こんにちは中村公一です。
MATLAB R2013b以来、新しくテーブル型というのがMATLABの基本データ型のひとつとして加わりました。個人的にはこれはLive Editorの登場と同じく非常に大きな変化だと思っています。
テーブルデータとはこんなものです。
ans =
Gender Age Smoker BloodPressure
______ ___ ______ _______________
Male 38 true 124 93
Male 43 false 109 77
Female 38 false 125 83
Female 40 false 117 75
Female 49 false 122 80
これを見られても何とも思わないかもしれませんが、Excelのスプレッドシート的なものをMATLABで実現していると考えればだいたい合っていると思います。
列ごとに変数の型が決まっていて、変数名 VariableNames がついています。この例では含まれていませんが、指定すれば行名 RowNames もつけることができます。
Rやpythonでは...
MATLABのテーブル型は、R言語の データフレーム data.frame とpythonの**pandas**に非常に近いものだと思います。
Rのデータフレーム
> mtcars
mpg cyl disp hp drat wt ...
Mazda RX4 21.0 6 160 110 3.90 2.62 ...
Mazda RX4 Wag 21.0 6 160 110 3.90 2.88 ...
Datsun 710 22.8 4 108 93 3.85 2.32 ...
............
pythonのpandas
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo
見た感じほとんど同じだと思いませんか。
テーブル型登場前夜
テーブル型登場の前は、上の例と同じようなデータを持っていたとして、各列のデータが別々の型なので、セル配列 cell arrayを使うか、非スカラー構造体 non-scalar structureを使うかという選択になります。
あるいは、Statistics Toolboxに含まれるデータセット型というものがR2007aの頃からありました。これは事実上、テーブル型の前身というべきもので、プロパティやメソッドの名前や中身は多少違いますが、基本的な設計はよく似ています。MATLAB本体へのテーブル型の登場によって、事実上存在意義を失っており、現在は次のような警告が出ています。
dataset データ型は将来のリリースで削除される可能性があります。異種混合データを処理するには、代わりに MATLAB® table データ型を使用します。詳細は、MATLAB table ドキュメンテーションを参照してください。
データの準備
load patients
BloodPressure = [Systolic Diastolic];
Gender = categorical(Gender);
whos('Gender','Age','Smoker','BloodPressure')
Name Size Bytes Class Attributes
Age 100x1 800 double
BloodPressure 100x2 1600 double
Gender 100x1 346 categorical
Smoker 100x1 100 logical
tableを用いた場合
ベクトルや配列の行数が一致していることを条件に、table関数で一発でテーブル型へ変換でき、変数名も自動的に継承することができます。
T = table(Gender,Age,Smoker,BloodPressure);
T(1:5,:)
ans =
5×4 table
Gender Age Smoker BloodPressure
______ ___ ______ _____________
Male 38 true 124 93
Male 43 false 109 77
Female 38 false 125 83
Female 40 false 117 75
Female 49 false 122 80
セル配列を用いた場合
セル配列を用いる場合、それぞれの変数をcell型に変換してから、連結することを考えます。
これで一応ほぼ同じことはできますが、このままでは、変数名がないので、データの可読性がテーブル型よりも著しく悪くなります。
C = [cellstr(Gender),...
num2cell(Age),...
num2cell(Smoker),...
num2cell(BloodPressure)];
C(1:5,:)
ans =
5×5 cell array
'Male' [38] [1] [124] [93]
'Male' [43] [0] [109] [77]
'Female' [38] [0] [125] [83]
'Female' [40] [0] [117] [75]
'Female' [49] [0] [122] [80]
それでは、上に一段くっつけて、変数名を格納するのはどうでしょうか?
C_ = [{'Gender','Age','Smoker','BloodPressure1','BloodPressure2'};C];
C_(1:6,:)
ans =
6×5 cell array
'Gender' 'Age' 'Smoker' 'BloodPressure1' 'BloodPressure2'
'Male' [ 38] [ 1] [ 124] [ 93]
'Male' [ 43] [ 0] [ 109] [ 77]
'Female' [ 38] [ 0] [ 125] [ 83]
'Female' [ 40] [ 0] [ 117] [ 75]
'Female' [ 49] [ 0] [ 122] [ 80]
これで見た目はよくなりましたが、別の問題を生じました。
データの一行目が、cell配列の二行目になってしまいます。すべてのindexに1を足せばよいわけですが、これはこれでいかにも人為ミスを誘発しそうです。
また、このcell配列のAge変数にアクセスしようとしても、C_.Ageというような便利な記法が使えません。
C_(2:end,2)とするしかないのですが、これも不便ですね。age = 2とすることでC_(2:end,age)という書き方にはできますが、これがせいぜいです。
これがテーブル型の場合は、T.Ageだけで用が済んでしまいます。
さらに、C_(2:end,2)としてAgeのデータを取り出す場合、このままではcell型のままなので、数値データに変換するため、cell2mat(C_(2:end,2))としなければいけません。
あるいは、これC_{2:end,2}はどうでしょうか?これならばセルの中の数値データが取り出せますね?しかしこれでは、下の構造体のところでも出てくるコンマ区切りリストの形になってしまい、一個一個の数値がバラバラの変数になってしまうので、それを連結してベクトル化し直す必要があります。ですので、[C_{2:end,2}]'あるいはvertcat(C_{2:end,2})とこのような形にしなければなりません。
しかしテーブル型の場合は、T.Ageとするだけで、double型の数値データとして取り出せます。断然テーブル型の方に軍配が上がると思いませんか?
