こんにちは。
最近広まってきているストリーム処理プロダクトのうちの一つとして、
Apache Apexがどんなものか、をプレゼン資料からポイントを拾ったので、まとめてみます。
ただ、その前になぜこんなことをやってみたか、という経緯を・・・
最近のストリーム処理プロダクト概況
元々昔からストリーム処理プロダクトが好きで見ていたため、常時ゆるゆる情報は追っています。
ただ、ここ最近の状況を一言でいうと、
正直な話、いっぱい出すぎてよーわからん。
に尽きると思います。
とりあえず私の(狭い)観測範囲の中だけ見てみても、これだけプロダクトが出てきてしまっています。
公開時期はアバウトなものですので、こんな感じでたくさん出ているというイメージだけ持っていただけると。
あとKafka Streamsはアイコンないのでconfluentのアイコンです。わかる方がいればこちらも。
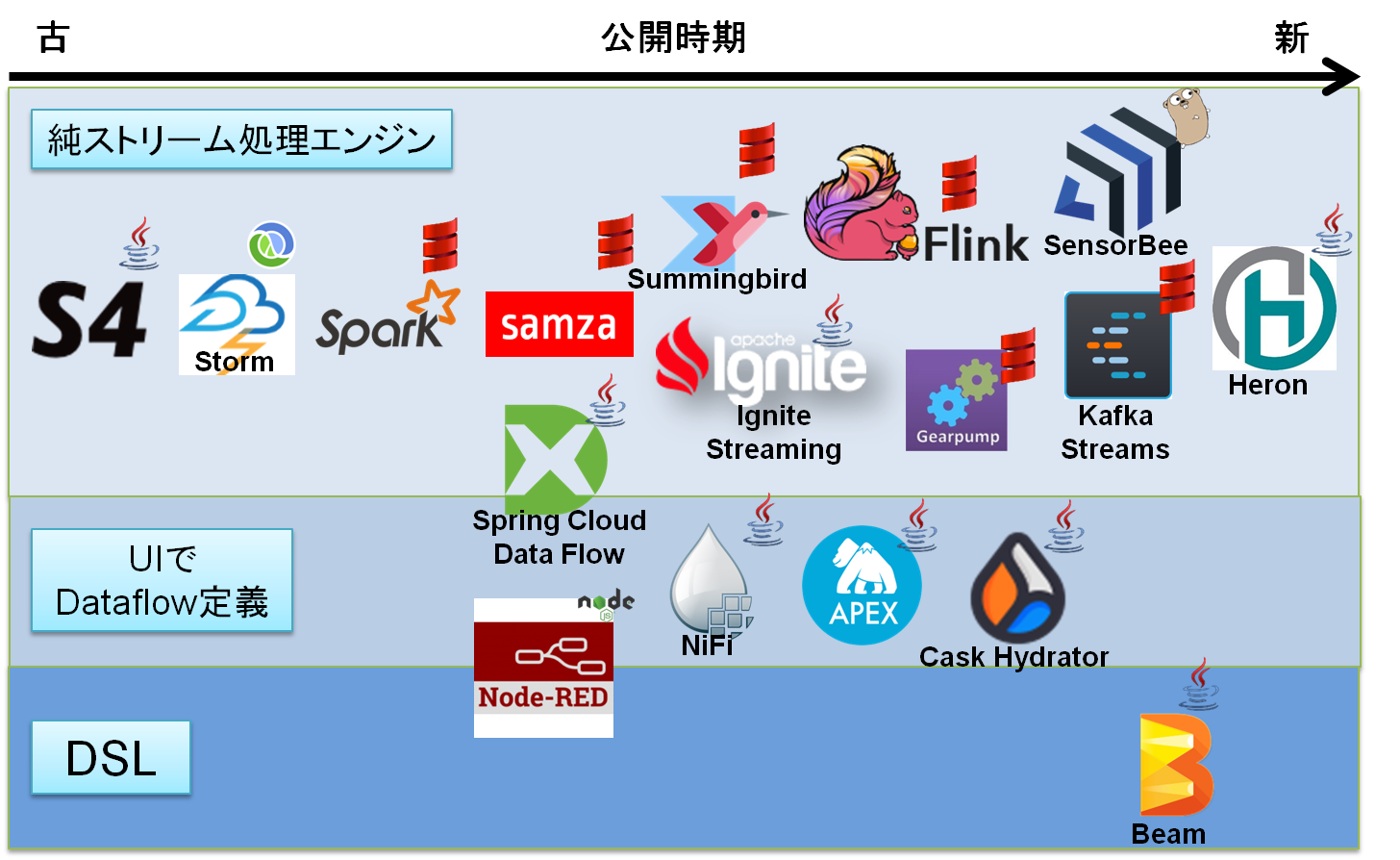
で、上記の中で個人的に気になっているのは分散クラスタ上で分散したJVM上で動作する下記のプロダクトです。
- Apache Flink(data Artisans)
- Apache Apex(DataTorrent)
- Apache Gearpump(Intel/Lightbend)
- Heron(Twitter)
Apacheのプロダクトばかりですが、何でもかんでもApache化してしまうのはどうなんだろう、
とも思う今日この頃です。実際どうなんでしょうね?
