型に対応したい場合には、goの型を推測する部分に対応関係を書いていく感じになりそうです。
以下のような出力部分が
package autogen
type AutoGenerated struct {
CloneURL string `json:"clone_url"`
CreatedAt time.Time `json:"created_at"`
...
以下のようになりました。
package autogen
import (
"github.com/go-openapi/strfmt"
"time"
)
type AutoGenerated struct {
CloneURL strfmt.Uri `json:"clone_url"`
CreatedAt time.Time `json:"created_at"`
...
3. フラットな構造で出力してみる
此処から先が気の迷いの始まりです。気軽な気持ちでちょっと対応すればどうにかなるだろうと思っていた変更が色々と面倒な不具合を引き起こし始めました。
リンク先の記事ではわりとdisられていましたが、せっかくコード生成器を手にしたので。大きく出力結果が変わるような変更を取り入れてみたい気持ちがありました。出力するstructの構造をネストしたものからフラットな構造のものに変更してみます。とりあえずstructの名前はその時々のフィールド名をそのまま使うことにしてみました。
変更は10数行程度でした。
以下のような定義が
type AutoGenerated struct {
CloneURL strfmt.Uri `json:"clone_url"`
...
Name string `json:"name"`
OpenIssuesCount int `json:"open_issues_count"`
Organization struct {
AvatarURL strfmt.Uri `json:"avatar_url"`
EventsURL strfmt.Uri `json:"events_url"`
以下のように変わっています。
type AutoGenerated struct {
CloneURL strfmt.Uri `json:"clone_url"`
...
Name string `json:"name"`
OpenIssuesCount int `json:"open_issues_count"`
Organization Organization `json:"organization"`
...
type Organization struct {
AvatarURL strfmt.Uri `json:"avatar_url"`
EventsURL strfmt.Uri `json:"events_url"`
たしかに出力された結果を見てみると、以前の出力で得られていたネスト関係の構造が消えてしまっているため、値の親-子の関係がわかりにくくなっている気がします。
4. 値の親-子関係をコメントで付与
フラットな出力では値の親-子関係の構造がわかりにくいので、ネスト関係の構造を一望できるようなコメントをstruct定義の先頭につけてみることにしてみました。
変更は20行程度ですが。元の出力する関数のemit_code()自体の変更は2行位です。
定義の先頭に付加されるようになったコメントは以下の様なものです。ネスト関係がこれで分かる様になりました。
/* structure
AutoGenerated
Organization
Owner
Parent
Owner
Permissions
Permissions
Source
Owner
Permissions
*/
5. 名前の衝突を防ぐ
ところで、気づいてしまったのですが、そして察しの良い方であればすぐに気づいたかと思うのですが。問題がありますね。名前が衝突する可能性があります。元のネストした構造の出力では、structは即時定義のため名前をつける必要がなかったのですが。ネストした出力をフラットな出力にした結果、structの定義に名前が必要になりました。安易に直接フィールド名を使ってしまっていましたが。例えば以下のようなJSONでは名前が衝突してしまいます。
{
"title": "はじめての日記",
"author": "foo",
"content": {
"abbrev": "今日からブログを始める事になりました。...",
"body": "今日からブログを始める事になりました。この記事はadvent calendarのX日目の.... ....."
},
"ctime": "2000-01-01T00:00:00Z",
"comments": [
{
"author": "anonymous",
"content": {
"body": "hmm"
},
"ctime": "2000-01-01T00:00:00Z"
}
]
}
記事の部分のcontentとコメント部分のcontentが衝突してしまいます。
/* structure
Article
Comments
Content
Content
*/
// 記事の部分のcontent
type Content struct {
Abbrev string `json:"abbrev"`
Body string `json:"body"`
}
// コメント部分のcontent
type Content struct {
Body string `json:"body"`
}
とりあえず、不格好でも良いので名前の衝突を避けましょう。prestring.NameStoreというオブジェクトを使います。
これは辞書の様なオブジェクトで値に名前を入れておくと、重複した名前に関しては衝突を避けるような名前を返してくれます(NameStore.new_name()をオーバーライドしてあげれば名前の生成規則を変えられます)。
>>> from prestring import NameStore
>>> ns = NameStore()
>>> ob1, ob2 = object(), object()
>>> ns[ob1] = "foo"
>>> ns[ob2] = "foo"
>>> ns[ob1]
'foo'
>>> ns[ob2]
'fooDup1'
変更は10数行程度です。テキトウにstruct用の辞書の形状に対してuniqueになりそうな値を生成して、それをキーに名前を管理しています。
/* structure
Article
Comments
ContentDup1
Content
*/
type Content struct {
Abbrev string `json:"abbrev"`
Body string `json:"body"`
}
type ContentDup1 struct {
Body string `json:"body"`
}
