http://scikit-learn.org/stable/tutorial/basic/tutorial.html を google翻訳した。
scikit-learn 0.18 チュートリアル 目次
セクションの内容
このセクションでは、scikit-learn で使用される機械学習の用語を紹介し、簡単な学習の例を示します。
機械学習:問題の設定
一般に、学習問題は、n個のデータサンプルの集合を考慮し、未知のデータの特性を予測しようとする。各サンプルが単一の数値よりも大きい場合、または多次元項目(多変量とも呼ばれます)の場合は、いくつかの属性または特徴量を持つと言われます。
大きなカテゴリで学習問題をいくつかに分けることができます:
-
教師あり学習では、学習データには予測したい属性が追加されています(ここをクリックしてscikit-learn教師付き学習ページにアクセスしてください)。この問題は次のいずれかになります。
- 分類:標本は2つ以上のクラスに属し、ラベル付けされていないデータのクラスを予測する方法を既にラベル付けされたデータから学習したいと考えています。分類問題の例は、手書き数字認識であり、その目的は、各入力ベクトルを有限数の離散カテゴリの1つに割り当てることである。分類を考えるもう一つの方法は、限られた数のカテゴリーしか持たず、提供されたn個のサンプルのそれぞれについて、正しいカテゴリーまたはクラスでそれらをラベル付けしようとする、独立型(連続的ではなく)連続型の教師あり学習である。
- 回帰:所望の出力が1つ以上の連続変数からなる場合、タスクは回帰と呼ばれます。回帰問題の例は、年令と体重の関数としてサケの長さを予測することです。
- 教師なし学習では学習用データは、対応する目標値のない入力ベクトルxの集合である。このような問題の目標は、クラスタリングと呼ばれるデータ内の類似した例のグループを発見したり、密度推定と呼ばれる入力空間内のデータの分布を決定したり、高次元視覚化の目的のために、2次元または3次元の空間(Scikit-Learn unsupervised learningページに行くにはここをクリックしてください)。
トレーニングセットとテストセット
機械学習の目的は、データセットのいくつかの特性を学習し、それらを新しいデータに適用することです。機械学習でアルゴリズムを評価する一般的な方法では、手元にあるデータを2つのセットに分けます。1つはデータ特性を学習する トレーニングセット と呼ばれ、もう1つは特性をテストする テストセット と呼ばれます。
サンプルデータセットの読み込み
scikit-learnには、分類のための iris や digits のデータセットや、回帰のための ボストンの住宅価格 のデータセットなど、いくつかの標準データセットが付属しています。
以下では、シェルからPythonインタプリタを起動し、iris と digits のデータセットをロードします。私たちの表記法では、 $ はシェルプロンプトを表し、 >>> はPythonインタプリタプロンプトを表します。
$ python
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> digits = datasets.load_digits()
データセットは、すべてのデータとそのデータに関する一部のメタデータを保持する辞書的なオブジェクトです。このデータは .data メンバーに格納されます。これは n_samples, n_features の配列です。教師ありの場合、1つ以上の応答変数が .target メンバーに格納されます。異なるデータセットの詳細については、専用セクション を参照してください。
たとえば、digits データセットの場合、 digits.data は、数字サンプルを分類するために使用できる特徴量にアクセスします。
>>> print(digits.data)
[[ 0. 0. 5. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 10. 0. 0.]
[ 0. 0. 0. ..., 16. 9. 0.]
...,
[ 0. 0. 1. ..., 6. 0. 0.]
[ 0. 0. 2. ..., 12. 0. 0.]
