昨今の対話システムの盛り上がりから、人とコミュニケーションを取るようなロボットを開発したい・・・!と思う方も多いのではないかと思います。
私自身、以前対話ロボットの研究開発をしていました。そこで直面したのは、LINEやTwitter上で動く対話ボットと異なり、物理で存在するロボットは音声認識の問題や、人の動きといった「対話外」の情報をどう活用するかなど、とても多くの考慮点があるということでした。
そこで、本記事ではその研究をしていく中で得た知識を展開(供養)しようと思います。これから人のパートナーとなるようなロボットの開発をする方にとっての参考となれば幸いです。
研究領域の全体像
まず、対話ロボットにおける研究領域の全体像は以下のような形になります。
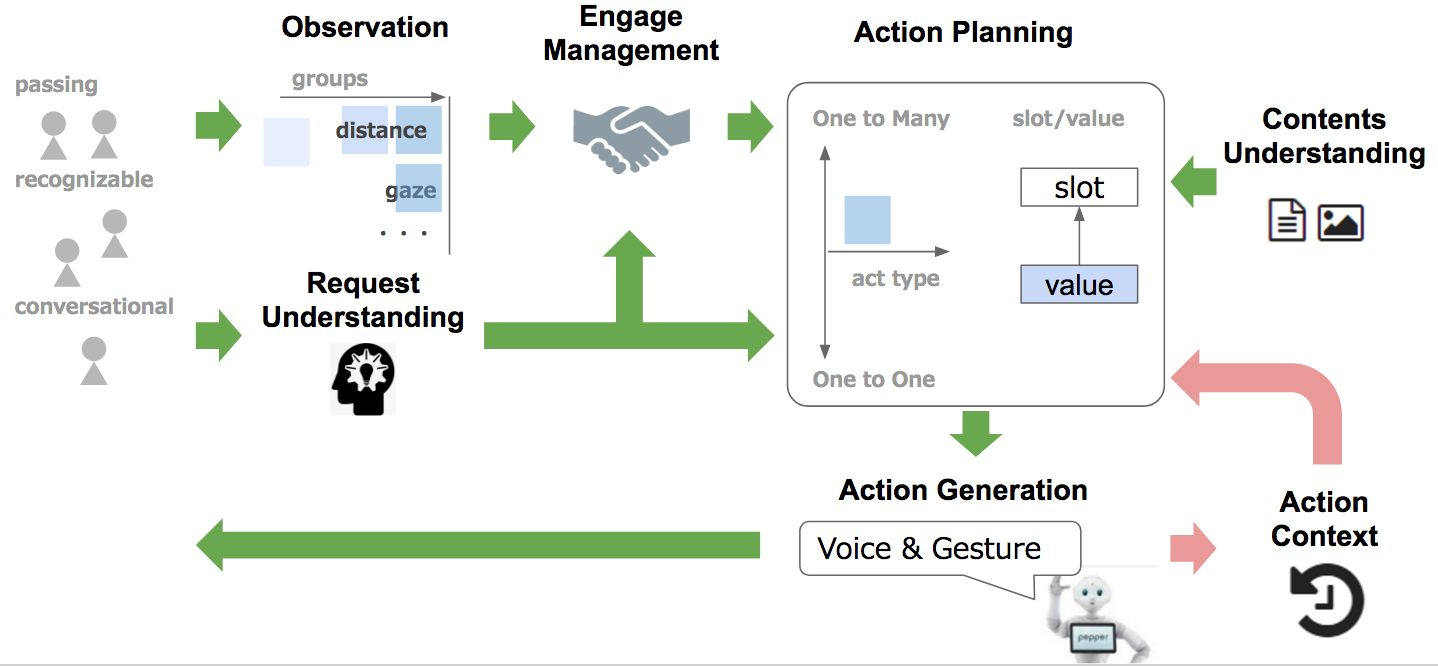
- Observation
- 近づいて来る人や周辺環境(天気・時刻など・・・)を観測し、置かれている状況の情報を更新する
- Request Understanding
- 外部から意図的なアクション(話しかけられる、触られるなど場合など)が取られた場合、その意図を解釈する
- Engage Management
- 対話状態の推定と管理
- Action Planning
- Engageの状態、またAction Contextに応じた行動計画を立案する
- Content Understanding
- 外部知識の獲得、保存
- Action Generation
- 発話以外に、ジェスチャーなども含めた行動を生成
- Action Context
- これまでの相手/自身行動履歴を蓄積し、Action Planningに活かす
対話ロボットに特徴的な点として、「対話に入る前」の時にどう行動するかという点と、発話以外の要素の理解・生成という点が挙げられます。
対話ロボットの形式としては人に話しかけられるのを黙ってずっと待っているというスタイルもありなのですが、せっかく画像も音声も取れるのだから、周辺環境を観測し、「対話状態に入れる(Engageできる)可能性が高い」なら、何か行動を起こしたほうが良いことは明らかです。
そのため、Action Planningは対話状態に入った後の1:1(one to one)の行動だけでなく、1:N(one to many)の状態から対話に導くための行動についても計画を行う必要があります。
また、ロボットの場合は相手の発話内容だけでなく、その声音や表情、仕草といった多様な情報を取ることができます。それと対応し、自分自身もどういった口調で発話するのか、どういうジェスチャーを繰り出すのかを検討する必要があります。こちらを担当するのがAction Generationで、こうした多様な表現も扱える/扱わなければならない点が対話ロボットの難しさになります。
なお、現時点でこれらの要素を効果的に活かしたロボットは個人的には見たことがありません(定型的な仕草とかはありますが)。また、活用するのもとても難しいです。
人とテキストでやりとりする(あるいは指定された音声コマンドなどに反応する)のと、「コミュニケーション」を成立させるのは彼我の断崖があります。そういった意味では、パートナーとしてのロボットが登場するのはまだまだ先になると思います。
とはいえ、研究は着実に進められています。以降では、各パートにおける参考文献を紹介していきたいと思います。
Observation
主に感情や動きの推定といったところで研究が行われています。
Emotion
- Speech Emotion Recognition Using Deep Neural Network and Extreme Learning Machine
- Speech emotion recognition combining acoustic features and linguistic information in a hybrid support vector machine-belief network architecture
- A prosody-based vector-space model of dialog activity for information retrieval
- Emotion Recgnition from Facial Expression and Speech
Motion
-
Multimodal Deep Learning
- 制限付きボルツマンマシンを利用した特徴抽出に関する研究
- 深層学習に基づく行動に着目したシーン抽出手法
最近ではOpenPoseが公開されたので、今までのKinect使うしかねーか的な状況は徐々に改善していくかもしれません。
Request Understanding
相手の行動意図を推定するパートです。発話意図の推定はたくさん研究があるので、ここでは画像などを含めたマルチモーダルな情報を使った意図推定の研究を紹介します。
Engagement
今、対話状態に入れるか?という状態推定に関する研究になります。これに関しては、Microsoft Researchの以下の論文が参考になります。
- Directions Robot: In-the-Wild Experiences and Lessons Learned