CotentDup1というのは名前が良くはないですが。一応は衝突を回避できています。同じ名前のstructを併用するためにpackageを分けると言うのは仰々しいですし。例えばrubyのmoduleのように何か手軽に名前空間を導入できる機能があれば便利なのですけれど。goにはそれに使えそうな機能は無さそうなので放置します。
6. 重複した定義を1つにまとめる
名前の衝突が一応は解決したところでもう一度Github APIのJSONを渡した出力結果を見てましょう。
/* structure
AutoGenerated
Organization
Owner
Parent
Owner
Permissions
Permissions
Source
Owner
Permissions
*/
ParentとSourceは同じ形状のような気がします。実際中を覗いてみると同じ型定義のようでした。そして実はPermissionsの型定義が何度も登場してしまっていました。トップレベルのAutoGenerated自身もSourceなどのsupersetのような気はしますがとりあえず置いておきます。重複した定義は1つにまとめたい気がします。やってみましょう。
変更箇所は10数行程度でした。以前の変更(4. 値の親-子関係をコメントで付与)で出力するようにしたstructのネスト構造を出力するコメントの部分の走査とstruct定義を出力する際の走査が別になったのでそもそも関数を分けました。
出力結果はリンク先のようになり、確かに重複した定義を取り除く事ができたのですが。1つ問題があります。それは次のステップで直します。
7. structの型名により良い名前を使う
問題が1つ残っています。それはParent,Sourceの部分をみてもらうとわかります。以下のような構造になっており、SourceとParentは同じ形状のものです。
/* structure
AutoGenerated
Parent
Owner
Permissions
Source
Owner
Permissions
*/
ParentとSourceが同じ形状ということは同じ型が使われるということですが。この型の名前が良くありません。どちらかと言えばSourceの方がまだ適切な名前ですが、Parentという名前の型が定義され使われてしまっています。悲しい。
type AutoGenerated struct {
...
Parent Parent `json:"parent"`
...
Source Parent `json:"source"`
...
}
元々のJSON-to-GOでは即時定義された無名のstructなのでこのようなことを気にする必要がありませんがフラットな構造にした結果名前をつける必要が出てきてしまい、その上その名前を指定するための適切な情報が得られない場合があります。
少しだけ抵抗してみることにします。ちょっとトリッキーな方法ですが、生成する型名を後で決めるようにします。このような場合にはprestring.PreStringを使います。
from prestring import PreString
from prestring.go import GoModule
m = GoModule()
p = PreString("")
m.stmt("foo")
m.stmt(p)
m.stmt("bar")
p.body.append("*inner*")
print(m)
もちろん、以前紹介したsubmoduleを使っても良いですが。PreStringはもっとも基礎的なオブジェクトなので単なる文字列を後に設定したい場合にはこちらを使った方が良いです。
foo
*inner*
bar
ちょっとわかりにくいのですが最後に型名を決定しています。具体的には以下の様な形で決めています。
# 引数として減点するような言葉の表を渡す
name_score_map={"parent": -1, '': -10}
# emitする前の段階で型名を決定する。ココで計算したnew_nameを型名として使うようにする
new_name = max(candidates, key=lambda k: name_score_map.get(k.lower(), 0))
出力結果ではParentではなくSourceを使うようにしました。このあたりの実装は好みや各個人の趣向で決めるものかもしれません。例えば、変換後の名前を直接指定するみたいなことができても良いかもしれません。その場合には絞り込みの条件として、単なるnameではなくtoplevelの型を含めた探索時のpathのようなものが引数に渡ってくるようにすると便利かもしれません。
何はともあれ出力時の型名をよりマシな名前にすることができました。
type AutoGenerated struct {
...
Parent Source `json:"parent"`
...
Source Source `json:"source"`
...
}
8. struct定義の先頭にコメントを付ける(golint対応)
コードを生成するツールがgoにも結構存在します。これはただの愚痴ですが、golang/mockのmockgenが生成するコードは、定義の先頭にコメントを付けてくれません。これがgolang/lintに叱られるのですごい邪魔みたいな気持ちになったりします。
そしてこれは自動生成の常なのですが、golang/mockので生成されたコードにコメントを付け足して対応などとすると、元のinterfaceの定義が代わり再度生成し直すとなった場合に全部消えてしまいます。しょうがないのでgolintの対象から外すみたいな特別な処理をしないといけません。だるいですね。
そう言えば、こちらのコードの生成結果も定義の先頭にコメントが付いていないので付けましょう。
変更箇所は1行でした。prstring.PreStringを使っているためprestring.LazyFormatを使う必要がありますが。1行付け足すだけです。消化試合に近い。
9. せっかくなので元のJSONの値をexampleとしてtagに付加
ついでにどんな値が入るかも元のJSONの値をexampleとしてtagに含めてみましょう。
変更箇所は数行でした。そろそろ飽きてきたので終わりにしようと思います。
以下の様な形で出力される様になりました。
// AutoGenerated : auto generated JSON container
type AutoGenerated struct {
CloneURL strfmt.Uri `json:"clone_url" example:"https://github.com/octocat/Hello-World.git"`
CreatedAt time.Time `json:"created_at" example:"2011-01-26T19:01:12Z"`
DefaultBranch string `json:"default_branch" example:"master"`
Description string `json:"description" example:"This your first repo!"`
...
