私の大好きな宇宙海賊ゴー☆ジャスが,先日嬉しいことに私の大学の学園祭にて公演をしてくださいました。その記念に, ゴー☆ジャスを作ってみました。Pythonでゴー☆ジャスクラスを実装しましたので,時間の無い方は一番下のクラス実装かテストの部分まで読み飛ばして下さい。
2021-12-07 いくつかの派生記事がでています
2019/7/16 (なんと本物にツイートしていただきました)
ゴー☆ジャスの頭の中ではこんなことが((((;゚Д゚)))))))!!!!
— ゴー☆ジャス(宇宙海賊) (@Gorgeous55555) 2019年7月16日
ゴー☆ジャス(宇宙海賊)をつくる https://t.co/wcwo6bqt0E #Qiita
サンプルWebアプリにもなっています
宇宙海賊ゴー☆ジャスについて
 ※画像はWikipediaより引用
※画像はWikipediaより引用
ゴー☆ジャスはアンドロメダ三丁目出身のお笑い芸人宇宙海賊で,地球では地球儀を用いた国名や地名のダジャレ芸による一人ショートコントを行います。例としては以下のような感じ。
まだ助かる! → マダガスカル!
売るくらいなら… → ウクライナ!
腹の具合が… → パラグアイ!
このボタンを…押すとラリアット… → オーストラリア!
パパは牛乳屋… → パプアニューギニア!
そしてその後,
そぉ〜れ!…(地球儀から探す)… ここ!マダガスカル!(該当場所を指し示す)
といった具合です。これが絶妙に面白いのです。
見て下さい。(Youtube, Twitter)
結果
こんな物が出来ます。
ネタへのアプローチ
ダジャレなので,基本的にはフレーズの読みの類似度の高い国名を探せれば良さそうです。
ざっと考えられるやり方だと,
- 文章入力
- ひらがな・ローマ字化・母音抽出
- 国名との類似度計算
- 高類似度国のGoogle Mapなどで出力
これをPython3で実装して行きます。
ひらがな・ローマ字化・母音抽出
まず入力文章の読みを判定するために,MeCabを用います。Pythonラッパのmecab-python3(PyPi)そして,発音を表すローマ字列の判定のための漢字→ローマ字変換プログラム: kakasiのラッパーpykakasi(GitHub)を用います。
import MeCab
from pykakasi import kakasi
# instantiate
kakasi = kakasi()
kakasi.setMode('K', 'a') # Katakana to ascii
conv = kakasi.getConverter()
- カタカナ化:
katakanize()
import re
def katakanize(s: str, morph=False, **kwargs) -> str:
morphed = [re.split("[,\t\s\n]", w) for w in MeCab.Tagger().parse(s).split("\n")]
morphed.remove([""])
morphed.remove(["EOS"])
k = [morph[-1] if morph[-1] != "*" else morph[0] for morph in morphed]
if morph: # morphlogical analysed output
return k
return "".join(k)
一応後のために,morphオプションをつけておきます (入力文章の分かち書きをするか否か)
- ローマ字化:
romanize()
def romanize(s, **kwargs) -> list:
s = katakanize(s, **kwargs)
if type(s) == str:
s = [s]
return [conv.do(w) for w in s]
- 母音(とンの)抽出:
extract_vowel()
def extract_vowel(word: str, **kwargs) -> str:
if type(word) == list:
return [extract_vowel(w) for w in word]
return "".join([l for l in word if l in ["a", "i", "u", "e", "o", "n"]])
MeCabで文章の読みの判定(カタカナ化)を行い, kakasiでカタカナのローマ字化を行います。
以上で, 以下のような変換が可能です。
>>> romanize("慶應義塾大学湘南藤沢キャンパス")
['keio-gijukudaigakusho-nanfujisawakiyanpasu']
>>> romanize("慶應義塾大学湘南藤沢キャンパス", morph=True)
