こちらの記事を翻訳しました。
Apache Spark 1.6.0 が開発開始され、メモリ管理モデルが変わりました。古いメモリ管理モデルはStaticMemoryManger class でした。今はそれが"legacy"と呼ばれています。"Legacy" モードはデフォルトでオフになっています。これは、1.5.x と1.6.0で同じコードを動かすと違う結果になります。これには気をつけてください。互換性のために spark.memory.useLegacyMode parameter を enableにすることができます。これはデフォルトではオフです。
約1年ほど前に、私は、"legacy" model のメモリ管理をSpark Architecture という記事で書きました。私はSpark Shuffle の実装に関しても簡単にメモリ管理について書きました。
この記事は Apache Spark 1.6.0 で使われている UnifiedMemoryManagerでの新しいメモリ管理モデル
について説明します。
簡単にまとめますと新しいメモリ管理モデルはこのようになっています。
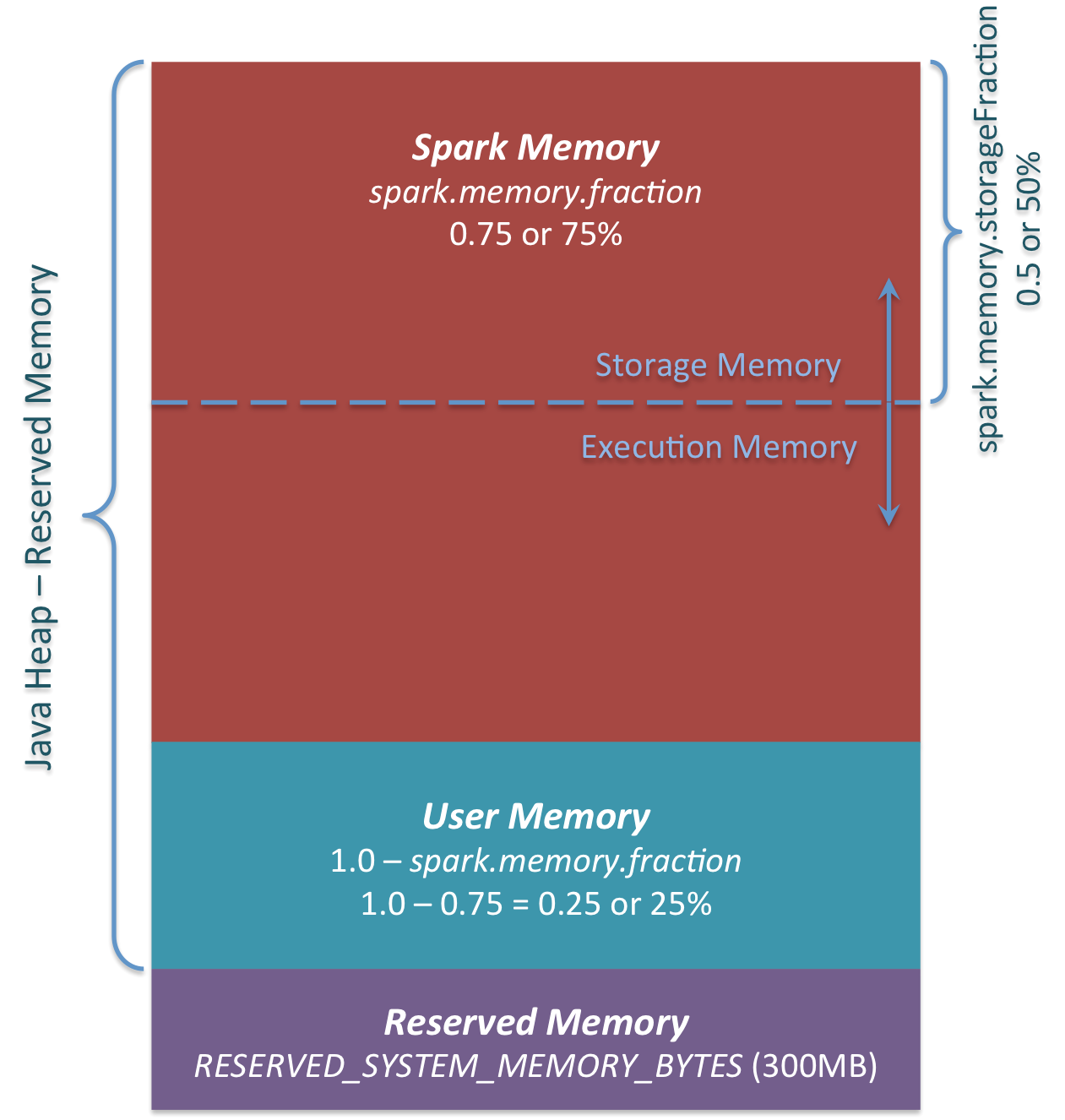
3つの主なメモリ領域が図に見えます。
Reserved Memory
システムによって予約されたメモリです。このサイズはハードコードされています。Spark 1.6.0ではこの値は 300MBです。300MB の RAM は Spark の計算には使われません。この値は Spark をリコンパイルするかspark.testing.reservedMemory を変えなかれば変更はできません。この値はテスト用の値なので production で変更することはオススメできません。このメモリは "reserved" と呼ばれ Spark によって使われることはありません。この値は Spark の使用情報がどれだけメモリを使用できるかという上限を設けることができます。もし Java Heap を Spark のキャッシュのためにすべて使いたい場合であっても、この"reserved" 領域は使われることはありません。(実際は予備というわけではありません。Sparkのinternal objectを保存する場所となります。) Spark executor に最低でも 1.5 * Reserved Memory = 450MB の Heap を与えなければ、”please use larger heap size” というエラーメッセージをだします。
User Memeory
このメモリプールは Spark のメモリ確保した後もメモリに残っています。このメモリをどう使うかはユーザに委ねられています。RDD の変形で使うデータ構造を保存することができます。たとえば、集約のために Hash table を持ちUserMemory を使うかもしれない Spark の mapPartitions 変形のオペレータを書き直すことができます。Spark 1.6.0 に置いては、メモリプールのサイズは次のように計算されます。"Java Heap" - "Reserved Memory" * (1.0 - spark.memory.fraction) デフォルトでは、次と等価です。("Java Heap" - 300MB) * 0.25 例として、4GB の Heap では 949MB の UserMemory を持つことができます。再びですが、この UserMemory に対してどのようなデータを保存するかはユーザによります。Spark はユーザが何をするか、そしてメモリ領域の境界を超えるかどうかには全く関与しません。もしもこのメモリ領域を無視してしまった場合、 OOM error を発生するかもしれません。
Spark Memory
これは Apache Spark によって管理されるメモリプールです。このサイズは次のように計算されます。("Java Heap" - "Reserved Memory") * spark.memory.fraction. Spark 1.6.0 では("Java Heap" - 300MB) * 0.75 です。例として 4GB の Heap では Spark Memory は2847MB になります。このメモリプールは2つ領域に割り当てられます。Storage Memory と Execution memory です。この境界は spark.memory.storageFraction パラメータで変更することができます。デフォルトでは 0.5 です。この新しいメモリ領域のアドバンテージはこの境界が静的ではないことです。そしてもしもメモリ プレッシャーが起きた場合、境界が変化します。たとえば、片方の領域がもう一方から領域を借りサイズを増加させることができます。さてこのメモリ境界がどのように変化するかについては後ほどぎろんします。まずはこのメモリがどのように使われるかについて議論しましょう。