テーブル型自作の試み
実は2012年にMATLABを始めて一ヶ月後に取り組んだのが、当時まだ存在しなかったテーブル型の同等物を作ろうという試みでした。当時考えたのは、cell型データの可読性があまりにも悪いので、Excelワークシートの類似物を作ろう、ということでした。MATLABのオブジェクト志向プログラミングを使って、実際にはcell型にデータを格納しながらも、最上段に変数名を格納して、その他の利便性を実現しようとしたのです。一応、それなりのclassdefを書いて、動くようにはなりましたが、やはりcell型に由来する問題の幾つかはこの方法ではごまかしようがなく、不便さが残り、いびつなものでした。不安定なので結局自分のデータの保存には使うのを止めて、しばらくするとMATLABに公式にテーブル型が登場し、設計思想が非常によく似ていたのでびっくりしたものです。おいおい、君らが作っているなら教えてくれよ、と思いました。
非スカラー構造体を用いた場合
非スカラー構造体 non-scalar structure というのは、構造体を配列にしたものです。これは変数名をフィールド名という形で表現できますし、データの収納に関してはテーブル型にかなり近いことが実現できます。
ただし、下のコードを見て頂くと、これを準備するのがやや面倒なことがお分かりいただけるでしょう。
n = length(Gender);
S = struct('Gender',cell(n,1),...
'Age',zeros(n,1),...
'Smoker',false(n,1),...
'BloodPressure',zeros(n,1));
for i = 1:n
S(i).Gender = Gender(i);
S(i).Age = Age(i);
S(i).Smoker = Smoker(i);
S(i).BloodPressure = BloodPressure(i,:);
end
S(1:5)
最初に S = struct()という箇所でやっているのは、preallocationです。ループに入る前にメモリースペースを確保するためのものです。そして、forループで、S(この場合は列ベクトル)のそれぞれの要素に対して、1つずつ変数を代入しています。
しかしこれの悲しいところは、データの可読性の悪さです。コマンドウィンドウではこのようにしか見えません。
ans =
5×1 struct array with fields:
Gender
Age
Smoker
BloodPressure
変数エディタではちゃんと展開して表示されますが、これも数年前までは無理でした。
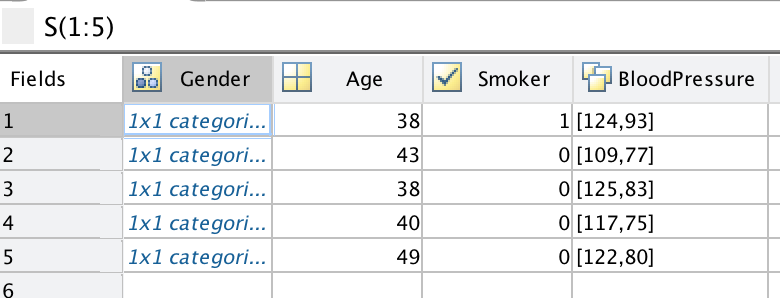
では次に、AgeのデータをSから取り出すにはどうしたらよいでしょうか。シンプルなS.Ageは思うような結果を出してくれません。
S.Age
ans =
38
ans =
43
ans =
38
ans =
40
...
これはどういうことかというと、上のセル配列のところでも少し触れましたが、出力がコンマ区切りリスト comma-separated listという形になっていて、38, 43, 38, 40,... というのと同じなのです。バラバラの変数になってしまっているので、これらをもう一度連結してベクトルにする必要があります。したがって正解は
[S.Age]'
または
vertcat(S.Age)
のようになります。それほど悪くはありませんが、T.Ageのわかり易さには劣るのではないでしょうか。
データ解析のカノニカル・パイプライン
Live Scriptを使用。探索目的のスクリプトの命名法は、scr20170725_112030_hogehoge.mlxという形式。発表用のスクリプトは、区別できるようにmain1_hogehoge.mlx(Figure 1に対応)という形式。
-
環境設定
- フォルダパス設定、パラメータなど
-
ファイルの同期・更新
- Excelワークシートからのデータ抽出とマージ
- 生理学データの持つ不規則性が障害となる
- 2つのファイルをマージして1つのファイルを出力するときの7つのシナリオ
-
データの解析計算
- 時間のかかる計算処理は結果を保存して次から読み込む
-
parforを使った高速化 waitbarはできるだけ使わない- 特定のデータにアクセスするための仕掛け
-
統計検定
- table型のデータを徹底活用
- グループ化変数 grouping variables(MATLABドキュメンテーション) を最大限利用
- 図の作成
まとめ
ここまで来て、もう一度、上のtableを使った例と、セル配列、構造体配列(非スカラー構造体)の例とを比べてみて下さい。どの方法が一番便利そうでしょうか?ほとんどの方がテーブル型を好まれるのではないでしょうか。