(目次はこちら)
(Tensorflow2.0版: https://qiita.com/kumonkumon/items/db63e8e95aa2a1c3d124)
はじめに
前回の記事では、ニューラルネットワークの事始めとしてロジスティック回帰で2クラスの分類問題を扱った。今回は、それを多クラスに拡張してみる。
これは、TensorFlowのTutorialのMNIST For ML Beginnersに相当。(追記: MNIST For ML Beginnersは2019年時点ではもうありません)
多項ロジスティック回帰(multinomial logistic regression)
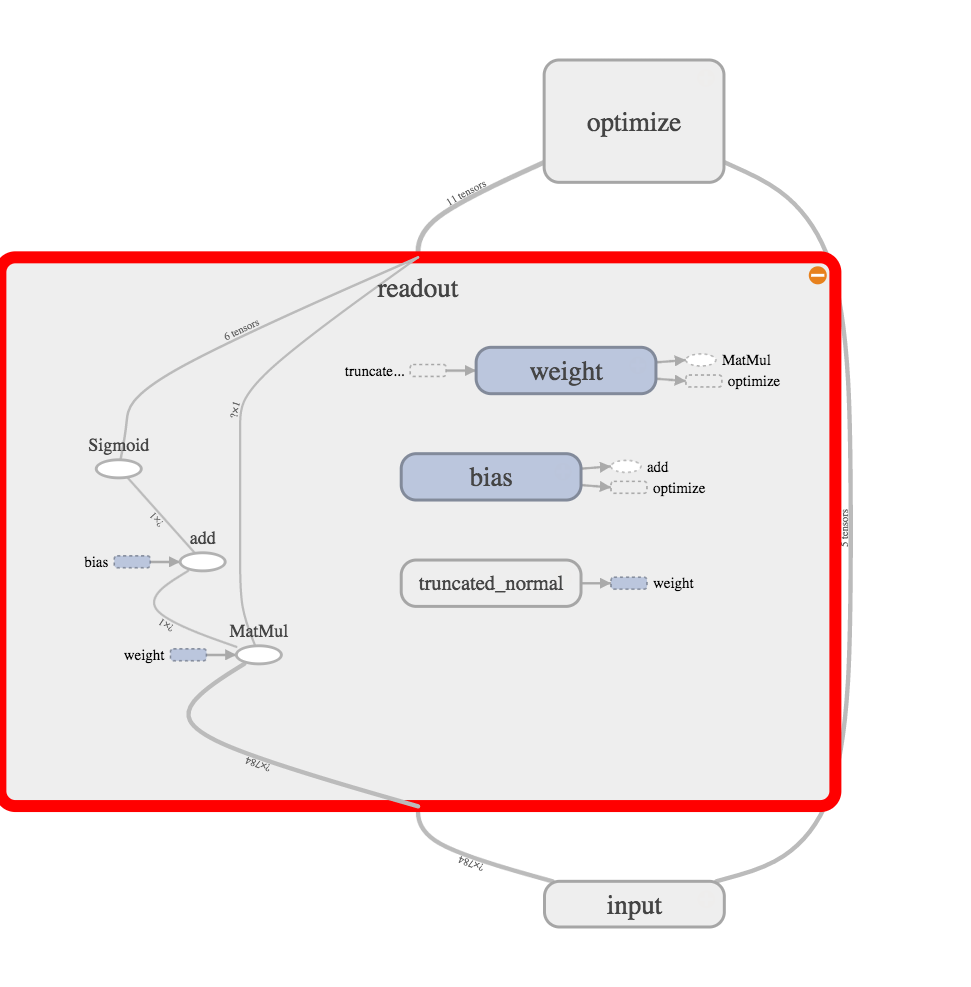
ロジスティック回帰で多クラスを扱う際も、「入力を線形変換して活性化関数をかませて出力を得る」ことに変わりはない。違いは、シグモイド関数がソフトマックス関数に置き換わるだけ。
ロジスティック回帰はこんな感じ。
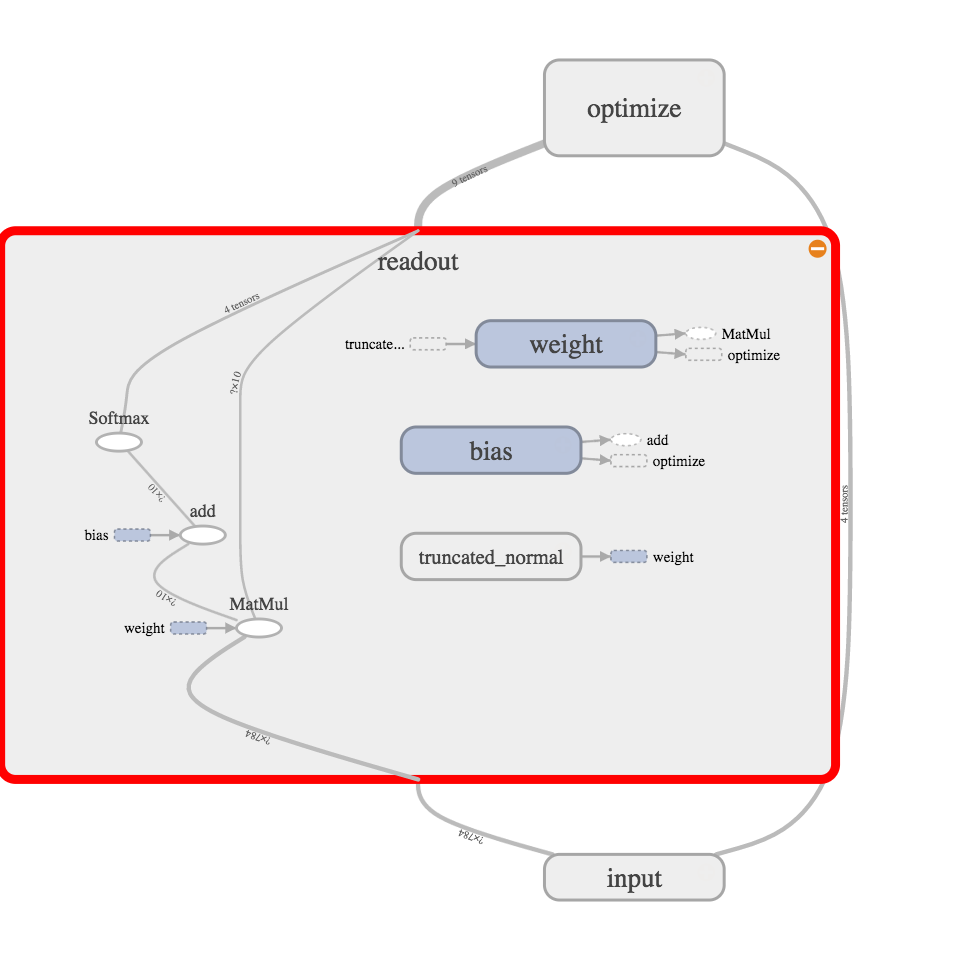
多項ロジスティック回帰はこんな感じで、目を凝らしてみると、SigmoidがSoftmaxに置き換わっていることがわかる。
コード
Python: 3.6.8, Tensorflow: 1.13.1で動作確認済み
(もともと2016年前半に書いたものなので、順次更新しています。)
from helper import *
IMAGE_SIZE = 28 * 28
CATEGORY_NUM = 10
LEARNING_RATE = 0.1
TRAINING_LOOP = 20000
BATCH_SIZE = 100
SUMMARY_DIR = 'log_softmax'
SUMMARY_INTERVAL = 1000
BUFFER_SIZE = 1000
EPS = 1e-10
with tf.Graph().as_default():
(X_train, y_train), (X_test, y_test) = mnist_samples(flatten_image=True)
ds = tf.data.Dataset.from_tensor_slices((X_train, y_train))
ds = ds.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat(int(TRAINING_LOOP * BATCH_SIZE / X_train.shape[0]) + 1)
next_batch = ds.make_one_shot_iterator().get_next()
