Apache Apex について調査していたので、まとめます。
Apache Apex とは
ストリーム処理基盤 Apache Apex で Hello World - Qiita でも言及していますが、 Apex はストリーム処理とバッチ処理を統合する Hadoop YARN ネイティブの基盤で、以下のような特徴を持ちます。
- 高いスケーラビリティとパフォーマンス
- フォールトトレランスと状態管理
- Hadoop YARN & HDFS
- シンプルな API
オペレーター と呼ばれる処理単位を作って DAG (有向非巡回グラフ) を組んでストリーム処理アプリケーションを作成することができます。各 オペレーター は状態を持つことができ、データフローやコネクティビティ、フォールトトレランスは Apex 側が面倒みてくれるので、開発者は各 オペレーター が入力タプルをどう扱うか、そして出力をいつ(そしてどのポートに)送るかだけを実装すればいいようになっています。
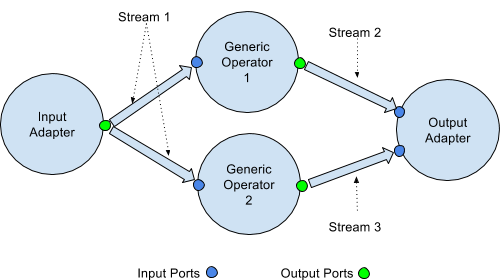
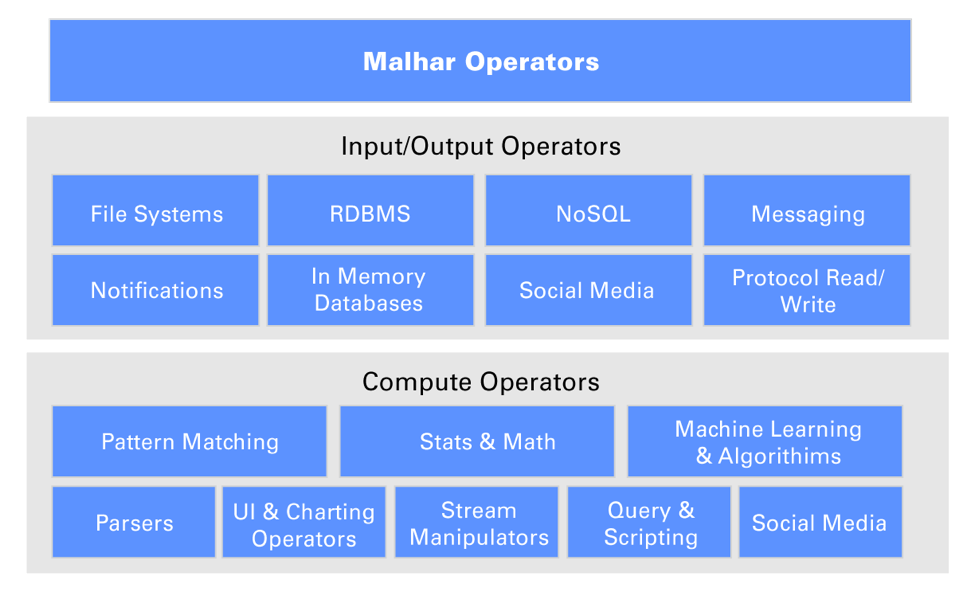
Apex Malhar
Apex には Malhar というオペレーターを実装するためのライブラリがあり、入出力や集計などの処理を簡単に書けるようになっています。 Apex は自身の特徴としてコードの書きやすさや再利用性の高さを謳っており、 Malhar がその役割を担っています。
パーティショニング
Apex では、オペレーターごとにパーティションの設定を行い、オペレーターの並行処理性能を上げることができます。さらに、パーティション数の変更は、アプリケーションの実行中に行うことができます。
ドキュメント
- Apache Apex Documentation
- Apache Apex Malhar Documentation
- Apache Apex Documentation
- DataTorrent Documentation (Distribution 3.8.0 API)
参考: Apache Apexとは何なのか? - Qiita
ユースケースと評判
GE が Predix Platform という製造業向けの IoT プラットフォームに Apex を採用しています。採用の理由として、
- 高いパフォーマンス
- 動的なパーティショニング
- 豊富なオペレーター用ライブラリ
- atleast-once, atmost-once, exactly-once のサポート
- デプロイと運用のしやすさ
などをあげています(スライド p19)。
その他のユースケースについては Powered by Apache Apex にまとめられています。
はじめかた
以下を順に見ていくといいと思います。
- ストリーム処理基盤 Apache Apex で Hello World - 駄文型
- ストリーム処理で文章内にある単語の出現頻度をカウントする(Apache Apex) - 駄文型
- ストリーム処理で文章内にある単語の出現頻度をカウントする(Apache Apex) その2 -コーディング編- - 駄文型
コードの書きやすさ
アプリケーションを実装する場合は、オペレーターの抽象的な(論理的な?)処理のみに集中できるので、コードは書きやすい印象です。各オペレーターをどのように組んで DAG を組むかは、ある程度経験が必要になってきそうです。詳細は [ストリーム処理で文章内にある単語の出現頻度をカウントする(Apache Apex) その2 -コーディング編- - 駄文型] に書いています。
Storm に似ているらしいです。
- コードの組み方はStormに非常に似ている。
書きやすさと再利用性は Apex の「オペレーターでダグを組んでストリーム処理アプリケーションを構築する」という特徴から来ていると考えています。(ちゃんと設計すれば)各オペレーターは非常にシンプルな機能を持つ単一責務の処理単位になるので、再利用性の高いモジュールができあがります。
さまざまな Apex アプリケーションを作って多くのオペレーター実装していけば、オペレーターを再利用してダグの形を変えるだけで別のアプリケーションができあがる、というのが Apex の理想だと思います。
一方で、ダグの設計が難しそうです。一度ダグが決まってしまえば、あとは簡単です。このあたりは一般論なので、実務レベルでどうなのかまでは実際にアプリをどんどん書いていかないと課題などは見えてこないかと思います。
他のストリーム処理エンジンとの比較
他のストリーム処理エンジンを知らないので、評価はできません。資料を載せておきます。
Kafka との接続
実際に試してはいませんが、 Malhar に Kafka のクラスが用意されており、簡単に接続可能なようです。
Kafka Input - Apache Apex Malhar Documentation
まとめ
- Hadoop YARN & HDFS
- 豊富なライブラリ
- コードは書きやすい印象
- Kafka とも接続しやすい
- パフォーマンスはめっちゃいいぞって DataTorrent が言ってる
- 実行中にパーティショニング