http://scikit-learn.org/0.18/tutorial/machine_learning_map/index.html をgoogle翻訳した
チュートリアル 目次 / 前のチュートリアル
適切な推定器の選択
多くの場合、機械学習の問題を解決する最も難しい部分は、その仕事のための正しい推定器を見つけることです。
データの種類や問題ごとに、適した推定器は異なります。
以下のフローチャートは、どの推定器でデータを試してみるかという大まかなガイドをユーザーに提供することを目的としています。
下の図の見積もりをクリックすると、そのドキュメントが表示されます。(訳注:クリックできません)
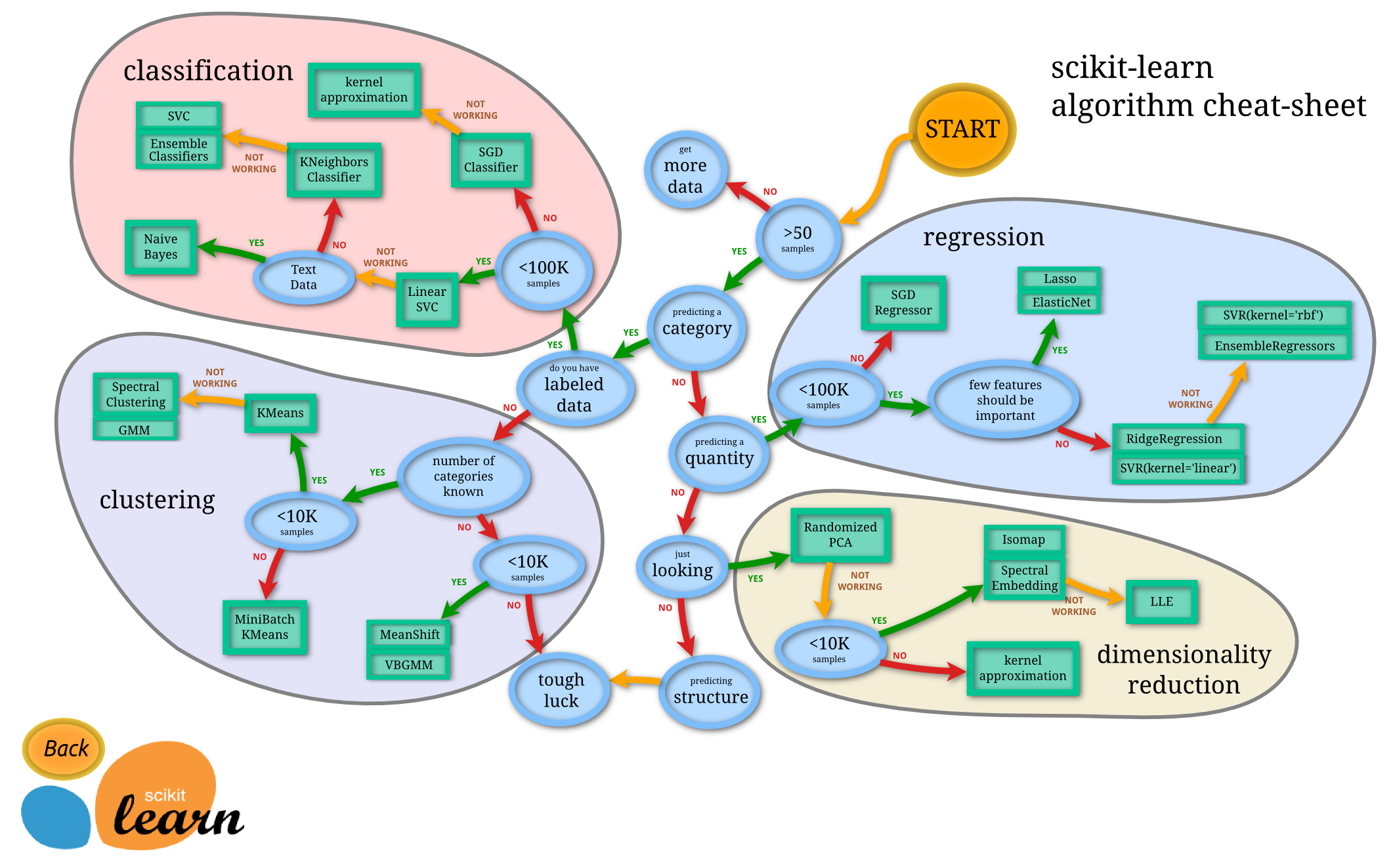
scikit-learnアルゴリズムチートシート
開始
- サンプルが50以上あるか?
- NO → もっとデータを集めましょう
- yes ↓
- カテゴリを推定したい?
- Yes → ラベル付けされた教師データがある?
- ある → 分類
- ない → クラスタリング
- No
- 量を予想したい? yes → 回帰
- 見るだけ? yes → 次元削減
- 構造を予想したい?
- ついてないね・・・
- Yes → ラベル付けされた教師データがある?
分類
- サンプルは10万より少ない?
- Yes
- No
クラスタリング
- カテゴリがいくつあるか知ってる?
- 知ってる
- 1万サンプルより少ない?
- Yes↓
- k平均法(KMeans)
- うまくいかない↓
- スペクトラルクラスタリング
- 混合ガウスモデル(GMM)
- no
- 知らない
回帰
- サンプルは10万より少ない?
- no → 確率的勾配法の回帰
- yes ↓
- 重要な特徴はほとんどない?
- yes
- no
- リッジ回帰
- SVR(kernel='linear')
- これらがうまく動かない ↓
- アンサンブル法
- SVR(kernel='rbf')
次元削減
- Randomized PCA
- うまくいかない ↓
- 10万サンプルより少ない?
- no → カーネル近似
- yes ↓
- Isomap
- スペクトル埋め込み(ラプラス固有写像)
- うまく動かない↓
- LLE
©2010 - 2016、scikit-learn developers(BSDライセンス)。