やりたいこと
Juliusには認証スピードを上げる為に、読みファイルと文法ファイルというものが用意されているようです。
どちらが使い勝手がいいのか試してみます。
背景
自分の問いかけたことに答えてくれるRaspberryPiロボ作成に向け、Juliusの音声認証を試してみる。
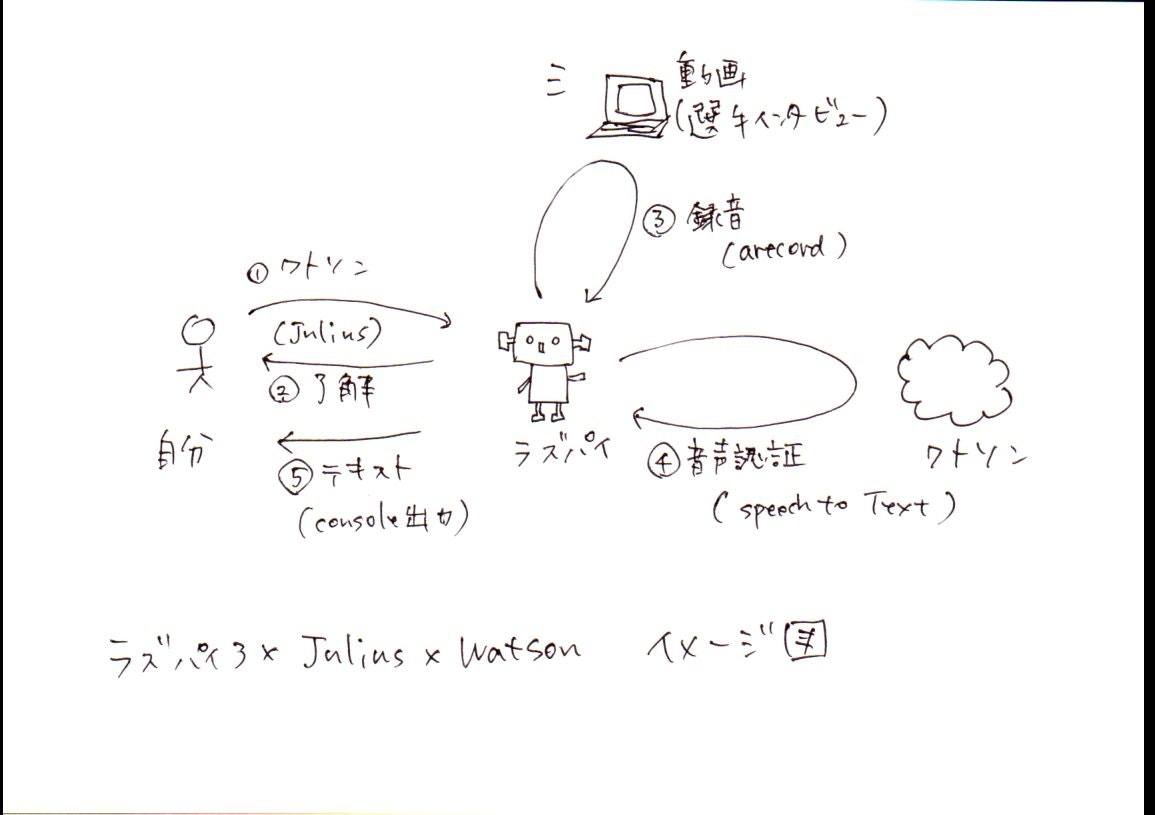
下図のような、Raspberry Pi3×Julius×Watson(Speech to Text)で音声認証&文字おこしが最終ゴール。
(http://qiita.com/nanako_ut/items/1e044eb494623a3961a5)
今回は下図の①と②部分のJuliusを検証する。
環境
- Raspberry Pi3
- USBマイク(SANWA SUPPLY MM-MCUSB16 USBマイクロホン)
- julius 4.3.1(オープンソース音声認識ライブラリ)
前提
以下は準備済とします。
参考までに自分が参考にさせてもらったサイトのリンクを記載
- Raspberry Pi3でマイクを使えるようにする
- Raspberry Pi3へのJuliusインストール
手順
1.読みファイル作成
2.文法ファイル作成
3.pythonでjuliusでの音声を解析
4.まとめ(読みファイルと文法ファイルとの違い)
■ 読みファイル
1.1 読みファイルを作成
$ cat julius_watson.yomi
ラズパイ らずぱい
ワトソン開始 わとそんかいし
ワトソン終了 わとそんしゅうりょう
テスト てすと
開始 かいし
終了 終了
終わり おわり
返事して へんじして
何か言って なにかいって
よろしく よろしく
1.2 辞書形式に変換
iconv -f utf8 -t eucjp ~/julius_watson.yomi | ~/julius-kits/dictation-kit-v4.3.1-linux/bin/yomi2voca.pl > ~/julius-kits/dictation-kit-v4.3.1-linux/julius_watson.dic
1.3 設定ファイルを作成
$ cat ~/julius-kits/dictation-kit-v4.3.1-linux/julius_watson.jconf
-w julius_watson.dic ←上記で辞書形式に変換した.dicを指定
-v model/lang_m/bccwj.60k.htkdic
-h model/phone_m/jnas-tri-3k16-gid.binhmm
-hlist model/phone_m/logicalTri
-lmp 8.0 -2.0
-lmp2 8.0 -2.0
-b 1500
-b2 100
-s 500
-m 10000
-n 30
-output 1
-input mic
-zmeanframe
-rejectshort 800
-charconv EUC-JP UTF-8
1.4 実行
$ cd julius-kits/dictation-kit-v4.3.1-linux
~/julius-kits/dictation-kit-v4.3.1-linux $ julius -C julius_watson.jconf -demo
STAT: include config: julius_watson.jconf
WARNING: m_chkparam: "-lmp" only for N-gram, ignored
WARNING: m_chkparam: "-lmp2" only for N-gram, ignored
STAT: jconf successfully finalized
~途中略~
----------------------- System Information end -----------------------
Notice for feature extraction (01),
*************************************************************
* Cepstral mean normalization for real-time decoding: *
* NOTICE: The first input may not be recognized, since *
* no initial mean is available on startup. *
*************************************************************
Stat: adin_oss: device name = /dev/dsp (application default)
Stat: adin_oss: sampling rate = 16000Hz
Stat: adin_oss: going to set latency to 50 msec
Stat: adin_oss: audio I/O Latency = 32 msec (fragment size = 512 samples)
STAT: AD-in thread created
pass1_best: よろしく ← 物音
sentence1: よろしく ← 物音
pass1_best: よろしく ← 「よろしく」と発声
sentence1: よろしく
pass1_best: ワトソン ← 「ワトソン」と発声
sentence1: ワトソン
