遅まきながら、Sparkのプログラミングを勉強しようかなー、と思い
まずは環境整備!と思ったんですが、根が怠け者だし、Sparkは現物のHadoopなしでも動く(はずな)ので、
- 手持ちのWindows PCだけでなんとかしたい!( LinuxのVM作るの面倒)
- 手慣れたEclipse(ScalaIDE)で動くようにしたい!
- どうせなら最新のSpark 1.6で新しい機能も勉強しよう!
- (一応プログラミング言語はScalaを前提に)
と思いました。でネット上の情報を色々調べながら取り組んだのですが、情報が古かったり、sbteclipseで..(略)と面倒だったり、で結構ハマりました。色々試した結果、今の時点で一番簡単と思う方法があったのでメモしておきます。ネタ元は1.2 How to run Spark with Eclipse and Scala, Standalone Development: で、要は**「ScalaIDEで普通のScalaプロジェクト作って、一旦mavenプロジェクトに変換してからpom.xmlにSparkのコンポーネントのエントリーをサクッと書けば、あとはお任せ!」**ってことでした。
以下手順を書いていきます。ソフトウエアは記事執筆時点(2016/2月)時点の最新のものを使いました。
はじめに~当手順はWindows 64bit版用です。32bit版ではうまくいきません。
当記事はWindows 7 64bit版での手順となります。残念ながら32bit版では 「5. winutils.exeのダウンロードとHADOOP_HOMEの設定」でのwinutil.exe 32bit版の入手が簡単にはできず、「サクッ」と進みません。当記事の末尾にこの辺の事情を書いておきますが、ご利用のWindowsが64bit版であることをまずご確認ください。
0.全体の流れ
- 前提環境としてJava/Maven/Scala/ScalaIDEをインストール・準備
- ScalaIDEでScala Projectを作成しMaven Projectに変換
- ScalaIDE上でpom.xmlにSparkのエントリーを記述
- SparkのインストールはMavenにお任せ(休憩タイム)
- winutils.exeのダウンロードとHADOOP_HOMEの設定
- プログラム「SparkPi」を実行して稼働確認
- (オプション) ログの抑制
1.前提環境としてJava/Maven/Scala/ScalaIDEをインストール・準備
下記で未導入のものがあればダウンロードしてインストールします。バージョンは記事執筆時点の最新を書いているだけですので、やってませんが少しくらい違うバージョンでも導入してあれば問題ないんじゃないかと思われます。
| コンポーネント | バージョン | インストールの概要 |
|---|---|---|
| Windows 7 | 64bit版 | N/A |
| JDK | 1.8 | インストーラで導入後、環境変数でJAVA_HOMEとPATHを設定 |