['keio-gijuku', 'daigaku', 'sho-nan', 'fujisawa', 'kiyanpasu']
>>> extract_vowel(romanize("慶應義塾大学湘南藤沢キャンパス"))
['eioiuuaiauonanuiaaianau']
国名との類似度計算
まず国名のデータですが,Wikipediaからのクローリングを断念し,以下のページからいただきました。
Qiita: 国コード一覧CSV ISO 3166-1
import requests
from bs4 import BeautifulSoup
res = requests.get("https://qiita.com/tao_s/items/32b90a2751bfbdd585ea")
if res.ok:
data = BeautifulSoup(res.content, "lxml")
with open("nations.csv", "w") as f:
f.write(data.find("div", class_="code-frame").text.strip())
nations.csv
$ cat nations.csv
"国・地域名","ISO 3166-1に於ける英語名","数","三字","二字","場所","各行政区分"
"アイスランド","Iceland","352","ISL","IS","北ヨーロッパ","ISO 3166-2:IS"
"アイルランド","Ireland","372","IRL","IE","西ヨーロッパ","ISO 3166-2:IE"
"アゼルバイジャン","Azerbaijan","031","AZE","AZ","東ヨーロッパ","ISO 3166-2:AZ"
"アフガニスタン","Afghanistan","004","AFG","AF","中東","ISO 3166-2:AF"
"アメリカ合衆国","United States","840","USA","US","北アメリカ","ISO 3166-2:US"
"アメリカ領ヴァージン諸島","Virgin Islands, U.S.","850","VIR","VI","中央アメリカ","ISO 3166-2:VI"
...
以下のようにして,csvを読み込みます。
import re
with open("nations.csv", "r") as f:
nations = f.read().split("\n")
nations = [re.split("[,|]", nation)[0].replace("\"", "") for nation in nations]
nations.pop(0) # ヘッダ部分を削除
次に, 類似度算出です。文字列同士の類似度の算出のために, レーベンシュタイン距離を用います。Pythonでは,python-Levenshtein (PyPi)というパッケージを用いれば,超簡単に算出できます。
from Levenshtein import distance as D
def revolution(word: str, n_result=5, **kwargs) -> str:
word_roman = romanize(word, **kwargs)
dists = [D(word_roman[-1], nation[0]) for nation in nations_roman]
idx = sorted(range(len(dists)), key=lambda k: dists[k])
# logging
print("RESULT:")
for i in range(n_result):
print(f"\tNo.{i+1} : {nations[idx[i]]} ({nations_roman[idx[i]][-1]}) : ({dists[idx[i]]})")
return nations[idx[0]]
これにより, 類似した国名の出力ができるようになりました。
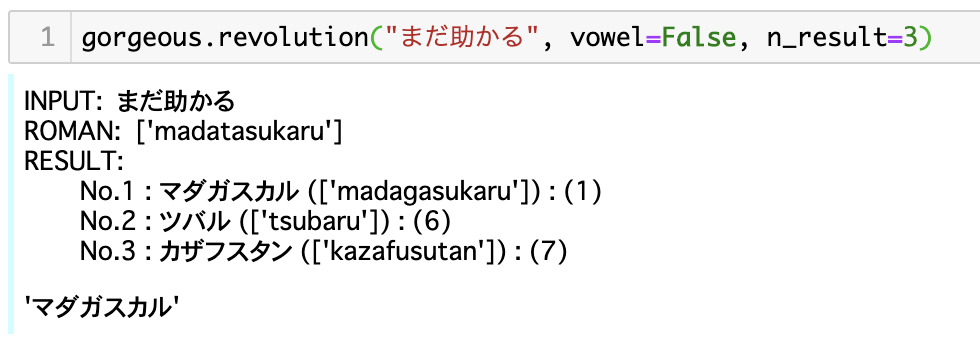
>>> revolution("まだ助かる")
INPUT: まだ助かる
ROMAN: ['madatasukaru']
RESULT:
No.1 : マダガスカル (['madagasukaru']) : (1)
No.2 : ツバル (['tsubaru']) : (6)
No.3 : カザフスタン (['kazafusutan']) : (7)
No.4 : カタール (['kata-ru']) : (7)
No.5 : ジブラルタル (['jiburarutaru']) : (7)
'マダガスカル'
動いていそうですね!!