最終的なコードはこちらです。
最初と最後のコードと出力結果だけ下に載せておきます。
(重複定義を解消したことによる副作用)
ちょっとだけ寄り道です。一時の気の迷いでフラットな形式の出力を選択してみることにしたのですが。その過程で重複定義を除去する機能を付け足しました。この重複定義の除去なのですが思わぬ副作用がありました。ちょっとしたおまけみたいなものですが紹介しておきます。
例えば以下のようなJSONを見てみてください。
{
"total": 100,
"left": {
"total": 75,
"left": {
"total": 25,
"left": {
"total": 20
},
"right": {
"total": 5
}
},
"right": {
"total": 50,
"left": {
"total": 25
},
"right": {
"total": 25
}
}
},
"right": {
"total": 25,
"left": {
"total": 20,
"left": {
"total": 10
},
"right": {
"total": 10
}
},
"right": {
"total": 5
}
}
}
これはテキトウな2分木めいた何かなのですが。
これを元のネストした形式で出力すると以下の様になります。渡されたJSON値に直接対応する型を生成してしまっているので無駄なstruct定義があるばかりでなく、ちょっとでも構造が変わった場合にparseできなくなります。悪い。
type Tree struct {
Left struct {
Left struct {
Left struct {
Total int `json:"total"`
} `json:"left"`
Right struct {
Total int `json:"total"`
} `json:"right"`
Total int `json:"total"`
} `json:"left"`
Right struct {
Left struct {
Total int `json:"total"`
} `json:"left"`
Right struct {
Total int `json:"total"`
} `json:"right"`
Total int `json:"total"`
} `json:"right"`
Total int `json:"total"`
} `json:"left"`
Right struct {
Left struct {
Left struct {
Total int `json:"total"`
} `json:"left"`
Right struct {
Total int `json:"total"`
} `json:"right"`
Total int `json:"total"`
} `json:"left"`
Right struct {
Total int `json:"total"`
} `json:"right"`
Total int `json:"total"`
} `json:"right"`
Total int `json:"total"`
}
一方、これを重複定義を排除したフラットな形式で出力すると以下の様になります(構造を明示したコメントは邪魔なので省いています)。単なる再帰的な定義なので当然ですね。良い。(ただしこのままだとzero valueが定まらずに無限に再帰してしまうのでエラーになりますね。*Treeにならないとダメです。めんどくさがって全部のstructへの参照をポインターにしてしまうか。真面目に参照の循環を探して終端を決めていくか)
// Tree : auto generated JSON container
type Tree struct {
Left Tree `json:"left"`
Right Tree `json:"right"`
Total int `json:"total" example:"100"`
}
さいごに
長くなってしまいましたがこれでおしまいです。
この記事ではgoのコードを生成するpythonのコードを書いてみました。具体的には、JSON-to-GoのJSONからgoのstruct定義の変換と似たような処理をpythonで実装してみました。その後その時々の気分に任せてコードに変更を加え出力結果を変えていきながらあれこれ思うことを呟いていきました。
その過程で思ったことを少しだけ書いてみると、車輪の再発明(この場合は再実装)は案外悪くないものなのかもしれないということでした。まず第一に全ての内容を把握しきった実装が手に入ります。その実装はどこにどのような修正をすれば良いのか分かる上に、何だか自分のものになったような感じもして、あれこれ手を加えてみたくなります。そこからは個人的な探索の始まりです。この部分をこう変えてみたらどうだろう?と少しずつ変更を加え、その変更結果と元の結果との差分を見比べていく内に元の実装を作った人が行なった割り切りや考え方みたいなものが見えてくることもあるかもしれません。例えば、今回の例で言うと、ネストした出力を選択したことの妙などです。
そして今回はgoの型を考慮しない形での自動生成でしたが。次回はgoの型を考慮した形での自動生成について書けたら良いなと思いました。
ちなみに、今回の用途に限っていうと特にpythonで再実装する必要もなく、go製のJSONからgoのstructの定義を出力するツールとして以下があったりします。
追記:
今年のアドベントカレンダーでもgojsonに触れている人がいました。