[ 0. 0. 10. ..., 12. 1. 0.]]
digits.target は、digits データセットの根拠となる真理値を返します。これは、学習しようとしている各数字の画像に対応する数字です。
>>> digits.target
array([0, 1, 2, ..., 8, 9, 8])
データ配列の形状
元のデータの形状は異なっていても、データは常に2次元配列、形状 (n_samples, n_features) です。数字の場合、各元のサンプルは形状の画像 (8,8) であり、以下を使用してアクセスすることができます。
>>> digits.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])
この データセットの簡単な例 は、元の問題から始まってscikit-learnで消費するデータをどのように形成できるかを示しています。
外部データセットからのロード
外部データセットからロードするには、外部データセットのロード を参照してください。
学習と予測
digits データセットの場合、タスクは、画像が与えられると、それがどの数字を表すかを予測することである。未知のサンプルが属するクラスを予測できるように、推定器 には10の可能クラス(ゼロから9までの数字)のサンプルがそれぞれ与えられます。
scikit-learnでは、分類のための推定器は fit(X, y) と predict(T) のメソッドを実装するPythonオブジェクトです。
推定器の例は、サポートベクター分類を実装するクラス sklearn.svm.SVC です。推定器のコンストラクタは引数としてモデルのパラメータをとりますが、当面は推定器をブラックボックスと見なします:
>>> from sklearn import svm
>>> clf = svm.SVC(gamma=0.001, C=100.)
モデルのパラメータの選択
この例では、gammaの値を手動で設定します。グリッド検索 や クロスバリデーション などのツールを使用すると、パラメータの適切な値を自動的に見つけることができます。
推定器のインスタンスを clf としましたが、これは分類器であるためです。モデルに fit させる必要があります。つまり、モデルから学習する必要があります。これは、トレーニングセットを fit メソッドに渡すことによって行われます。トレーニングセットとして、最後のを除く、データセットのすべての画像を使用しましょう。このトレーニングセットは、 [:-1] Python構文で選択します。これは、digits.data の最後のエントリ以外のすべてを含む新しい配列を生成します。
>>> clf.fit(digits.data[:-1], digits.target[:-1])
SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
新しい値を予測できるようになりました。では、分類器をトレーニングするために使用していなかった、digits データセットの最後の画像はどの数字ですか?
>>> clf.predict(digits.data[-1:])
array([8])
対応するイメージは次のとおりです。
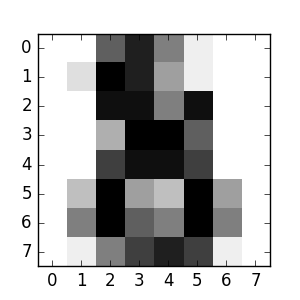
ご覧のとおり、これは難しい課題です。画像の解像度が低いです。あなたは分類器に同意しますか?
この分類問題の完全な例は、実行して学習できる例として利用できます。手書き数字の認識
モデルの永続性
Pythonの組み込み永続化モジュール、つまりpickleを使って、scikitのモデルを保存することが可能です:
>>> from sklearn import svm
>>> from sklearn import datasets
>>> clf = svm.SVC()
>>> iris = datasets.load_iris()
>>> X, y = iris.data, iris.target
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> import pickle
>>> s = pickle.dumps(clf)
>>> clf2 = pickle.loads(s)
>>> clf2.predict(X[0:1])
array([0])
>>> y[0]
0
scikitの特定のケースでは、joblibのpickle( joblib.dump および joblib.load )の置き換えを使用する方がよいかもしれません.ただ、大きなデータに対してはより効率的ですが、ディスクにしか保存できません。
>>> from sklearn.externals import joblib
>>> joblib.dump(clf, 'filename.pkl')
後でpickleされたモデルを(おそらく別のPythonプロセスで)ロードすることができます:
>>> clf = joblib.load('filename.pkl')
注意
joblib.dump関数とjoblib.load関数は、ファイル名の代わりに file-like オブジェクトも受け入れます。 Joblibでのデータ永続性の詳細は、 こちら を参照してください。
pickleにはセキュリティと保守性の問題がいくつかあることに注意してください。 scikit-learnによるモデルの永続性の詳細については、「モデルの永続性」を参照してください。
規約
scikit-learn推定器は、その行動をより予測的にするために一定の規則に従う。
タイプキャスト
特に指定しない限り、入力は float64 にキャストされます:
>>> import numpy as np
>>> from sklearn import random_projection
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(10, 2000)
>>> X = np.array(X, dtype='float32')
>>> X.dtype
dtype('float32')
>>> transformer = random_projection.GaussianRandomProjection()
