はじめに
オープンデータの活用例として何かいい材料がないかな〜と探していたら、データシティ鯖江のサイトにて、水位データが公開されているのを見つけたので、これを使って機械学習を試してみました。
データのダウンロード
上記サイトにある「オープンデータ」のページで「防災」のグループに以下の表記があります。
水位データ(福井県鯖江市)
論手川排水機場 [CSV]
鯖江市内にある水位計のデータです。 水位の単位 : cm データ : 1000件
標準では1,000件のデータとのことなのですが、ごにょごにょするともう少し多く取得できたのでそれを使用します。
また、気象庁から過去の気象データがダウンロードできるので、近くにある福井市の降水量データをダウンロードします。
ライブラリの読込
Jupyter Notebookを使用し、以下のライブラリを読み込みます。
from ipywidgets import FloatProgress
from IPython.display import display
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import datetime
水位データの読込
filename = "sparql.csv"
df = pd.read_csv(filename, header=None)
グラフで表示してみる。
tmp = []
for i in range(len(df)):
pos = len(df) - 1 - i
tmp.append(df.ix[pos][2])
pd.DataFrame({'level': np.array(tmp)}).plot(figsize=(15,5))
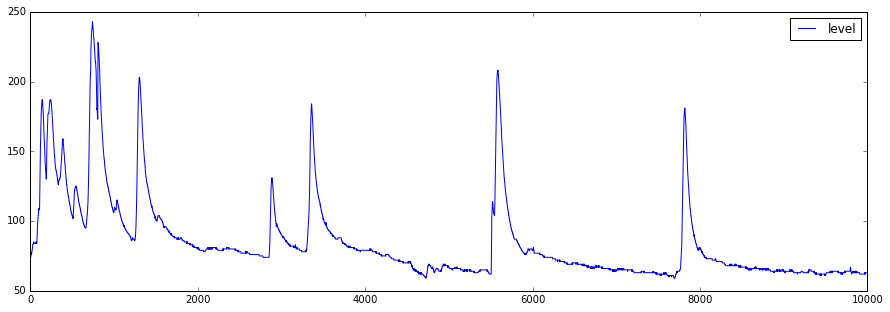
水位データは5分間隔で取得されており、気象庁のデータと時系列をあわせるためにデータを加工します。
# データの開始日と終了日の取得
dt1 = datetime.datetime.strptime(df[1][len(df)-1],"%Y-%m-%dT%H:%M:%S+09:00")
dt1 = datetime.datetime(dt1.year,dt1.month,dt1.day,0,0)
dt2 = datetime.datetime.strptime(df[1][0],"%Y-%m-%dT%H:%M:%S+09:00")
print("dt1:",dt1)
print("dt2:",dt2)
# データの日数を取得
dt = (dt2-dt1).days + 1
# 1時間毎のデータを格納する配列を準備
level = [0] * dt * 24
dt_al = [0] * dt * 24
# プログレスバーの設定
fp = FloatProgress(min=0, max=len(df))
display(fp)
for i in range(len(df)):
wk = datetime.datetime.strptime(df[1][len(df)-i-1],"%Y-%m-%dT%H:%M:%S+09:00")
pos = (wk - dt1).days * 24 + wk.hour
dt_al[pos] = datetime.datetime(wk.year,wk.month,wk.day,wk.hour,0)
if wk.minute == 0:
level[pos] = df[2][len(df)-1-i]
fp.value = i
降水量データの読込
CSVに数行いらないデータが入っていることと、文字コードがシフトJISであることに注意してデータを読み込む。
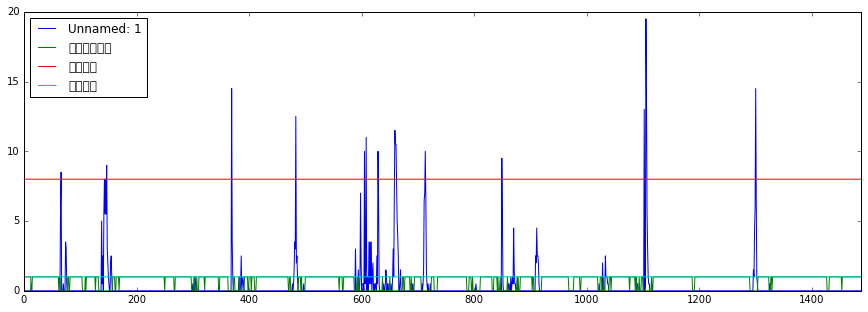
また、読み込んだデータをグラフ表示してみる。
filename = "data.csv"
df = pd.read_csv(filename,encoding="SHIFT-JIS",skiprows=4)
df.plot(figsize=(15,5))