君のハートに、レボ☆リューション! gorgeous.revolution()
ここまで実装したことは,全てゴー☆ジャス本人が脳内で行っているものですので,Gorgeousクラスを実装していきます。
import re
import MeCab
import wikipedia
import logging
import shutil
from logging import getLogger
from pykakasi import kakasi
from Levenshtein import distance as D
logging.basicConfig(level=logging.INFO)
log = getLogger(__name__)
class Gorgeous:
"""
君のハートに、レボ☆リューション
gorgeous = Gorgeous()
gorgeous.revolution("まだ助かる")
>>> マダガスカル
"""
def __init__(self, **kwargs) -> None:
k = kakasi()
k.setMode('K', 'a')
self.conv = k.getConverter()
self.tagger = MeCab.Tagger()
self.nations = self.read_nations(**kwargs)
self.nations_roman = [
self.romanize(nation) for nation in self.nations]
self.nations_roman_vowel = [self.extract_vowel(
self.romanize(nation)) for nation in self.nations]
self.recent_answer = ""
return
def read_nations(self, fname="nations.csv", **kwargs) -> list:
"""
Read csv file
published on 『国コード一覧CSV ISO 3166-1』
https://qiita.com/tao_s/items/32b90a2751bfbdd585ea
"""
with open(fname, "r") as f:
nations = f.read().split("\n")
nations = [re.split("[,|]", nation)[0].replace("\"", "") for nation in nations]
nations.pop(0)
return nations
def read_csv_data(self, fname="nations.csv", **kwargs) -> list:
with open(fname, "r") as f:
data = f.read().split("\n")
data = [re.split("[,|]", area)[0].replace("\"", "") for area in data]
data.pop(0)
return data
def clean_str(self, s: str) -> str:
return re.sub(r'[*\s\t\n.,]', "", s)
def katakanize(self, s: str, morph=False, **kwargs) -> str:
"""
convert "kanji" to "katakana"
"""
morphed = [re.split("[,\t\s\n]", w) for w in self.tagger.parse(s).split("\n")]
morphed.remove([""])
morphed.remove(["EOS"])
k = [morph[-1] if morph[-1] != "*" else morph[0] for morph in morphed]
if morph: # morphlogical analysed output
return k
return "".join(k)
def romanize(self, s, **kwargs) -> list:
"""
convert "katakana" to "romaji" via kakasi
(kanji - kana simple inverter)
"""
s = self.katakanize(s, **kwargs)
if type(s) == str:
s = [s]
return [self.conv.do(w) for w in s]
def extract_vowel(self, word: str, **kwargs) -> str:
"""
extract vowels from romanized words
"""
if type(word) == list:
return [self.extract_vowel(w) for w in word]
return "".join([l for l in word if l in ["a", "i", "u", "e", "o", "n"]])
def revolution(self, sentence: str, **kwargs) -> str:
"""
Revolution: Get Similar Nation Name from Word
gorgeous.revolution("まだ助かる")
>>> マダガスカル
args
----
n_result : default=5 : lines of result print
vowel : default=False : if true, word-distance will be calculated based on vowels
"""
