はじめに
以前、降水量から水位を予測する方法について解説しましたが、その後、色々調べてみると約95%の精度で1時間後の水位を予測することができるようになったので、改めて整理して記事にしてみます。
データシティ鯖江のオープンデータを使って水位計の値を機械学習で予測してみる
動作環境
| 項目 | 内容 |
|---|---|
| マシン | MacBook Air (13-inch, Early 2015) |
| プロセッサ | 2.2 GHz Intel Core i7 |
| メモリ | 8 GB 1600 MHz DDR3 |
| Python | 3.6.0 :: Anaconda 4.3.1 (x86_64) |
| Jupyter Notebook | 4.2.1 |
環境構築手順
いつもの手前味噌ですが、以下のURLをご参照下さい。
Macで深層学習の環境をさくっと作る手順 with TensorFlow and OpenCV
データのダウンロード
上記のWebサイトにて、「防災」のグループを選択すると以下の表記がありますので、「CSV」のボタンをクリックして、表示されたリンクからCSVをダウンロードします。
また、気象庁さんから過去の気象データがダウンロードできるので、福井市における1時間ごとの降水量のデータをダウンロードします。
ライブラリの読込
Jupyter Notebookを使用し、以下のライブラリを読み込みます。
from ipywidgets import FloatProgress
from IPython.display import display
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import datetime
水位データの読込
# ファイル読込
filename = "sparql.csv"
df_level = pd.read_csv(filename, header=None, skiprows=1)
# 列名の変更
df_level.columns = ["url","datetime","level"]
# 日時をタイムスタンプに変換
df_level["datetime"] = df_level.datetime.map(lambda _: pd.to_datetime(_))
# 日時をインデックスに設定
df_level.index = df_level.pop("datetime")
# 日時順に並べ替え(...しなくても動作すると思いますが、しておきます)
df_level = df_level.sort_index()
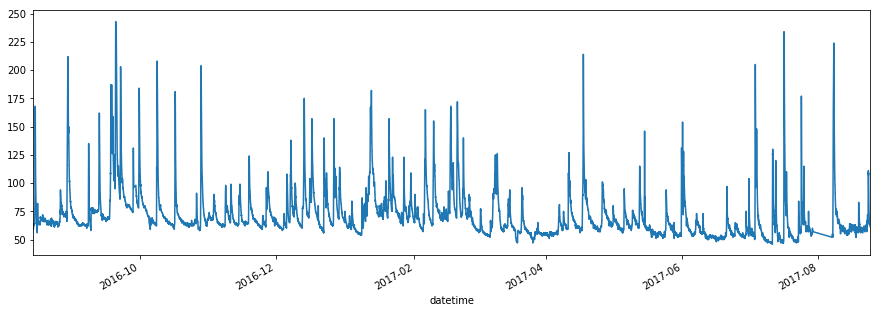
# グラフ表示
df_level["level"].plot(figsize=(15,5))
実行すると以下のグラフが表示されます。
降水量データの読込
CSVに数行いらないデータが入っていることと、文字コードがシフトJISであることに注意してデータを読み込み、グラフに表示してみます。
# ファイル読込
filename = "data.csv"
df = pd.read_csv(filename,encoding="SHIFT-JIS",skiprows=4)
# 列名の変更
df_rain.columns = ["datetime", "rain", "現象なし情報","品質情報","均質番号"]
# 日時をタイムスタンプに変換
df_rain["datetime"] = df_rain.datetime.map(lambda _: pd.to_datetime(_))
# 日時をインデックスに設定
df_rain.index = df_rain.pop("datetime")
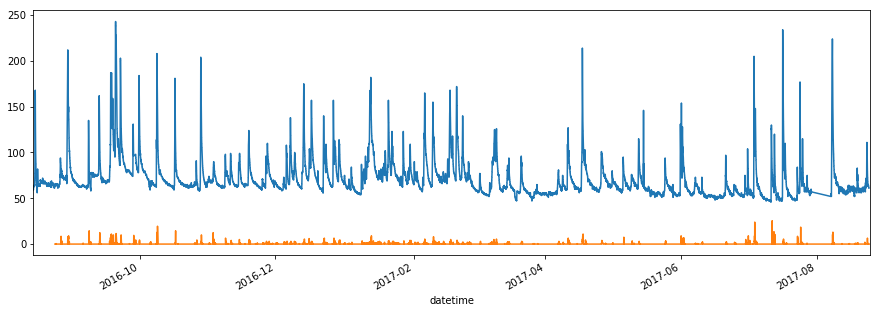
# グラフ表示
df_level.level.plot(figsize=(15,5))
df_rain.rain.plot(figsize=(15,5))
実行すると以下のグラフが表示されます。ちなみにオレンジ色が降水量です。