pass1_best: ワトソン開始 ←「ワトソン開始」と発声
sentence1: ワトソン開始
pass1_best: ラズパイ ←「お腹いたい」と発声
sentence1: ラズパイ
<<< please speak >>>^C
1.5 所感
物音でも「よろしく」と表示されてしまう、、、、
判定できない言葉はすべて読みファイルの最後の文字で解釈されてしまう??
■ 文法ファイルを作成
2.1 voca ファイルに発音音素列?を記述
$ cat julius_watson.voca
ワトソン w a t s n
ラズパイ r a z u p a i
NFL a m e f u t o
電気 d e n k i
% WO
を w o
% PLEASE
つけて t u k e t e
消して k e sh i t e
% NS_B
[s] silB
% NS_E
[s] silE
2.2 構文制約を行うための grammar ファイルを作成
cat julius_watson.grammar
S : NS_B WATSON_ PLEASE NS_E
WATSON_ : WATSON
WATSON_ : WATSON WO
2.3 文法ファイル・構成制約ファイル等をコンパイル
cp julius-4.3.1/gramtools/mkdfa/mkfa-1.44-flex/mkfa julius-4.3.1/gramtools/mkdfa/mkfa
cp julius-4.3.1/gramtools/dfa_minimize/dfa_minimize julius-4.3.1/gramtools/mkdfa/dfa_minimize
sudo julius-4.3.1/gramtools/mkdfa/mkdfa.pl julius_watson
julius_watson.grammar has 3 rules
julius_watson.voca has 5 categories and 9 words
---
Now parsing grammar file
Now modifying grammar to minimize states[-1]
Now parsing vocabulary file
Now making nondeterministic finite automaton[6/6]
Now making deterministic finite automaton[6/6]
Now making triplet list[6/6]
5 categories, 6 nodes, 6 arcs
-> minimized: 6 nodes, 6 arcs
---
generated: julius_watson.dfa julius_watson.term julius_watson.dict
2.4 動作確認
Stat: adin_oss: device name = /dev/dsp (application default)
Stat: adin_oss: sampling rate = 16000Hz
Stat: adin_oss: going to set latency to 50 msec
Stat: adin_oss: audio I/O Latency = 32 msec (fragment size = 512 samples)
STAT: AD-in thread created
pass1_best: [s] ワトソン 開始 [s] ← 「ワトソン」と発声
pass1_best_wordseq: 3 0 2 4
pass1_best_phonemeseq: silB | w a t o s n | k a i s i | silE
pass1_best_score: -3108.902100
### Recognition: 2nd pass (RL heuristic best-first)
STAT: 00 _default: 23 generated, 23 pushed, 5 nodes popped in 122
sentence1: [s] ワトソン 開始 [s]
wseq1: 3 0 2 4
phseq1: silB | w a t o s n | k a i s i | silE
cmscore1: 1.000 0.482 0.476 1.000
score1: -3108.899414
pass1_best: [s] ラズパイ して [s] ← 「ラズパイ」と発声
pass1_best_wordseq: 3 0 2 4
pass1_best_phonemeseq: silB | r a z u p a i | s i t e | silE
pass1_best_score: -3268.691406
### Recognition: 2nd pass (RL heuristic best-first)
STAT: 00 _default: 23 generated, 23 pushed, 5 nodes popped in 132
sentence1: [s] ラズパイ して [s]
wseq1: 3 0 2 4
phseq1: silB | r a z u p a i | s i t e | silE
cmscore1: 1.000 0.959 0.691 1.000
score1: -3268.694824
<<< please speak >>>
2.5 所感
単語を発音した場合、名詞+動詞を補って解釈してしまう??