# default kargs
n_result = kwargs.get('n_result', 3)
vowel = kwargs.get('vowel', False)
print("INPUT: ", sentence)
# sentence -> [words] -> [katakana] -> [roman]
word_roman = self.romanize(sentence, **kwargs)
print("ROMAN: ", word_roman)
if vowel:
word_vowel = self.extract_vowel(word_roman)
print("VOWEL: ", word_vowel)
dists = [D(word_vowel[-1], nation[0]) for nation in self.nations_roman_vowel]
else:
dists = [D(word_roman[-1], nation[0]) for nation in self.nations_roman]
idx = sorted(range(len(dists)), key=lambda k: dists[k])
# logging
print("RESULT:")
for i in range(n_result):
if vowel:
print(f"\tNo.{i+1} : {self.nations[idx[i]]} ({self.nations_roman_vowel[idx[i]]}) : ({dists[idx[i]]})")
else:
print(f"\tNo.{i+1} : {self.nations[idx[i]]} ({self.nations_roman[idx[i]]}) : ({dists[idx[i]]})")
self.recent_answer = self.nations[idx[0]]
# Answer
print(f"ここ!({self.googlemap()})")
print("-" * shutil.get_terminal_size()[0]) # draw line
print(f"{self.wikipedia()[1]}!!\n")
print(u"☆" * shutil.get_terminal_size()[0]) # draw line
return self.recent_answer
def googlemap(self, place=None) -> str:
"""generate Google Map Link"""
if place is None:
place = self.recent_answer
return f"https://www.google.com/maps/search/{place}/"
def wikipedia(self, place=None) -> tuple:
"""Generate Wikipedia Link"""
if place is None:
place = self.recent_answer
wikipedia.set_lang("ja")
p = wikipedia.page(wikipedia.search(place)[0])
return (p.title, p.summary, p.url)
def showtime(self, **kwargs) -> None:
print("【ゴー☆ジャスのショータイム!】")
print(f"\n- 【お題】を入力してくれよな!\n- ランキングを{kwargs.get('n_result', 3)}件表示するぞ!\n- 地球義ではなく、GoogleMapとWikipediaの情報を出力するぞ!")
print(u"☆" * shutil.get_terminal_size()[0]) # draw line
while True:
place = input("\n【お題】を入力: ")
if place in ["終了", "end", "終わり"]:
break
self.revolution(place, **kwargs)
print("また遊んでくれよな!")
return
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description='キミも、ゴー☆ジャスになろう!')
parser.add_argument('-N', '--n_line', help="結果表示数", default=3)
parser.add_argument('-F', '--file', help="nations.csv ファイルパス",
default='nations.csv')
parser.add_argument('-V', '--vowel', help="母音モード", action='store_true')
args = parser.parse_args()
gorgeous = Gorgeous(fname=args.file)
gorgeous.showtime(vowel=args.vowel, n_result=args.n_line)
ゴー☆ジャステスト
本家ゴー☆ジャス通りレボリューションできるかテストします。
>>> gorgeous = Gorgeous()
>>> gorgeous.revolution("まだ助かる")
INPUT: まだ助かる
ROMAN: ['madatasukaru']
RESULT:
No.1 : マダガスカル (['madagasukaru']) : (1)
No.2 : ツバル (['tsubaru']) : (6)
No.3 : カザフスタン (['kazafusutan']) : (7)
>>> 'マダガスカル'
出力数と母音判定モードを試します。
>>> gorgeous.revolution("まだ助かる", vowel=True, n_result=10)