>>> X_new = transformer.fit_transform(X)
>>> X_new.dtype
dtype('float64')
この例では、 X は float32 であり、 fit_transform(X) によって float64 にキャストされます。
回帰ターゲットは float64 にキャストされ、分類ターゲットは維持されます。
>>> from sklearn import datasets
>>> from sklearn.svm import SVC
>>> iris = datasets.load_iris()
>>> clf = SVC()
>>> clf.fit(iris.data, iris.target)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> list(clf.predict(iris.data[:3]))
[0, 0, 0]
>>> clf.fit(iris.data, iris.target_names[iris.target])
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> list(clf.predict(iris.data[:3]))
['setosa', 'setosa', 'setosa']
ここで、最初の predict() は iris.target(整数配列)が fit で使用されたため、整数配列を返します。 2番目の predict() は文字列配列を返します。なぜなら、iris.target_names はフィッティングのためであったからです。
パラメーターの更新と更新
推定器のハイパーパラメータは、 sklearn.pipeline.Pipeline.set_params メソッドを使用して作成した後に更新できます。 fit() を複数回呼び出すと、以前の fit() によって学習されたものが上書きされます:
>>> from sklearn.svm import SVC
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(100, 10)
>>> y = rng.binomial(1, 0.5, 100)
>>> X_test = rng.rand(5, 10)
>>> clf = SVC()
>>> clf.set_params(kernel='linear').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([1, 0, 1, 1, 0])
>>> clf.set_params(kernel='rbf').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([0, 0, 0, 1, 0])
ここでは、デフォルトカーネル rbf は、 SVC() を介して推定器が構築された後に最初に線形に変更され、 rbf に戻って推定器を再構成し、第2の予測を行う。
マルチクラスとマルチラベルのフィッティング
マルチクラス分類器 を使用する場合、実行される学習および予測タスクは、ターゲットデータのフォーマットに依存します。
>>> from sklearn.svm import SVC
>>> from sklearn.multiclass import OneVsRestClassifier
>>> from sklearn.preprocessing import LabelBinarizer
>>> X = [[1, 2], [2, 4], [4, 5], [3, 2], [3, 1]]
>>> y = [0, 0, 1, 1, 2]
>>> classif = OneVsRestClassifier(estimator=SVC(random_state=0))
>>> classif.fit(X, y).predict(X)
array([0, 0, 1, 1, 2])
上記の場合、クラシファイアはマルチラベルの1次元配列に適合し、したがって predict() メソッドは対応するマルチクラス予測を提供します。バイナリラベルインジケータの2次元配列に適合させることも可能です:
>>> y = LabelBinarizer().fit_transform(y)
>>> classif.fit(X, y).predict(X)
array([[1, 0, 0],
[1, 0, 0],
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]])
ここで、分類器は LabelBinarizer を使用して y の2次元バイナリラベル表現に fit() します。この場合、 predict() は対応するマルチラベル予測を表す2次元配列を返します。
4番目と5番目のインスタンスがすべて0を返し、3つのラベルのどれにも fit しないことを示しています。マルチラベル出力では、インスタンスに複数のラベルを割り当てることも同様に可能です。
>> from sklearn.preprocessing import MultiLabelBinarizer
>> y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]]
>> y = preprocessing.MultiLabelBinarizer().fit_transform(y)
>> classif.fit(X, y).predict(X)
array([[1, 1, 0, 0, 0],
[1, 0, 1, 0, 0],
[0, 1, 0, 1, 0],
[1, 0, 1, 1, 0],
[0, 0, 1, 0, 1]])
この場合、分類器は、それぞれ複数のラベルが割り当てられたインスタンスに適合する。 MultiLabelBinarizer は、マルチラベルの2次元配列を2進化するために使用されます。その結果、 predict() は、インスタンスごとに複数の予測ラベルを持つ2次元配列を返します。
©2010 - 2016、scikit-learn developers(BSDライセンス)。