水位と降水量のデータを同じ形式の配列に格納
データを扱いやすくするために配列へ格納し、ついでにグラフ表示をしてみる。
# 配列の準備
rain = [0]*len(level)
for i in range(len(df)):
wk = datetime.datetime.strptime(df.ix[i][0],"%Y/%m/%d %H:%M:%S")
if (wk < dt2) and (wk - dt1).days >= 0:
pos = (wk - dt1).days * 24 + wk.hour
rain[pos] = df.ix[i][1]
# グラフでデータを確認する
pp = pd.DataFrame({'level': np.array(level), 'rain': np.array(rain)*15})
pp.plot(figsize=(15,5))
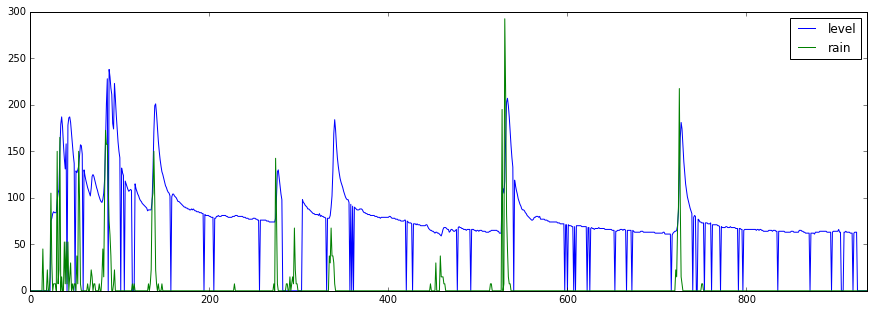
なんだか欠損データがたくさんありそう...(汗)
学習データの検討
グラフを見ると、雨が降った後に水位が増える傾向にあるようなので、48時間前からその時間までの降水量の情報を入力とし、水位を出力の教師データにしてみます。
# 48時間の降水量を二次元配列で取得
row = len(level)
tmp = np.zeros((row,48))
fp = FloatProgress(min=0, max=row)
display(fp)
for i in range(row):
for j in range(len(tmp[0])):
pos = row - 1 - i - j
tmp[row-1-i][j] = rain[pos]
fp.value = i
欠損データのトリミング
水位のデータが取得できていないものについては必要がないので除去します。
# 欠損データ数の確認
num = 0
for i in range(len(level)):
if level[i] == 0:
num += 1
# データ格納の準備
X = np.empty((0,48))
y = []
for i in range(len(level)):
if level[i] > 0:
X = np.append(X, np.array([tmp[i]]), axis=0)
y.append(level[i])
# グラフでデータを確認する
pp = pd.DataFrame({'level': np.array(y), 'rain': X[:,0]*20})
pp.plot(figsize=(15,5))
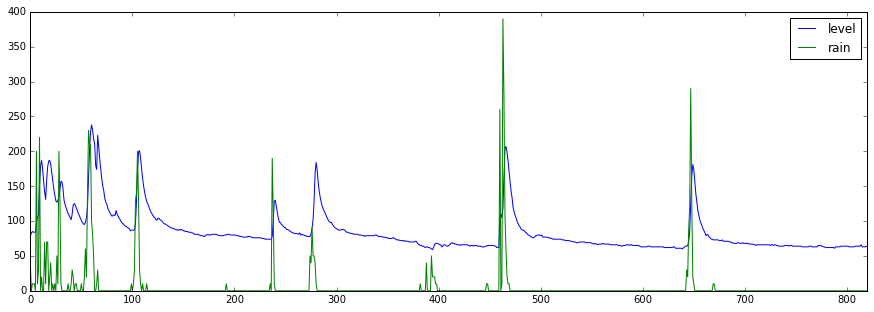
グラフを見ると結構綺麗になったのがわかる。
機械学習
クリーニングの終わったデータで学習し、予測した結果のスコアを確認する。
# クロスバリデーションのモジュールを読み込む
from sklearn import cross_validation
# ラベル付きデータをトレーニングセット (X_train, y_train)とテストセット (X_test, y_test)に分割
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=.2, random_state=42)
# 正規化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
# モデルの設定(ランダムフォレスト)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=200, max_depth=50, random_state=42)
# 学習と予測
model.fit(X_train, y_train)
result = model.predict(X_test)
result.shape
# スコア
print(model.score(X_test,y_test))
結果は...