INPUT: まだ助かる
ROMAN: ['madatasukaru']
VOWEL: ['aaauau']
RESULT:
No.1 : マダガスカル (['aaauau']) : (0)
No.2 : カザフスタン (['aauuan']) : (2)
No.3 : ジブラルタル (['iuauau']) : (2)
No.4 : バヌアツ (['anuau']) : (2)
No.5 : パラグアイ (['aauai']) : (2)
No.6 : アメリカ合衆国 (['aeiaauou']) : (3)
No.7 : アルバ (['aua']) : (3)
No.8 : エルサルバドル (['euauaou']) : (3)
No.9 : ガイアナ (['aiana']) : (3)
No.10 : カタール (['aau']) : (3)
'マダガスカル'
>>> gorgeous.revolution("腹の具合が")
INPUT: 腹の具合が
ROMAN: ['haranoguaiga']
RESULT:
No.1 : パラグアイ (['paraguai']) : (5)
No.2 : アンギラ (['angira']) : (7)
No.3 : ウルグアイ (['uruguai']) : (7)
'パラグアイ'
>>> gorgeous.revolution("やる気無さそう")
INPUT: やる気無さそう
ROMAN: ['yarukinasaso-']
RESULT:
No.1 : ブルキナファソ (['burukinafaso']) : (4)
No.2 : アルジェリア (['arujieria']) : (8)
No.3 : アルバニア (['arubania']) : (8)
'ブルキナファソ'
>>> gorgeous.revolution("パパは牛乳屋")
INPUT: パパは牛乳屋
ROMAN: ['papawagiyu-nyu-ya']
RESULT:
No.1 : パプアニューギニア (['papuanyu-ginia']) : (9)
No.2 : アンティグア・バーブーダ (['anteiguaba-bu-da']) : (12)
No.3 : キューバ (['kiyu-ba']) : (12)
'パプアニューギニア'
>>> gorgeous.revolution("飯行こ")
INPUT: 飯行こ
ROMAN: ['meshiiko']
RESULT:
No.1 : メキシコ (['mekishiko']) : (3)
No.2 : シリア (['shiria']) : (5)
No.3 : セーシェル (['se-shieru']) : (5)
'メキシコ'
>>> gorgeous.revolution("馬鹿な")
INPUT: 馬鹿な
ROMAN: ['bakana']
RESULT:
No.1 : ガイアナ (['gaiana']) : (2)
No.2 : バハマ (['bahama']) : (2)
No.3 : ガーナ (['ga-na']) : (3)
'ガイアナ'
馬鹿な…!ガイアナ?現状は出力が50音順になっていますが,一応正解である「バハマ」も同率一位となっています。
>>> gorgeous.revolution("売るくらいなら")
INPUT: 売るくらいなら
ROMAN: ['urukurainara']
RESULT:
No.1 : ウクライナ (['ukuraina']) : (4)
No.2 : ウルグアイ (['uruguai']) : (6)
No.3 : アルバニア (['arubania']) : (7)
'ウクライナ'
>>> gorgeous.revolution("押すとラリアット")
INPUT: 押すとラリアット
ROMAN: ['osutorariatto']
RESULT:
No.1 : オーストラリア (['o-sutoraria']) : (4)
No.2 : オーストリア (['o-sutoria']) : (6)
No.3 : エストニア (['esutonia']) : (7)
'オーストラリア'
>>> gorgeous.revolution("あるある全身")
INPUT: あるある全身
ROMAN: ['aruaruzenshin']
RESULT:
No.1 : アルゼンチン (aruzenchin) : (4)
No.2 : アルメニア (arumenia) : (7)
No.3 : ベラルーシ (beraru-shi) : (7)
No.4 : マレーシア (mare-shia) : (7)
No.5 : アルジェリア (arujieria) : (8)
'アルゼンチン'
>>> gorgeous.revolution("こすだりか")
INPUT: こすだりか
ROMAN: ['kosudarika']
RESULT:
No.1 : コスタリカ (['kosutarika']) : (1)
No.2 : オーストリア (['o-sutoria']) : (5)
No.3 : ソマリア (['somaria']) : (5)
'コスタリカ'
最後に我々SFC生の父である村井純先生で試します。
>>> gorgeous.revolution("村井純")
INPUT: 村井純
ROMAN: ['muraijun']
RESULT:
No.1 : ブラジル (['burajiru']) : (4)
No.2 : フランス (['furansu']) : (4)
No.3 : マラウイ (['maraui']) : (4)
'ブラジル'
かなり出来ていそうですね。そして,最後に回答した国名のGoogle MapやWikipediaの結果用urlを示してくれます。 このIT時代,地球儀で指し示すより便利です。
>>> gorgeous.googlemap()