Storage Memory
このメモリプールは Spark のキャッシュデータとシリアライズされたデータの "unroll" するための一時的なスペースとしてつかわれます。また "broadcast"のデータもキャッシュブロックとして保存されます。もし "unroll"に興味があるのでしたらこの unroll のコードを見てください。見ての通り、unroll は unroll されたブロックのための十分なメモリを必要としません。unroll したパーティションのためにメモリが十分でない場合でパーシステンスのレベルがドライブにデータヲク事を許すのであれば、ドライブに直接データが置かれます。"broadcast"に関しては、すべてのブロードキャストされたデータは MEMORY_AND_DISK パーシステンスレベルに伴いデータがキャッシュされます。
Execution Memory
このメモリプールは Spark のタスクを実行する間に必要なオブジェクトを保存します。たとえば、Mapサイドのシャフルの中間状態のバッファを保存するためであったり、 hash aggregation に使われる hash table を保存するために使われます。このメモリプールはメモリが充分でない場合にはディスクにデータが書き込まれます。しかしながら、このメモリプールからブロックをほかのスレッド(タスク)から排除することはできません。
では、Storage Memory と Execution Memory の境界がどのように動くかについて議論していきましょう。Execution Memory の特性として強制的にメモリプールからブロックを排除することができません。なぜならば、これらは中間計算に使われ、このメモリを必要とする処理はこのメモリブロックがないとブロックがないといい失敗します。 Storage Memory( RAM の中の単純なキャッシュ)についてはこの限りではありません。もし、メモリプールからブロックを排除するのであれば、ブロックのメタデータをブロックがHDDへ退去させられた(もしくは 単に削除された)とし更新することができます。Spark はこのブロックを HDD から読もうとするかペーシステントレベルが HDD への書き込みを許さないのであれば、再計算します。
Storge Memory からブロックを強制的に退去させることができます。一方、Execution Memory に関してはできません。いつ Execution Memory は Storage Memory からメモリを書いてくるのでしょうか?下記の場合に起こります。
-
Storage Memoryにメモリのあまりがあった場合。たとえば、キャッシュされたブロックがすべてのメモリを使っていない場合。この場合はStorage Memory pool サイズを減らし、Execution Memory プールを増やします。
-
Storage Memory プールサイズが初期のStorage Memory領域のサイズを超え、すべての領域が使われた時。この場合で初期のサイズに達しない時にメモリ上のブロックがStorage Memory プールから強制的に退去( drive に書き出される)させられます。
次に, Storage Memory プールは Execution Memory プールにあまりがある場合、領域を Exection Memory から借りることができます。
初期の Strage Memory 領域のサイズは、次のように計算されます。“Spark Memory” * spark.memory.storageFraction = (“Java Heap” – “Reserved Memory”) * spark.memory.fraction * spark.memory.storageFraction. デフォルトでは次と等価です。 (“Java Heap” – 300MB) * 0.75 * 0.5 = (“Java Heap” – 300MB) * 0.375. たとえば、4GBのHeapでは 1423.5MB の RAM が初期の Storage Memory として使われます。
これは、もし Spark のキャッシュと executor 上のキャッシュのデータの量の合計が初期の Storage Memoryの大きさと同じであれば、少なくともStorage領域のサイズは初期のデータサイズと一緒と言うこと意味します。なぜならばサイズを小さくしながらデータをメモリから退去させることができないからです。しかしながら、Storage Memory を使い尽くす前に Execution Memory の領域が初期のサイズを超える場合、Execution Memory から強制的にエントリを退去させることはできません。最終的に、Execution Memory がメモリを保持したまま、(メモリが Execution Memory に専有されたので)小さい Storage Memory Size まま処理を行います。