| Maven | 3.3.9 | unzipして環境変数PATHを設定 |
| Scala | 2.11.7 | インストーラで導入後、リブート(でPATHが通る) |
| Scala IDE | 4.3.0 | 丸ごとダウンロードしてunzipするだけ |
| Spark | 1.6 | ScalaIDE上のmavenで自動的にダウンロード&インストールする(ので事前作業不要) |
導入の確認は以下のコマンドが通ればOKです。
| コンポーネント | コマンド |
|---|---|
| JDK | java -version |
| Maven | mvn --version |
| Scala | scala -version |
2. ScalaIDEでScala Projectを作成しMaven Projectに変換
- ScalaIDEを展開したディレクトリでeclipse.exeをダブルクリックしてScalaIDEを起動します
- パッケージエクスプローラーで「右クリック」-> 「New」-> 「Scala Project」-> お好きなプロジェクト名を付けて「Finish」
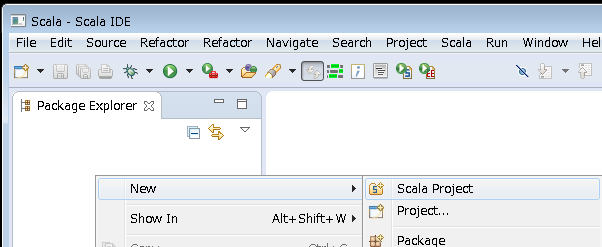
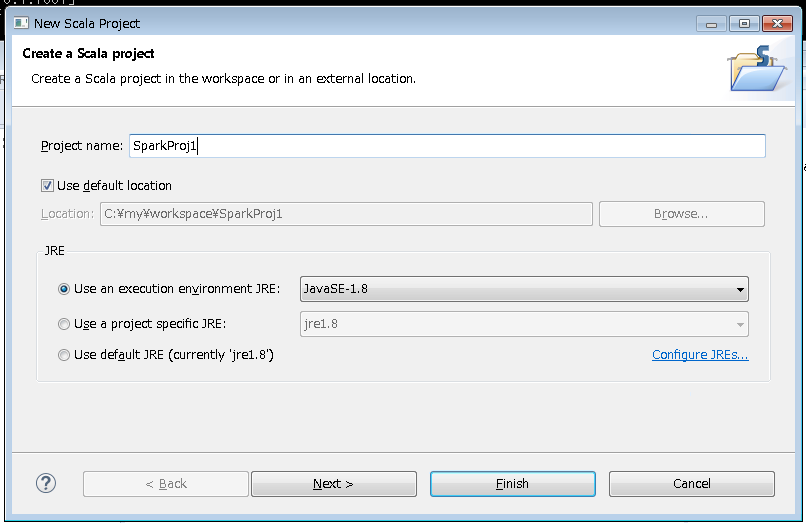
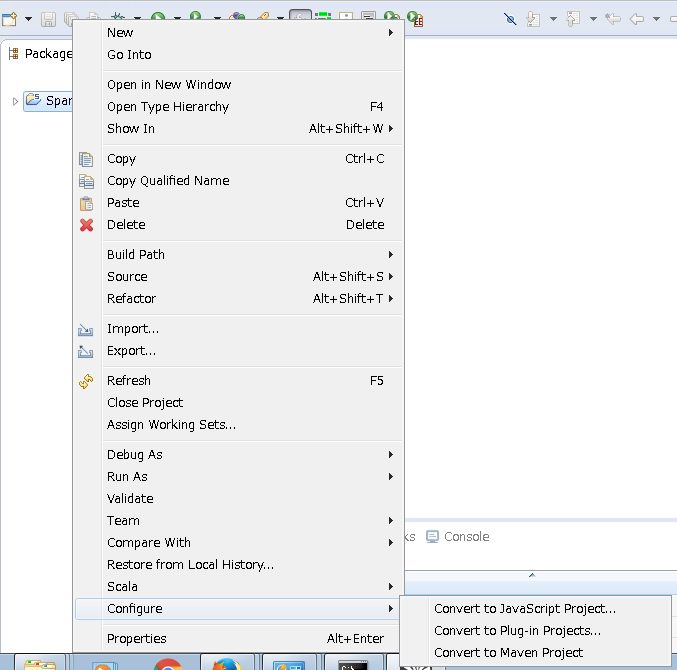
3.Scalaのプロジェクトができたら、プロジェクトを右クリックして-> 「Configure」-> 「Convert to Maven Project」
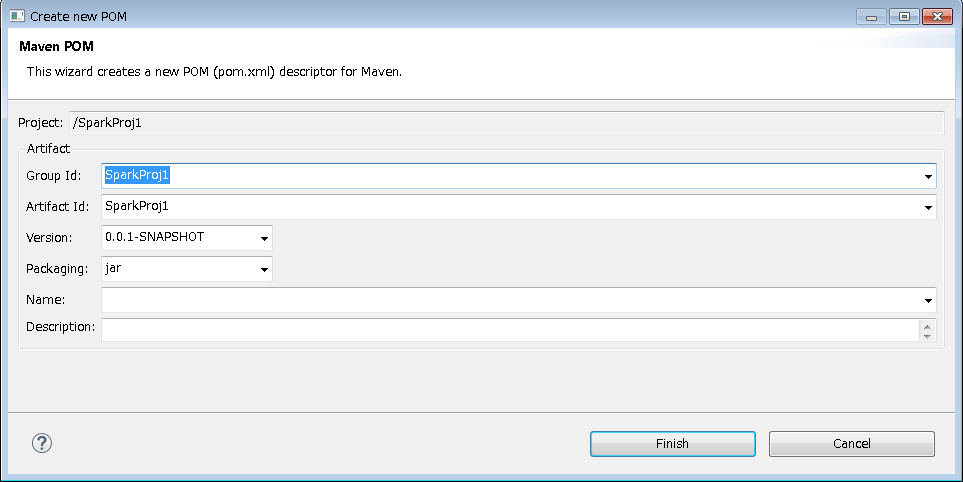
そのままFinishボタン
3. ScalaIDE上でpom.xmlにSparkのエントリーを記述
- 生成されたpom.xmlをダブルクリックで開き、エディターが起動したらXMLのソースを直接編集します。 </build> の下に下記のように<dependencies>~</dependencies>の部分をコピペで追加します。最小限ならspark-core_XXXだけでいいのですが、SparkSQLやSparkStreamingなども勉強したいので、一通りのものを定義しています。( 2.11や1.6.0などのバージョン指定はお好みでご変更ください。記事執筆時点の最新を指定しています)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Spark1</groupId>
<artifactId>Spark1</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<!-- ここから -->
<dependencies>
<!-- Spark dependencies -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.6.0</version>