'https://www.google.com/maps/search/ブラジル/'
>>> gorgeous.wikipedia()
'ブラジル',
'ブラジル連邦共和国\nRepública Federativa do Brasil\n\n国の標語:Ordem e Progresso(ポルトガル語: 秩序と進歩)\n国歌:Hino Nacional Brasileiro(ポルトガル語)ブラジルの国歌\n\nブラジル連邦共和国(ブラジルれんぽうきょうわこく、ポルトガル語: República Federativa do Brasil)、通称ブラジルは、南アメリカに位置する連邦共和制国家である。南米大陸で最大の面積を占め、ウルグアイ、アルゼンチン、パラグアイ、ボリビア、ペルー、コロンビア、ベネズエラ、ガイアナ、スリナム、フランス領ギアナ(つまりチリとエクアドル以外の全ての南米諸国)と国境を接している。また、大西洋上のフェルナンド・デ・ノローニャ諸島、トリンダージ島・マルティン・ヴァス島、サンペドロ・サンパウロ群島もブラジル領に属する。その国土面積は日本の22.5倍で、アメリカ合衆国よりは約110万km2小さいが、ロシアを除いたヨーロッパ全土より大きく、インド・パキスタン・バングラデシュの三国を合わせた面積の約2倍に相当する。首都はブラジリア。\n南アメリカ大陸最大の面積を擁する国家であると同時にラテンアメリカ最大の領土、人口を擁する国家で、面積は世界第5位である。南北アメリカ大陸で唯一のポルトガル語圏の国であり、同時に世界最大のポルトガル語使用人口を擁する国でもある。公用語はポルトガル語ではあるがスペイン語も比較的通じる。ラテンアメリカ最大の経済規模であり、同時に世界で7番目の経済規模でもある。\nブラジルは北部は赤道直下で、全体的に海流等の影響もあり気候は大変温暖であり、中南米最多の人口と経済規模である。',
'https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%A9%E3%82%B8%E3%83%AB')
ゴー☆ジャスのショー☆タイム (コマンドラインアプリケーション)
想像を超えた反響があったので、追記しました。 2019-07-18
argparseやshutilを用いて,gorgeousモジュールにif __name__ == "__main__"を追記しコマンドラインから呼べるものにしました。
Gorgeous.showtime()で実行できます。
--> python gorgeous.py -h
usage: gorgeous.py [-h] [-N N_LINE] [-F FILE] [-V]
キミも、ゴー☆ジャスになろう!
optional arguments:
-h, --help show this help message and exit
-N N_LINE, --n_line N_LINE
結果表示数
-F FILE, --file FILE nations.csv ファイルパス
-V, --vowel 母音モード
実行例
--> python gorgeous.py -F ../nations.csv -N 5
【ゴー☆ジャスのショータイム!】
- 【お題】を入力してくれよな!
- ランキングを5件表示するぞ!
- 地球義ではなく、GoogleMapとWikipediaの情報を出力するぞ!
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
【お題】を入力: パパは牛乳屋
INPUT: パパは牛乳屋
ROMAN: ['papawagiyu-nyu-ya']
RESULT:
No.1 : パプアニューギニア (['papuanyu-ginia']) : (9)
No.2 : アンティグア・バーブーダ (['anteiguaba-bu-da']) : (12)
No.3 : キューバ (['kiyu-ba']) : (12)
No.4 : ニカラグア (['nikaragua']) : (12)
No.5 : パラグアイ (['paraguai']) : (12)
ここ!(https://www.google.com/maps/search/パプアニューギニア/)
--------------------------------------------------------------------------------------------
パプアニューギニア独立国
Independent State of Papua New Guinea(英語)Independen Stet bilong Papua Niugini(トク・ピシン)Papua Niu Gini(ヒリモツ語)
国の標語:多様性は団結なり
国歌:すべてのものよ立ち上がれ
パプアニューギニア独立国(パプアニューギニアどくりつこく)、通称パプアニューギニアは、南太平洋にあるニューギニア島の東半分及び周辺の島々からなる立憲君主制国家。東南アジア諸国連合(ASEAN)の特別オブザーバーであるが、地理的にはオセアニアに属する。オーストラリアの北、ソロモン諸島の西、インドネシアの東、ミクロネシア連邦の南に位置する。イギリス連邦加盟国かつ英連邦王国の一国であり、非白人が国民の多数を占める国としては英連邦王国のうち人口最多・面積最大の国である。!!
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
【お題】を入力: 終了
また遊んでくれよな!
終了, end, 終わり等を入力すると終わります。
まとめ
実際に本人とかなり近い結果を得られるものを作ることができました。これを今後はLINE BotにしたりAPI化したり, もしくはローカルな地名にも対応 (nations.csvを拡張するだけ) させたりできればいいなと思います。
こんな展開、ファン☆タスティック!