with tf.name_scope('input'):
y_ = tf.placeholder(tf.float32, [None, CATEGORY_NUM], name='labels')
x = tf.placeholder(tf.float32, [None, IMAGE_SIZE], name='input_images')
with tf.name_scope('readout'):
W = weight_variable([IMAGE_SIZE, CATEGORY_NUM], name='weight')
b = bias_variable([CATEGORY_NUM], name='bias')
y = tf.nn.softmax(tf.matmul(x, W) + b)
with tf.name_scope('optimize'):
y = tf.clip_by_value(y, EPS, 1.0)
cross_entropy = -tf.reduce_mean(tf.reduce_sum(y_ * tf.log(y), axis=1))
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy)
cross_entropy_summary = tf.summary.scalar('cross entropy', cross_entropy)
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(SUMMARY_DIR + '/train', sess.graph)
test_writer = tf.summary.FileWriter(SUMMARY_DIR + '/test')
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
accuracy_summary = tf.summary.scalar('accuracy', accuracy)
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_LOOP + 1):
images, labels = sess.run(next_batch)
sess.run(train_step, {x: images, y_: labels})
if i % SUMMARY_INTERVAL == 0:
train_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: images, y_: labels})
train_writer.add_summary(summary, i)
test_acc, summary = sess.run(
[accuracy, tf.summary.merge([cross_entropy_summary, accuracy_summary])],
{x: X_test, y_: y_test})
test_writer.add_summary(summary, i)
print(f'step: {i}, train-acc: {train_acc}, test-acc: {test_acc}')
コードの説明
2クラスのロジスティック回帰と異なる部分を。
出力層
sigmoid()がsoftmax()に。
with tf.name_scope('readout'):
W = weight_variable([IMAGE_SIZE, CATEGORY_NUM], name='weight')
b = bias_variable([CATEGORY_NUM], name='bias')
y = tf.nn.softmax(tf.matmul(x, W) + b)
最適化
活性化関数がソフトマックス関数になった関係で、パラメータ推定は変わって、対数尤度最大化から交差エントロピー最小化という最適化となる。
with tf.name_scope('optimize'):
y = tf.clip_by_value(y, EPS, 1.0)
cross_entropy = -tf.reduce_mean(tf.reduce_sum(y_ * tf.log(y), axis=1))
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy)
cross_entropy_summary = tf.summary.scalar('cross entropy', cross_entropy)
評価
2クラスの場合は、0.5以上か未満かを見ていたが、直接的にクラスラベルが一致するかを見て、正解かどうかを判断する。
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
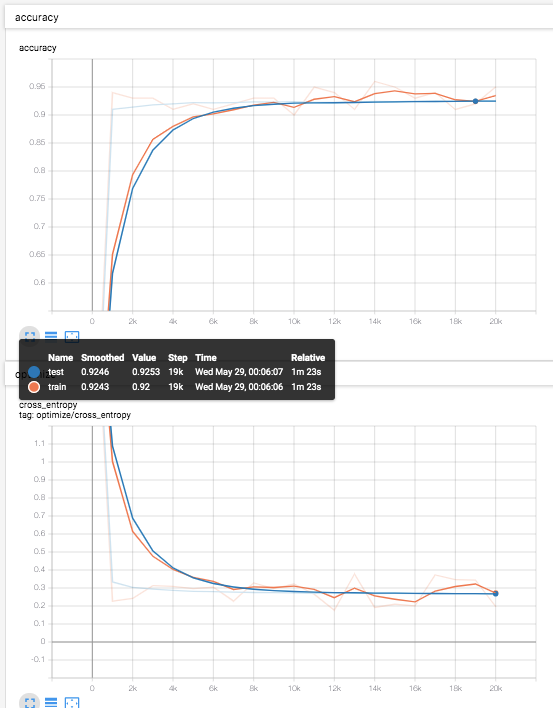
結果
テストデータ(青線)での識別率は、92.4%程度。
あとがき
今回の記事は、TensorFlowのTutorialのMNIST For ML Beginners ほぼそのものだったので、次回の記事 では、このモデルをちょっと拡張してみます。