イマイチ感あり。。。言っていないことを補ってしまうのはちょっと・・・。
■ pythonでjuliusでの音声を解析
-module オプションをつけると、他モジュールからJuliusへ接続できるらしい。
ということで、-module オプションをつけてJuliusを起動し、pythonからjuliusサーバへ接続・解析結果を出力してみます。
3.1 pythonプログラム
Julius接続&解析結果出力プログラム。
どなたか先人の方のソースをコピペさせてもらったのですが、、、引用元を見失ってしまいました。。。
判明し次第、更新します。
# !/usr/bin/python
# -*- coding: utf-8 -*-
import socket
import cStringIO
host = 'XXX.XXX.XX.XX' #←ローカルのホストアドレスを記載
port = 10500
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
xml_buff = ""
in_recoguout = False
while True:
data = cStringIO.StringIO(sock.recv(4096))
line = data.readline()
while line:
if line.startswith(""):
in_recoguout = True
xml_buff += line
elif line.startswith(""):
xml_buff += line
print xml_buff
in_recoguout = False
xml_buff = ""
else:
if in_recoguout:
xml_buff += line
line = data.readline()
sock.close()
3.2 実行
まずは、Juliusをモジュールモードで起動しておく
~/julius-kits/dictation-kit-v4.3.1-linux $ julius -C main.jconf -C am-gmm.jconf -module
実行結果
$ python Julius_test.py
<RECOGOUT>
<SHYPO RANK="1" SCORE="-5520.531738">
<WHYPO WORD="" CLASSID="<s>" PHONE="silB" CM="0.200"/>
<WHYPO WORD="音声" CLASSID="音声+名詞" PHONE="o N s e:" CM="0.187"/>
<WHYPO WORD="認証" CLASSID="認証+名詞" PHONE="n i N sh o:" CM="0.074"/>
<WHYPO WORD="テスト" CLASSID="テスト+名詞" PHONE="t e s u t o" CM="0.273"/>
<WHYPO WORD="。" CLASSID="</s>" PHONE="silE" CM="1.000"/>
</SHYPO>
</RECOGOUT>
■ まとめ(読みファイルと文法ファイルとの違い)
モジュールモード実行時の違いについてまとめます。
4.1 実行方法
■読みファイル
cd julius-kits/dictation-kit-v4.3.1-linux
julius -C julius_watson.jconf -module
■文法ファイル
julius -C julius-kits/grammar-kit-v4.1/hmm_mono.jconf -input mic -gram julius_watson
※.hmm_mono.jconf中に、-module オプションを記載
4.2 実行結果
「ワトソン開始」と言った結果
■文法ファイル
<RECOGOUT>
<SHYPO RANK="1" SCORE="-2817.017578" GRAM="0">
<WHYPO WORD="[s]" CLASSID="3" PHONE="silB" CM="1.000"/>
<WHYPO WORD="ワトソン" CLASSID="0" PHONE="w a t s n" CM="0.973"/>
<WHYPO WORD="消して" CLASSID="2" PHONE="k e s h i t e" CM="0.560"/>
<WHYPO WORD="[s]" CLASSID="4" PHONE="silE" CM="1.000"/>
</SHYPO>
</RECOGOUT>
■読みファイル
<RECOGOUT>
<SHYPO RANK="1" SCORE="-2903.453613" GRAM="0">
<WHYPO WORD="ワトソン" CLASSID="ワトソン" PHONE="silB w a t o s o N silE" CM="0.791"/>
</SHYPO>
</RECOGOUT>
<RECOGOUT>
<SHYPO RANK="1" SCORE="-8478.763672" GRAM="0">
<WHYPO WORD="ワトソン開始" CLASSID="ワトソン開始" PHONE="silB w a t o s o N k a i sh i silE" CM="1.000"/>
</SHYPO>
</RECOGOUT>
4.3 考察
「ワトソン開始」と言った場合
・文法ファイル⇒「ワトソン」でヒットした「ワトソン消して」の確度高いぞ、と返信してくる。
・読みファイル⇒名詞と動詞を分けているので「ワトソン」と「ワトソン開始」を別々に判定してくれる。
⇒文法ファイルは単語で登録する使い方??文章と言わなくても名詞+動詞で話しかけた場合、かなり誤認識が多くなってしまいそう。
今回は、文法ファイルの方がよさそう。
最後に
raspberryPi2だと動作が遅いという記述もあったJuliusですが、raspbeerypi3だとかなり速い感じがしました。
認証スピード向上目的であれば、読みファイル、文法ファイルなくてもいいのかもしれません。
話しかける言葉がある程度限定できる場合は、認証率向上のために読みファイル、文法ファイルを使うのかな、と思いました。