- Managing Human-Robot Engagement with Forecasts and… um… Hesitations
Directions~の論文についてはまとめ記事にまとめています。

こんな感じで実際のオフィスにロボット(NAO)を置いて、会議室の案内をさせるという実験をさせています。普通に読んでも面白い論文です。
Action Plannning
最重要となる、対話/行動管理のパートになります。
このパートでは、POMDP(Partially Observable Markov Decision Process)という手法がよく利用されます。これは名前の通り「部分観測」、つまり状況が完全には観測できないけど適切な行動を取らないといけないシーンで利用される手法です。音声対話のシステムでは相手の発話が完全に聞き取れることは稀なので、そのキャッチアップとしても活用されます。
このPOMDPを利用した対話システムに関する研究が以下になります。
POMDPを利用した対話システムの全体像については、以下にとてもよくまとまっています。これ以上にわかりやすく、また網羅的な文書は見たことがないので、まずはこちらから目を通すと良いと思います。
あとは、Neural Networkを利用した、特にSeq2Seqと呼ばれる文から文を生成するようなモデルがよく活用されています。
- A Neural Conversational Model
-
Stochastic Language Generation in Dialogue using Recurrent Neural Networks with Convolutional Sentence Reranking
- こちらはまとめ記事を書いています
-
Building End-To-End Dialogue Systems
Using Generative Hierarchical Neural Network Models
- これを利用した対話Botの作成も行なっています。
そして、ロボットならでは、相手の発話以外の情報の活用についても研究が行われています。
-
Building and Learning from a Contextual Knowledge Base for a Personalized Physical Therapy Coach
- リハビリを指導するパーソナルトレーナーの構築を試みる論文。まとめ記事を書いています。
-
Classifying Student Dialogue Acts with Multimodal Learning Analytics
- Javaを教えるチューターの作成についての研究で、生徒の姿勢を意図推定の手掛かりに使っています。こちらもまとめ記事を書いています。

(こんな感じで、Kinectで姿勢をとっている)
- Automatic Learning and Evaluation of User-Centered Objective Functions for Dialogue System Optimisation
-
Recurrent Polynomial Network for Dialogue State Tracking
- ルールベースとRNNを組み合わせた対話。
- 提案に対しユーザーの反応が+か-かという確率(これをルールで定義する=つまり、ここで言うルールはユーザーの状態推移に関するものであり、システムのアクションに関するもの(ユーザーがAと言ったらBをするなど)ではないので注意)を制約として導入したうえで確率的対話モデル(POMDP)を最適化するという先行研究(CMBP)について、最適化におけるパラメーター推定にRNNを導入したのが本論文。
Content Understanding
対話における外部知識の活用は多くの論文がありますが、あまり深くは追えてません。。。こちらは結構面白かった論文です。
Action Generation/Action Context
行動履歴の活用については、対話システムの中で論じられることが多いです(Action Planningに組み込まれている)。
研究動向の追い方
上記のような研究は、以下の学会で発表が行われています。論文を探す際は、各学会で採択されている論文などから追ってみると良いと思います。
- AAAI: アメリカ人工知能学会
- ACL: 「自然言語処理でもっとも権威があり、かつ採択率も低いトップカンファレンス」
- SIGdial: ACLのSIG(Special Interest Group)の1つ
- NAACL: 「North American Chapter of ACL。北米で開催される ACL 」「ACL に次いでレベルが高い」
- ICML: International Conference on Machine Learning
- NIPS: ICMLに続く歴史を持つ機械学習系の学会
- LREC
- EMNLP
- COLING
- ISCA: International Speech Communication Association
- Interspeech: ISCA が毎年開催する国際会議
以上が、研究時にリサーチしたもののまとめになります。研究のお役に立てば幸いです。