0.185628742515
...だめじゃん!
結果の検証
スコアは低いけど、ちょっとグラフで結果を確認してみます。
pp = pd.DataFrame({'act': np.array(y_test), "pred": np.array(result)})
pp.plot(figsize=(15,5))
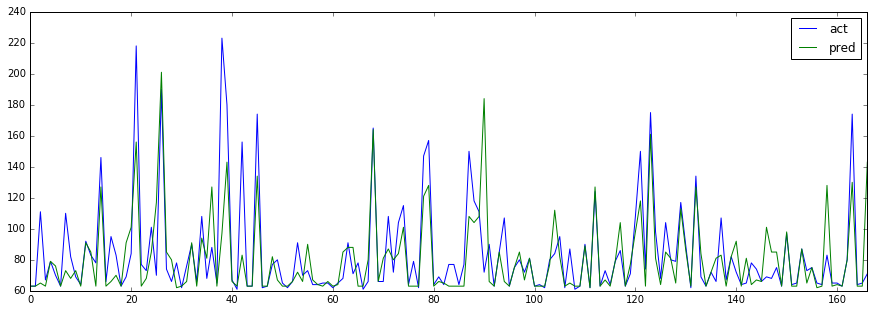
...う〜ん、微妙。
少し工夫し、以下のようにデータを時系列に分割して学習と予測をする。
num = int(len(X) * 0.8)
print(len(X), num, len(X)-num)
X_train = X[:num]
X_test = X[num:]
y_train = y[:num]
y_test = y[num:]
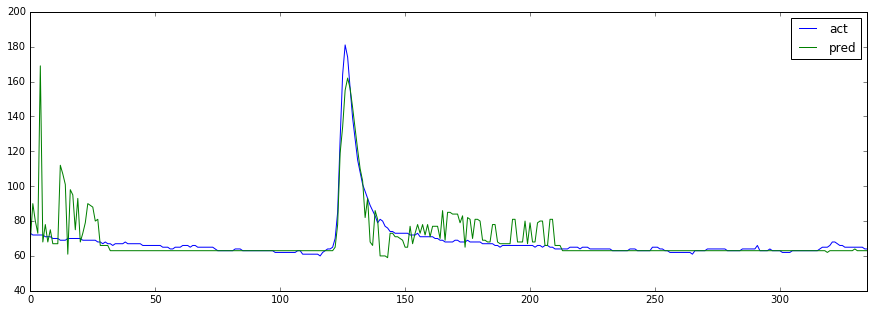
...なんと!
ちょっといい感じ(^-^)
では、この結果から何ができるかな〜と考えてみると、降水量から水位を継続的に予測することで急激な水位の上昇を検知し、避難警告をするということに使えるのではないでしょうか。
そう考えると、もっといろいろな自治体がこうしたデータを公開してくれるといいなと思いますね。
以上、次は何しようかな〜。
追記
本記事と異なる学習方法により精度を上げ、1時間後の水位を予測することができたので、改めて記事にしてみました。興味のある方は、以下のURLもあわせてご覧ください。