</dependency>
<dependency> <!-- Spark SQL -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>1.6.0</version>
</dependency>
<dependency> <!-- Spark Streaming -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>1.6.0</version>
</dependency>
<dependency> <!-- Spark MLlib -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>1.6.0</version>
</dependency>
<dependency> <!-- Spark GraphX -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
<!-- ここまで -->
</project>
2.変更を保管するとmavenが自動的にネット上のmavenリポジトリーから必要なライブラリー群のダウンロードを開始し、(=インターネット接続が必要です。) その後、ワークスペースのビルドを行います。時間がかかるのでしばしご休憩ください。

補足1) 今回はXMLを直に書き換えましたがDependenciesパネルでAddボタンでパネルを表示して追加しても結構です。
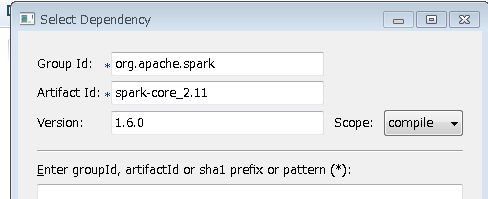
最終的には以下のようになります。
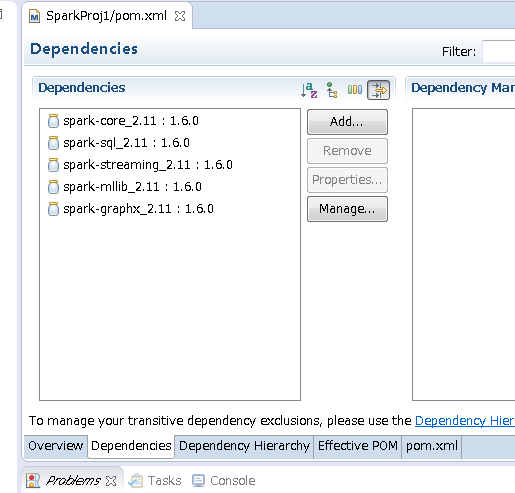
補足2) 今回は現時点の最新のartifactIdが2.11でversionが1.6.0を指定しましたが、また新しいものが出た場合はThe Central Repository Browser を見て、最新のartifactIdとversionを指定すればいいはずです。
4. SparkのインストールはMavenにお任せ(休憩タイム)
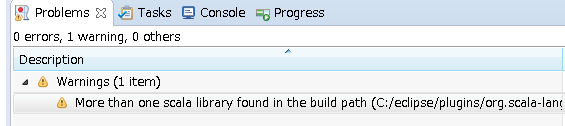
ダウンロードとワークスペースのビルドが終わると以下の警告が出ましたが、無視していいそうです。
5. winutils.exeのダウンロードとHADOOP_HOMEの設定
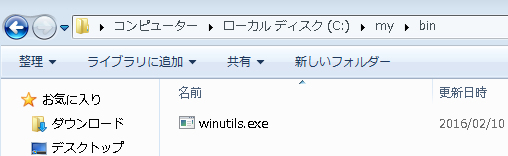
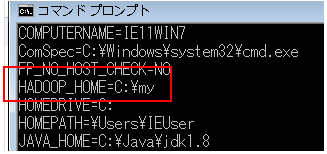
winutils.exe(64bit版です)をここからダウンロードして適当なディレクトリの**\binに保存。(例 c:\my\binに保存) その親ディレクトリー**(例 c:\my) を環境変数HADOOP_HOMEに設定します。(\binなし!)
