前回の問題点は、サンプルデータが、文字の「出現頻度」を操作した群だった事でした。
当然、文字の頻度が変われば遷移確率も変化するのですが、じゃぁ素直に文字の頻度だけでクラスタ化できるじゃないか、という事です。
という事で、「出現頻度」を変えずに「遷移確率」を変えたデータでやってみる。
1. サンプルデータの工夫
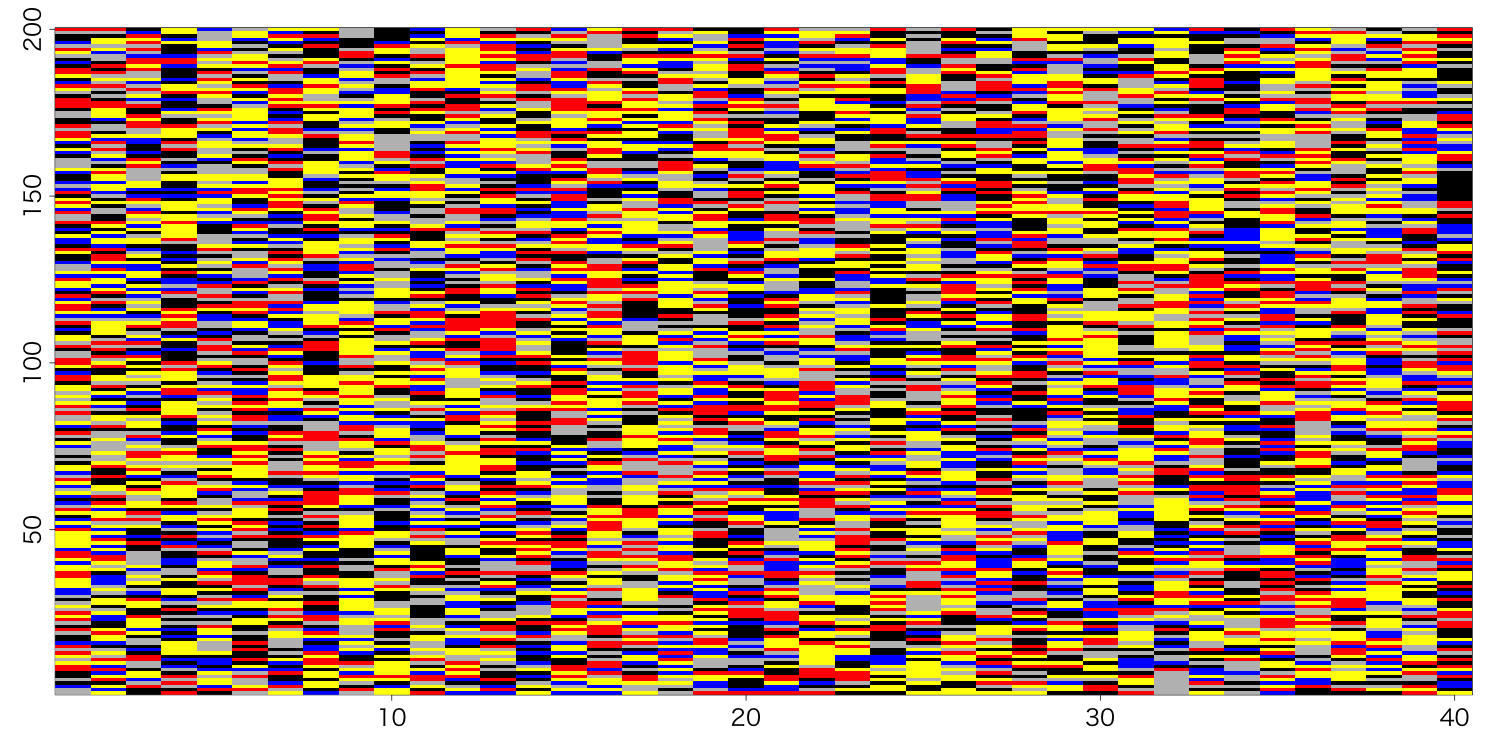
前回と同じ様式で図示してあります。
ミソは、パッと見では前半20データと後半20データを見分けられないと思います。
作り方のレシピ。
set.seed(1)
N <- 200
datA <- NULL
datB <- NULL
for(i in 1:20){
dat <- sample(c(1:5), N, replace = T)
dat1 <- dat
for(k in 1:2){
a <- c(1:length(dat))[dat == 1] +1
dat1[sample(a, length(a)*0.3)] <- sample(c(1,2,4), 1)