データ加工
今回は、1時間後の水位を予測するということから、1時間前の水位の変化と降水量を使って1時間後の最大水位を予測してみたいと思います。
ついては、学習データを以下のようにします。
| 入力 | 出力 |
|---|---|
| 1時間前の降水量 1時間前の5分ごと水位(10点) |
1時間後の最大水位 |
水位データは5分間隔のデータなので、本来であれば60分に12点のデータがあることになるが、いくつか欠損データがあり、タイミングによって12点以下のものも存在することから、若干の試行錯誤のうえで10点としています。
また、降水量のデータは、気象庁のサイトに「前1時間」という表記があることから、インデックスに設定してある日時の1時間前のデータであると考えます。
これを踏まえたうえで、データの加工方法は以下のとおりです。
# 降水量のインデックスを取得
ixs = df_rain.index
# データ取得用配列の作成
df = []
y = []
for i in range(len(ixs)-2):
# インデックスから日時を取得
dt1 = ixs[i]
dt2 = ixs[i + 1]
dt3 = ixs[i + 2]
# 日時データから水位データを取得
d1 = df_level[dt1:dt2].level.tolist()
d2 = df_level[dt2:dt3].level.tolist()
if len(d1) > 10 and len(d2) > 10:
# 1時間後の最大水位を取得
y.append(max(d2))
# 1時間前の水位データを高い順に並替
d1.sort()
d1.reverse()
# 10点のデータを取得
d1 = d1[:10]
# 降水量データを取得
d1.append(df_rain.ix[i].rain)
# 入力データの配列を取得
df.append(d1)
# データフレームに変換
df = pd.DataFrame(df)
df["y"] = y
# データ数の確認
print(df.shape)
実行すると(6863, 12)と表示され、6863行のデータが取得できていました。
機械学習
機械学習によりデータの前半9割を学習し、後半1割で学習結果の検証をしてみます。
# データを入力と出力に分割
y = df.pop("y").as_matrix().astype("int").flatten()
X = df.as_matrix().astype("float")
# 9割を学習、1割を検証に使用するために分割
num = int(len(X) * 0.9)
print(len(X), num, len(X)-num)
X_train = X[:num]
X_test = X[num:]
y_train = y[:num]
y_test = y[num:]
# 学習モデルとしてランダムフォレストを設定
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(random_state=42)
# 学習と検証
model.fit(X_train, y_train)
result = model.predict(X_test)
# スコア
print(model.score(X_test,y_test))
実行してみると、予測精度は「0.952915078747」でした。
数値ではよくわからないので、グラフを描画してみます。
pp = pd.DataFrame({'act': np.array(y_test), "pred": np.array(result), "rain": X_test[:,-1]})
pp.rain = pp.rain * 5
plt.figure(figsize=(15,5))
plt.ylim(0,250)
plt.plot(pp)
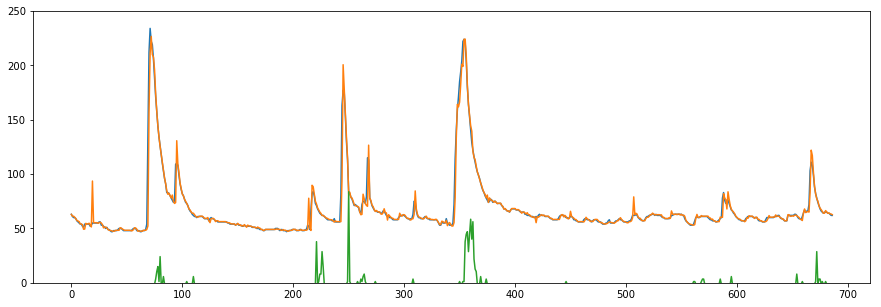
青が実際の水位で、オレンジが予測した水位となっていて、重なりすぎて青の線がほとんど見えない(^-^)
すごい!