参考記事How to run Apache Spark on Windows7 in standalone mode
これを行わないと処理内容によっては以下のようなエラーになります。

6. プログラム「SparkPi」を実行して稼働確認
Scalaアプリでプログラミング環境の確認をします。Sparkの「初めの一歩」でよく出てくるSparkPiを実行してみましょう。
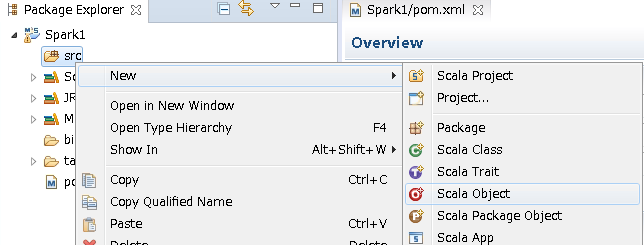
1.srcフォルダーで「右クリック」->「New」->「Scala Object」
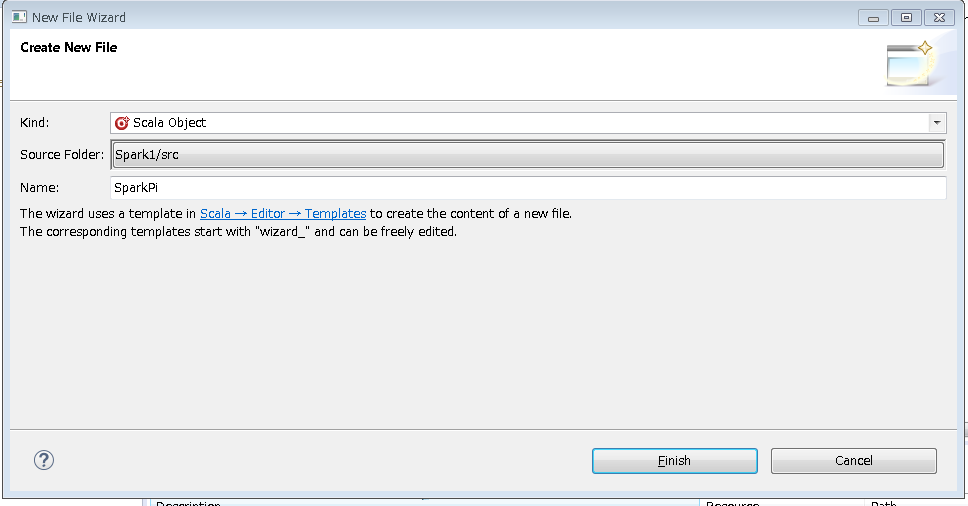
2.Nameに「SparkPi」と入力して「Finish」
3.プロジェクト・エクスプローラでSparkPi.scalaを開いて以下のコード一式をコピペ(置換)して保存
import scala.math.random
import org.apache.spark._
/** Computes an approximation to pi */
object SparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi")
.setMaster("local")
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
4.ビルドのエラーなどが無ければコンパイルは成功していますのでいざ実行!です。SparkPiを右クリックして「RunAs」->
