(目次はこちら)
(Tensorflow 2.0版: https://qiita.com/kumonkumon/items/d10a81dd39e74add2a91)
はじめに
前回の記事では、固定していた畳み込み層のウェイトも学習によって推定するようにした。今回は、さらに中間層を増やしてよりディープラーニングらしくしてみる。ただ、これは、ほぼ、TensorFlowのTutorialのDeep MNIST for Expertsなんですが。(追記: Deep MNIST For Expertsは2019年時点ではもうありません)
中間層の追加
前回の記事でのモデルでは、1つだった畳み込み層をプーリング層とセットで、もう一組追加してみる。これは、TensorFlowのTutorialのDeep MNIST for Expertsと同等のもの。
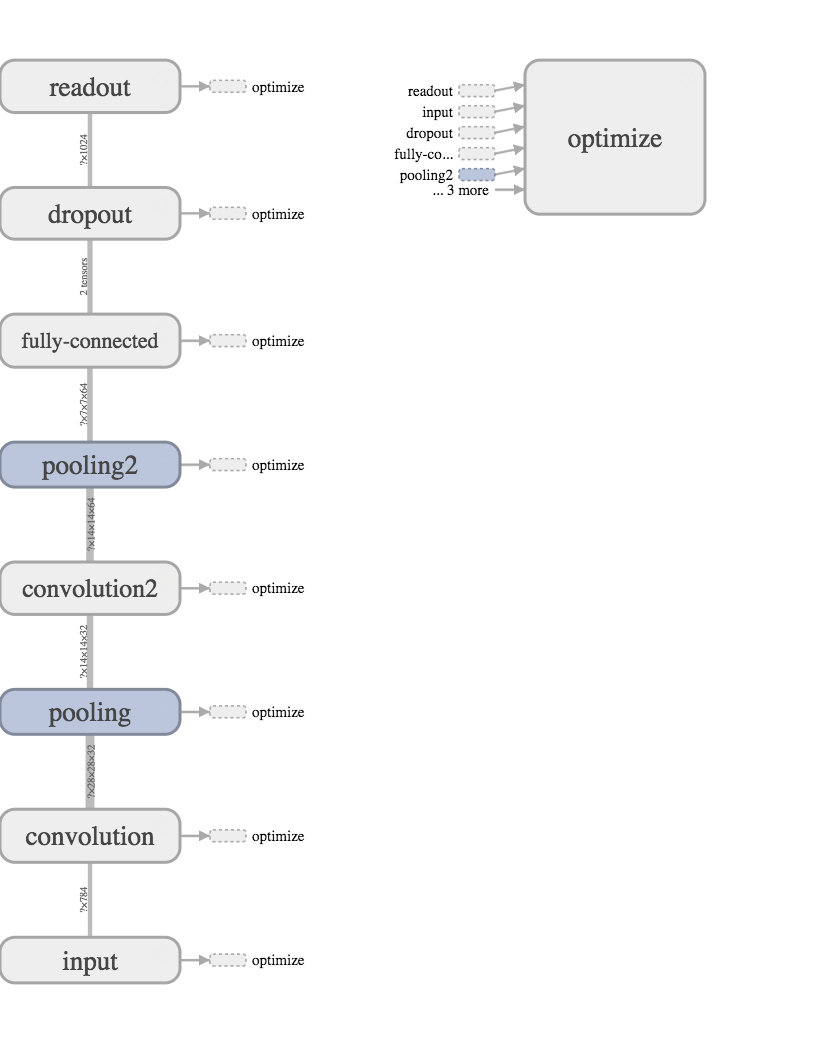
コード
Python: 3.6.8, Tensorflow: 1.13.1で動作確認済み
(もともと2016年前半に書いたものなので、順次更新しています。)
from helper import *
IMAGE_WIDTH, IMAGE_HEIGHT = 28, 28
CATEGORY_NUM = 10
LEARNING_RATE = 0.1
FILTER_SIZE1, FILTER_SIZE2 = 5, 7
FILTER_NUM1, FILTER_NUM2 = 32, 64
FEATURE_DIM = 1024
KEEP_PROB = 0.5
TRAINING_LOOP = 20000
BATCH_SIZE = 100
SUMMARY_DIR = 'log_cnn_ml'
SUMMARY_INTERVAL = 1000
BUFFER_SIZE = 1000
EPS = 1e-10
with tf.Graph().as_default():
(X_train, y_train), (X_test, y_test) = mnist_samples()
ds = tf.data.Dataset.from_tensor_slices((X_train, y_train))
ds = ds.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat(int(TRAINING_LOOP * BATCH_SIZE / X_train.shape[0]) + 1)
next_batch = ds.make_one_shot_iterator().get_next()
with tf.name_scope('input'):
y_ = tf.placeholder(tf.float32, [None, CATEGORY_NUM], name='labels')
x = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT, IMAGE_WIDTH], name='input_images')
with tf.name_scope('convolution'):
W_conv = weight_variable([FILTER_SIZE1, FILTER_SIZE1, 1, FILTER_NUM1], name='weight_conv')
b_conv = bias_variable([FILTER_NUM1], name='bias_conv')
x_image = tf.reshape(x, [-1, IMAGE_WIDTH, IMAGE_HEIGHT, 1])
h_conv = tf.nn.relu(tf.nn.conv2d(x_image, W_conv, strides=[1, 1, 1, 1], padding='SAME') + b_conv)
with tf.name_scope('pooling'):
h_pool = tf.nn.max_pool(h_conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