予測
ここで、ある時点での水位から降水量を変化させ、1時間後の水位を予測してみます。
import random
# ランダムにインデックスを選定
i = random.randint(0,len(df))
d = df.ix[i].as_matrix().tolist()
print(d)
# テスト用配列を取得
df_test = []
# 降水量を0から20まで変化させてテストデータを作成
for i in range(21):
temp = d[:10]
temp.append(i)
df_test.append(temp)
# 予測
test = model.predict(np.array(df_test).astype("float"))
# グラフ表示
plt.plot(test)
利用されたデータは以下の値でした。
[150.0, 149.0, 149.0, 148.0, 147.0, 147.0, 147.0, 146.0, 146.0, 146.0, 8.0, 147.0]
予測結果のグラフは以下のとおり。
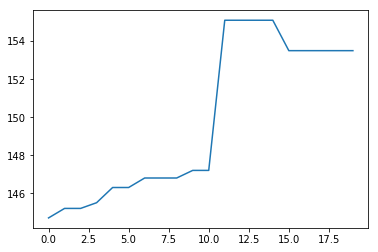
X軸が降水量で、Y軸が水位なのですが、このグラフを見ると、降水量と比例して徐々に水位が上昇するものの、10mm以降で急激に上昇し、13mmで水位が下がっています。
他にもいくつかテストしてみましたが、いずれもちょっと歪なグラフになっていました。
時系列データの予測精度が高くても、これでは役に立ちません...(-_-;)
考察
降水量が増えれば増えるほど水位が上がるのだと思っていたのですが、テストデータによる予測は想定したものと少し異なり、一様に増加するというものではありませんでした。
これはきっと学習データに含まれていないものを正しく予測できていないためかなと考えられます。
よし、これも加味して次の方法を検討しよう!
ニューラルネットワークの利用
では、ここで最近流行りのアルゴリズムを試してみます。
データ加工までは同じで、機械学習の部分を以下のように変更します。
ちなみに、ニューラルネットワークは別名でマルチレイヤーパーセプトロンともいいます。
加えて、ニューラルネットワークでは主に-1〜1までの数値を扱うので、学習データの正規化を行います。
# データを入力と出力に分割
y = df.pop("y").as_matrix().astype("int").flatten()
X = df.as_matrix().astype("float")
# 9割を学習、1割を検証に使用するために分割
num = int(len(X) * 0.9)
print(len(X), num, len(X)-num)
X_train = X[:num]
X_test = X[num:]
y_train = y[:num]
y_test = y[num:]
# データの正規化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
# 学習モデルとしてニューラルネットワークを設定
from sklearn.neural_network import MLPRegressor
model = MLPRegressor(random_state=42)
# 学習と検証
model.fit(X_train, y_train)
result = model.predict(X_test)
# スコア
print(model.score(X_test,y_test))
実行すると、予測精度は「0.947163962045」で、ランダムフォレストより少し悪くなりました(-_-;)
でも、とりあえず最後まで試してみます。
import random
# ランダムにインデックスを選定
i = random.randint(0,len(df))
d = df.ix[i].as_matrix().tolist()
print(d)
df_test = []
# 降水量を0から20まで変化させてテストデータを作成
for i in range(21):
temp = d[:10]
temp.append(i)
df_test.append(temp)
# 入力データの正規化
d = scaler.transform(np.array(df_test).astype("float"))
# 予測
test = model.predict(d)
plt.plot(test)
実行してみます。
[54.0, 54.0, 54.0, 53.0, 53.0, 53.0, 53.0, 53.0, 53.0, 53.0, 0.0, 53.0]
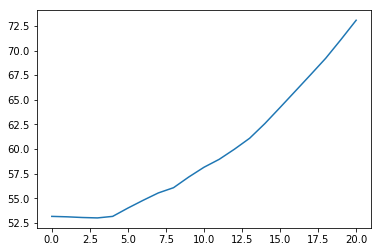
きたーーーーーーーー!!
ニューラルネットワーク、すごい!!
謝辞
鯖江市にてオープンデータに携わっておられる皆様、貴重なデータを本当にありがとうございます。
これからもどうぞよろしくお願いいいたします。
追記
上記の内容を実行したJupyter Notebookのデータをまとめた資料を公開したので、あわせてご参照下さい。