Spark1.5まで→「Scala Application」でそのまま実行します
Spark1.6から→「Run Configurations」で構成を行います
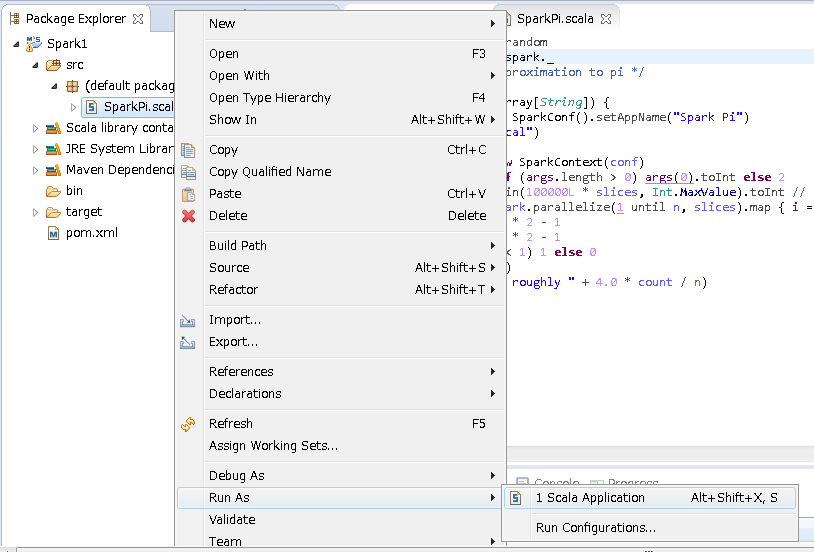
5.(Spark 1.6の場合) Run ConfigurationsのArgumentタブのVM argumentに -Xmx1024m -Xms512m の指定を追加してから実行します。
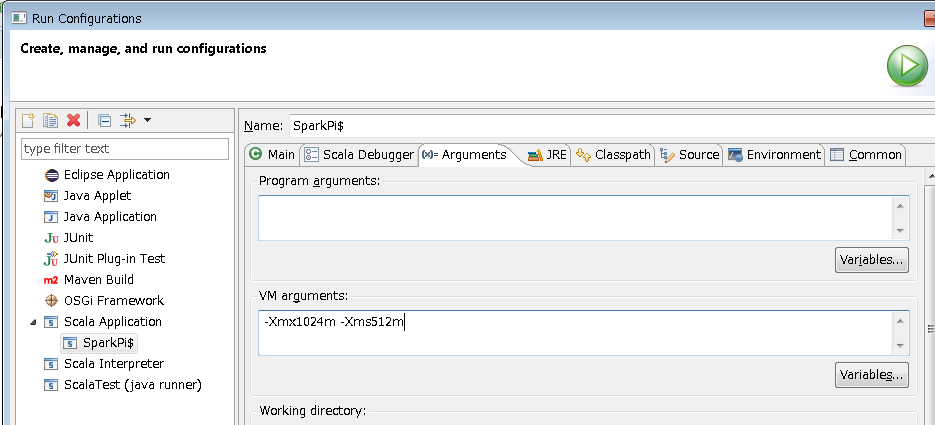
6.Consoleに「Pi is roughly 3.1414」が表示されれば成功です。
これでプログラミング環境が出来たのでQiitaやBigData Universityなど見ながら、早速プログラミングのお勉強を始めましょう!
補足) なぜ上でSpark 1.6の場合にのみ -Xmx/-Xmsを指定したかと言うと、Spark1.6からメモリの使い方が変わったらしく、そのまま実行すると以下のようなエラーになるためです。
Spark 1.6で(Heapの指定なくデフォルトで)そのまま実行した場合

16/02/09 23:50:32 ERROR SparkContext: Error initializing SparkContext.
java.lang.IllegalArgumentException: System memory 259522560 must be at least 4.718592E8. Please use a larger heap size.