と、それはさておき、上記のうち、Flinkについては使ってみた方や使おうとしている方がいて、相応に情報があります。
GearpumpとHeronは自分でそれなりに調べたことがあり、概要としては多少わかっている状態です。
とりあえず参照先は以下にまとめておきます。
Apache Flink
- Apache Flinkを試している
- Apache Flinkを試してみての感想
- Apache Flink とは
- Apache Flinkをインストール
Apache Gearpump
- リアルタイム処理エンジンGearpumpって?
- リアルタイム処理基盤Gearpumpの概要構成はどうなっているの?
- Gearpumpのローカル環境の起動方法&デプロイ方法
Heron
- Twitter HeronはStormに比べてどう進化しているのか?
- Twitter Heronの論文でのStormの問題とHeronの利点は?(サマリ
- Twitter Heronの論文でのStormの問題点は?(詳細
- Twitterの新ストリーム処理基盤、Heronのアーキテクチャは?(詳細
ただ、Apexについては実情や概要がほとんど分かっていない状態です。
そのため、まずはいくつかの資料を見て概要を押さえておこう、というのが経緯になります。
Apache Apexの資料は?
少し検索してみると、やたらと一杯資料が引っかかりました(汗
ただ、かぶっている内容も多いため、コンパクトにそれなりに網羅出来る資料を見繕ってみると
下記のようになりました。
- Apache Apex Fault Tolerance and Processing Semantics
- Apache Apex as a YARN Apllication
- Apache Apex Introduction with PubMatic
とはいえ、この先の資料も相応に重複しているため、特徴を抽出してみます。
資料から特徴を抽出した結果
抽出してみた結果、下記のような構成、特徴を持っている・・ということがわかりました。
- OperatorでDAGを組んで、アプリケーションを構築
- Operatorは基本はメッセージのウィンドウを常時管理して処理を行う。
- ウィンドウの最後にメッセージを送るということも可能
- コードの組み方はStormに非常に似ている。
- YARNを用い、HDFSに状態を保持するためHadoopクラスタ上で運用しやすい。
- そのため、デフォルトの状態保持機構が充実
- アプリケーションマスタもHDFSに状態保存
- 手法としてはシリアライズしたOperatorを保存するもの。
- メッセージの処理結果をバッファリングし、下流側が取得しに来るモデル
- そのため、BackPressureの機構を明示的に盛り込む必要はない。
- ただ、つまりはPullモデルになるため、速度的には疑問符あり。
- 局所性設定をラック単位、ノード単位、コンテナ単位、スレッド単位で設定可能
- アプリケーション起動中にコンポーネントの更新や追加が可能
- アプリケーション起動中に並列度の更新が可能で、オートスケール機構を有する
- UIからPipeline builderでストリーム処理が記述可能
- 管理UIに論理ビュー、物理ビュー、クラスタダッシュボードを有する
あとは、高速にOperatorの状態をHDFS上に保存するために、
HDHT (Hadoop Distributed Hash Table)という機構を持っているようです。
- Data Store for Scalable Stream Processing
ただ、見た感じ、書き込みをクライアントサイドでバッファリングしておいて、
非同期でHDFSにflushするというもののように見えます。
HBase等に比べて簡易にレスポンスが素早い保存レイヤを構築可能なのはいいのですが、
同期的な保存にはならないため、信頼性には疑問が残るという形になりますね。
ただ、ストリーム処理上で毎回の状態保存をHDFSに対する同期的な書き込みで行うのは論外なので、
対処としてはわかるといえばわかるのですが。
ですので、高速に信頼性も求める場合はやはりHDHTではなく
HBaseや分散キャッシュ系プロダクトを用いて対応する必要がありそうです。
あくまでHDHTは簡易キャッシュとしてHDFS上に状態を保存することが可能なものというくらいの
位置づけで見た方がいいように思えます。
このあたりもしわかる方がいれば補足いただけると・・・
まとめ
上記のように、Apexの構成、特徴についてざっと概要を見てみました。
一言で端的に言うと、
「YARNやHDFSに強く適応した、状態保存をお手軽に組めて稼働中に構成更新可能なストリーム処理エンジン」
というような形になるのではないでしょうか。
Flinkは稼働中に構成更新はできませんし、
Gearpumpは状態保存部分のお手軽さに欠けるため、
この2つに比べると機能が充実し、
使い込み具合や事例からしても現状成熟しているように見えるプロダクトともいえると思います。
この後、GearpumpやHeronと並行して、とはなりますが、
色々ドキュメントを読み込んだり、実際に動かしてみて試してみようとは思います。
それでは。