with tf.name_scope('convolution2'):
W_conv2 = weight_variable([FILTER_SIZE2, FILTER_SIZE2, FILTER_NUM1, FILTER_NUM2], name='weight_conv')
b_conv2 = bias_variable([FILTER_NUM2], name='bias_conv')
h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool, W_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
with tf.name_scope('pooling'):
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
with tf.name_scope('fully-connected'):
W_fc = weight_variable([int(IMAGE_HEIGHT / 4 * IMAGE_WIDTH / 4 * FILTER_NUM2), FEATURE_DIM], name='weight_fc')
b_fc = bias_variable([FEATURE_DIM], name='bias_fc')
h_pool_flat = tf.reshape(h_pool2, [-1, int(IMAGE_HEIGHT / 4 * IMAGE_WIDTH / 4 * FILTER_NUM2)])
h_fc = tf.nn.relu(tf.matmul(h_pool_flat, W_fc) + b_fc)
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
h_drop = tf.nn.dropout(h_fc, keep_prob)
with tf.name_scope('readout'):
W = weight_variable([FEATURE_DIM, CATEGORY_NUM], name='weight')
b = bias_variable([CATEGORY_NUM], name='bias')
y = tf.nn.softmax(tf.matmul(h_drop, W) + b)
with tf.name_scope('optimize'):
y = tf.clip_by_value(y, EPS, 1.0)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), axis=1))
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy)
cross_entropy_summary = tf.summary.scalar('cross entropy', cross_entropy)
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(SUMMARY_DIR + '/train', sess.graph)
test_writer = tf.summary.FileWriter(SUMMARY_DIR + '/test')
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
accuracy_summary = tf.summary.scalar('accuracy', accuracy)
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_LOOP + 1):
images, labels = sess.run(next_batch)
sess.run(train_step, {x: images, y_: labels, keep_prob: KEEP_PROB})
if i % SUMMARY_INTERVAL == 0:
train_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: images, y_: labels, keep_prob: 1.0})