at org.apache.spark.memory.UnifiedMemoryManager$.getMaxMemory(UnifiedMemoryManager.scala:193)
[翻訳] Spark Memory Management since 1.6.0によれば
Spark executor に最低でも 1.5 * Reserved Memory = 450MB の Heap を与えなければ、”please use larger heap size” というエラーメッセージをだします。
とのことなので、これは仕様です。
7. (オプション) ログの抑制
実行するとINFOレベルの赤いメッセージがたくさん出ます。これはこれで中の動きをみる勉強にはなりますが、毎回出てもうざいのでlog4.propertiesを定義してWARN以上を出すように変更します。

log4j.propertiesの例。例えばプロジェクトの直下に置きます。
## Set everything to be logged to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
## Settings to quiet third party logs that are too verbose
log4j.logger.org.spark-project.jetty=WARN
log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
あとは実行時のclasspathでこのファイルが見つかればよいので、以下のように実行時の構成でプロジェクト直下のフォルダーを指定します。
Run Configurations -> Classpath タブ -> User Entries -> Advanced ボタン -> Add Folders -> Choose folders to add でlog4j.propertiesの存在する場所を選択(下記の例ではプロジェクト直下なので「Spark1」を選択) -> OK
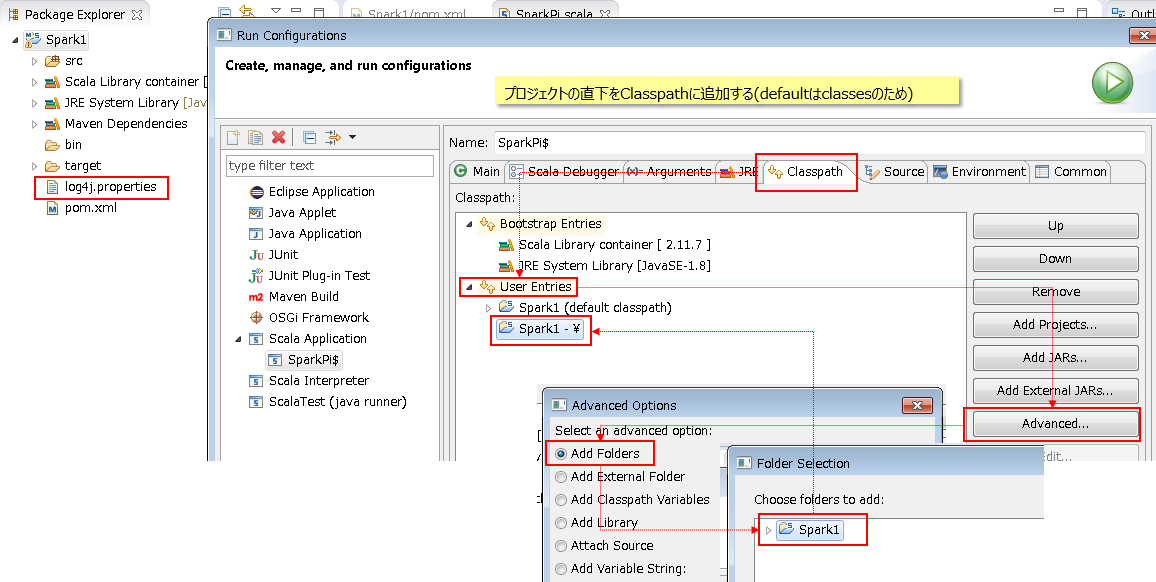
これで実行すると以下のようにSparkのメッセージが抑制されます。

ご参考
今回はお勉強用にサクッと環境を作ったわけですが、もっと本格的なアプリ開発で外部のjarなどにまとめたい場合は以下の記事が有用でした。(pom.xmlのSparkのバージョンは変えましたが) この記事の通りにやったら、うまくいきましたのでメモしておきます。
How to build a Spark fat jar in Scala and submit a job
(補足) なぜWindows 32bit版はダメか?
SparkはHadoopに依存していないと思っていましたが、そうは言っても一部のコードではHadoopを使っているようです。その場合にWindowsとHadoopコードの橋渡しのためにWinutil.exeが必要になるのですが、これ、64bit版はHortonworksさんのサイトからダウンロードできるのですが、32bit版はどこにも見当たりません。。。(なおWindows 7 32bitに上記でダウンロードした64bit版のWinutil.exeを設定しても、(当然ながら)エラーになります。)
ネットで検索したところ困っている人はたくさんいるようで質問は多数ヒットするのですが、要は結論は「自分でVC++とかでソースコードからビルドして作れば?」ってことのようで、「サクッと」という主旨から考えるに、そこまでやる意味を見出せません。(前出のSparkPiのソースなどはwinutil.exeなしでも動くんですがね。。)ので当記事では64bit版を前提にした次第です。
以上です。