}
for(k in 1:2){
a <- c(1:length(dat))[dat == 3] +1
dat1[sample(a, length(a)*0.5)] <- sample(c(1,5), 1)
}
dat1 <- dat1[1:N]
dat2 <- sample(dat1, length(dat1))
datA <- cbind(datA, dat1)
datB <- cbind(datB, dat2)
}
dat <- cbind(datA, datB)
発想は、「遷移確率を偏らせた文字列dat1」を用意しておいて、「それをランダムに並び替えた文字列dat2」を作る。このペアを20セット作ってる、という理屈です。
dat1の偏らせ方は、例えば「1」の次に来る文字の30%を、「1, 2, 4」のどれかに置き換える、としています。これを2回繰り返しかけて、あと、「3」次を50%で「1,5」のどちらかに置き換える事を2回しています。
ペアになっているdat1とdat2は、「文字の出現頻度」は完全に一致しているので、それに基づいたクラスタ解析をすると、やはりペアになる。
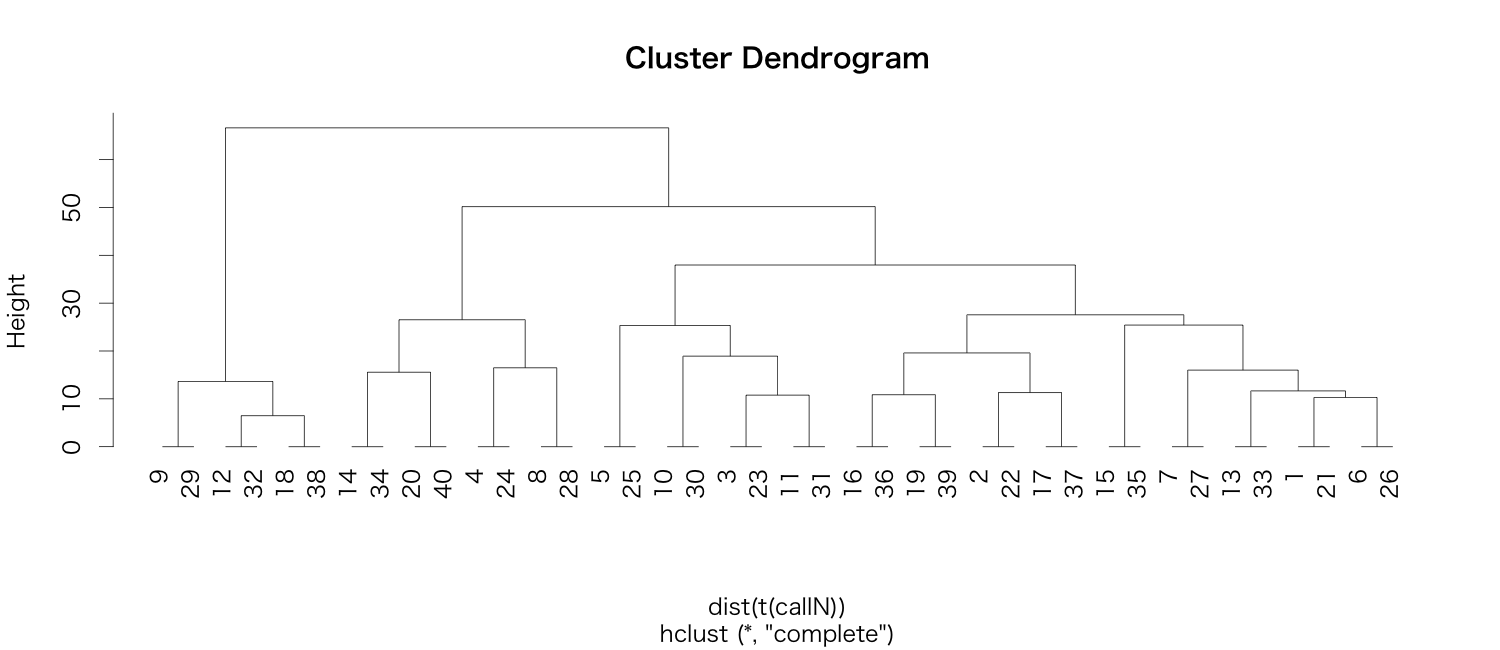
+20番のものと完全に文字頻度が一致しているのが見て取れる。
i <- 1
callN <- NULL
for(i in 1:ncol(dat)){
dati <- factor(dat[,i], levels=type)
callN <- cbind(callN, c(table(dati)))
}
clust_callN <- hclust(dist(t(callN)))
2. 遷移確率マトリックス
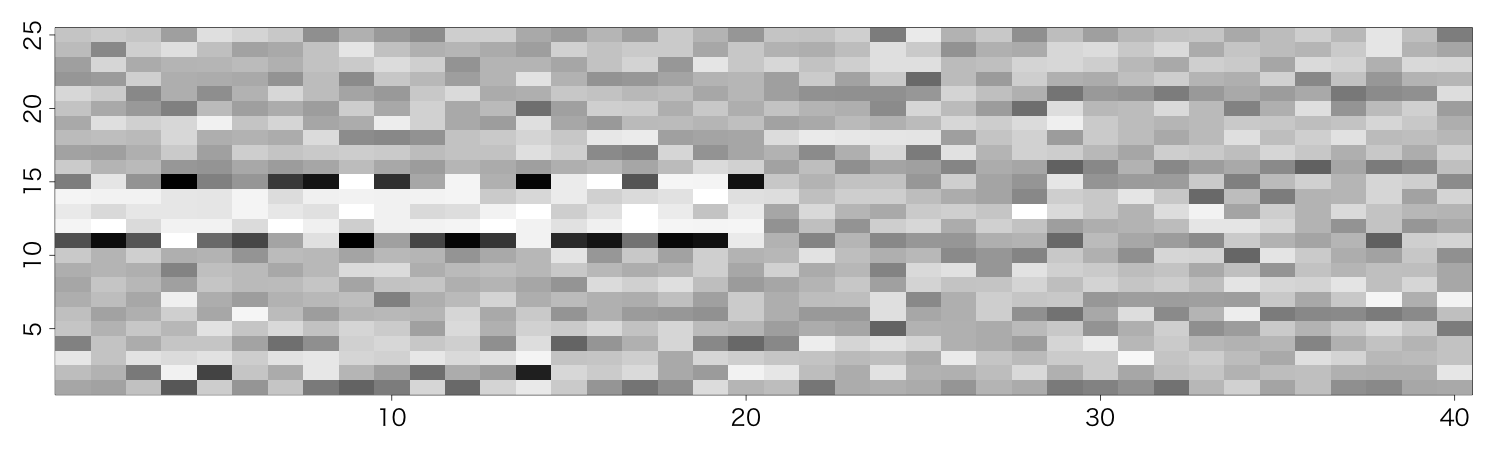
これも前回と同じ様式で図示してあります。
今度は、一見して、前半・後半の違いが分かりますね。
3. JS divergence
何それ?という方は、こちらの記事。

いい感じですね。
4. clustering
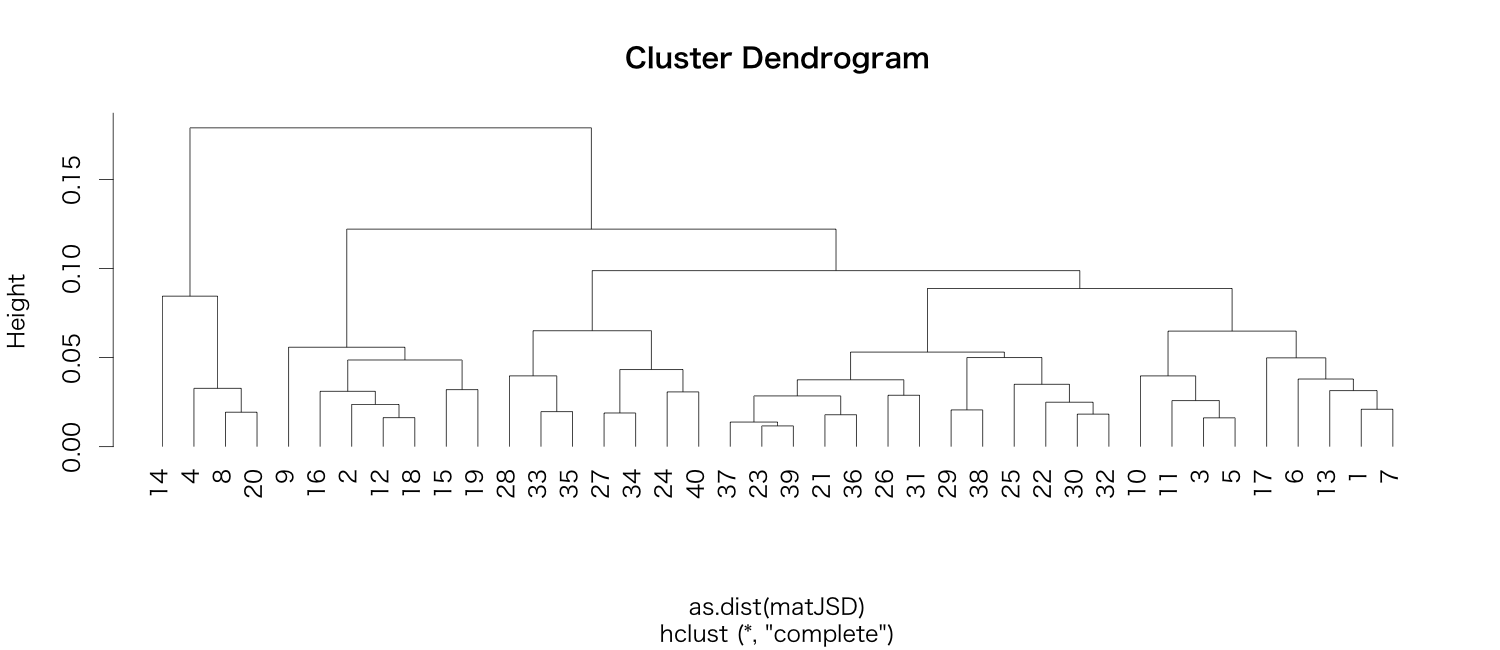
という事でメデタシ。