train_writer.add_summary(summary, i)
test_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: X_test, y_: y_test, keep_prob: 1.0})
test_writer.add_summary(summary, i)
print(f'step: {i}, train-acc: {train_acc}, test-acc: {test_acc}')
コードの説明
変更点を。
畳み込み層&プーリング層
畳み込み層とプーリング層をもうひとセット追加
with tf.name_scope('convolution2'):
W_conv2 = weight_variable([FILTER_SIZE2, FILTER_SIZE2, FILTER_NUM1, FILTER_NUM2], name='weight_conv')
b_conv2 = bias_variable([FILTER_NUM2], name='bias_conv')
h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool, W_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
with tf.name_scope('pooling2'):
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
全結合層
2番目のプーリング層の出力が、入力となるように変更
with tf.name_scope('fully-connected'):
W_fc = weight_variable([int(IMAGE_HEIGHT / 4 * IMAGE_WIDTH / 4 * FILTER_NUM2), FEATURE_DIM], name='weight_fc')
b_fc = bias_variable([FEATURE_DIM], name='bias_fc')
h_pool_flat = tf.reshape(h_pool2, [-1, int(IMAGE_HEIGHT / 4 * IMAGE_WIDTH / 4 * FILTER_NUM2)])
h_fc = tf.nn.relu(tf.matmul(h_pool_flat, W_fc) + b_fc)
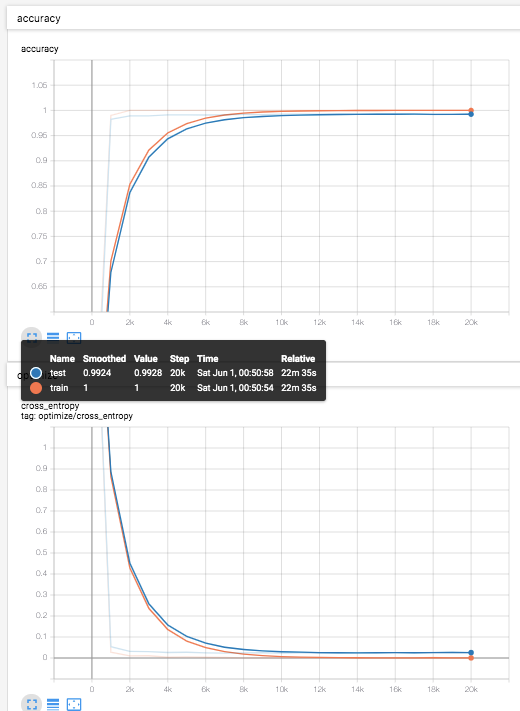
結果
テストデータ(青線)での識別率は、99.2%程度。
Deep MNIST for Expertsでは、99.2%と書いてあるので、しっかりとそれを達成できている。
で、AdamOptimizerにしてみると、
with tf.name_scope('optimize'):
y = tf.clip_by_value(y, EPS, 1.0)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), axis=1))
- train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy)
+ train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
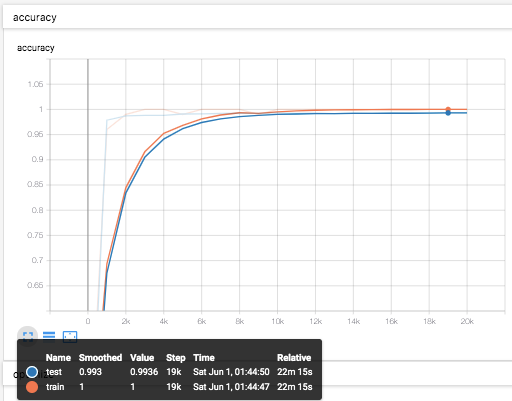
しっかりと、99.3%を超えてきた。
この程度のネットワークでも、CPUマシンじゃいちいち時間かかって辛い。
(Tesla K80 x 1で試したところ、4分程度で終わった。データ周りの実装が悪いのでもっと早くなることは認識している)
あとがき
前回の記事のモデルに、さらに中間層を増やしてよりディープラーニングらしくしてみました。これで、ようやく、TensorFlowのTutorialのDeep MNIST for Expertsに追いつきました。次回の記事では、これまでの内容をまとめます。