ChainerでSlack用のbot作成!!
注意:chainer 1.5.1以降のバージョンで動作を試みるとSegmentation faultのバグが出ます
pip install chainer=="1.5.1"
で1.5.1をインストールしてください。
突然ですが、あなたはこんな衝動にかられたことはないでしょうか?
Slack上で面白い返事やつぶやきをしてくれるbotやいろんな質問に答えてくれるボットがいれば、会話が盛り上がるし、聞きづらい質問にも答えてくれるのに・・・
私も思ったことがあります。そこで実装してみました。
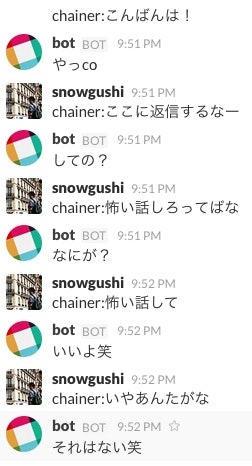
最終的にこんな感じの応答を返してくれるようになります。
対象読者
1:中身は分らなくも良いから賢くなるbotを作ってみたい!!
やるべきアクション:下記リポジトリをgit cloneして環境構築して、実行して下さい!!
2:中身も知って賢くなるbotを作ってみたい!!
やるべきアクション:この記事を読んで仕組みを理解してからgit cloneして環境構築して、実行して下さい!!
3:ガチの人
やるべきアクション:アドバイス下さい。お願い致します。
全体構成
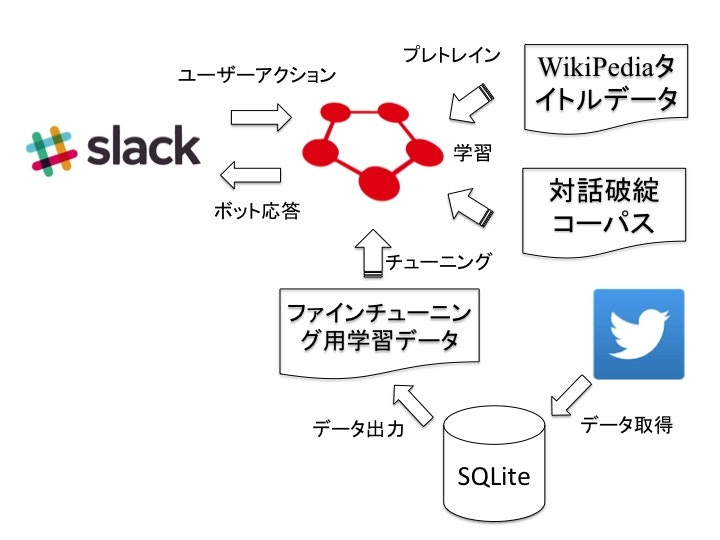
Chainerによる対話モデルの学習

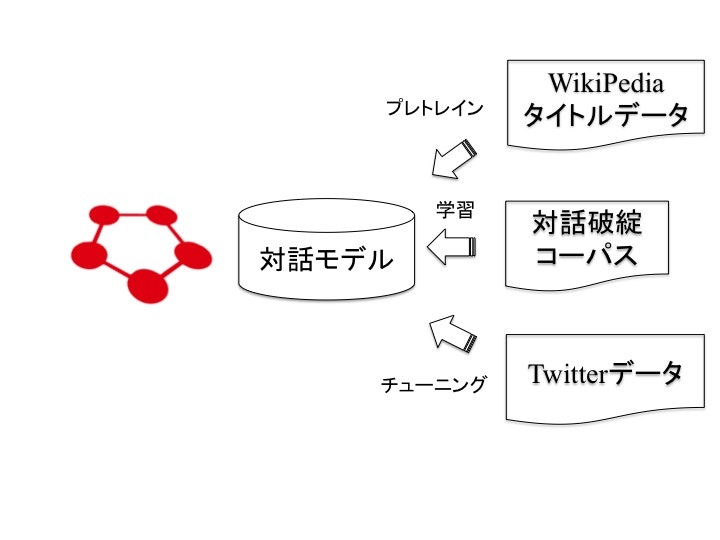
まずはこの仕組みの根幹となる部分のChainerによる対話モデルから説明していきます。
参考にしているのは下記の論文です。
ではここで対話モデルを学習するまでの構成図を下記に示します。
1:Word2Vecで良い初期値を得るための下準備
使用データは下記のWikipediaのデータからタイトルデータ5000行をランダムに抽出
コードは下記を参考に実装
語彙数:5000
隠れ層のユニット数:300
上記の数字は対話モデルの語彙から潜在層に写像する層のユニット数に合わして下さい。
*注意事項
対話学習の際に使用するコーパス内での未知語がない方が良いので抽出されたデータと対話破綻コーパスデータの両者をマッチング。対話破綻で検出された未知語を追加という形にしておく方が良いです。
具体的な流れは下記になります。
1:抽出したデータでWord2Vecを学習
2:学習したデータと対話破綻コーパスデータでマッチングしないデータがないか確認
3:マッチングしないデータが検出されたら、Word2Vecの学習データに追加
4:収束するまで学習
2:得られた初期値を使用して、End to Endのニューラル対話モデルを構成
使用データは下記の対話破綻コーパスを使用(データがないため)
mecab で分かち書きをしてから使用してください。
コードは下記のchainer1.5バージョンのmt_s2s_encdec.pyを参考に実装
3:Twitterから取得したデータを用いて、再学習
この手法の良い点は良い初期値を得るための工夫をいくつも加えることで、Twitterで取得したデータを用いても適切に学習が進むことです。
また非常に強力な点はテキスト情報だけでなく、画像情報、音声情報も入力として入れることが可能という点です。
論文では、提案されているが実装出来ていない機能(本記事では実装できていないので今後、実装したいと思います。)
1:Bi-Directional-RNNを用いる事で最初から最後、最後から最初の両方向からの対話の流れを考慮
2:対話のデータセットもユーザーアクション→応答→ユーザーアクションのトリプルセットで学習することで単純な質問応答ではなく前回の質問も考慮した返答を行なう
3:トリプルセットを事前学習に使用
4:トリプルセットのユーザーアクション、応答を利用して最終的なユーザーアクションをMAP推定により推定
モデルの構成自体は翻訳と同様なので、下記の記事が翻訳モデルを実際に実装された方の記事なので参考にされると良いと思います。
細かい説明は下記のipython notebookで確認できます。
変更した点はWord2Vecによる事前学習の部分です。
下記の記事を参考にしました。
if dec_flag:
if dst["weight_jy"] and child.name == "weight_xi" and self.word2vecFlag:
for a, b in zip(child.namedparams(), dst["weight_jy"].namedparams()):
b[1].data = a[1].data
print('Copy weight_jy')
変更した部分が事前学習にユーザー入力部だけでなくシステム応答部分の初期値もWord2vecで最適化した値を使用したかったため、上記のようなコードで指定していますが、明らかなハードコーディングなので、後で修正しておきます。
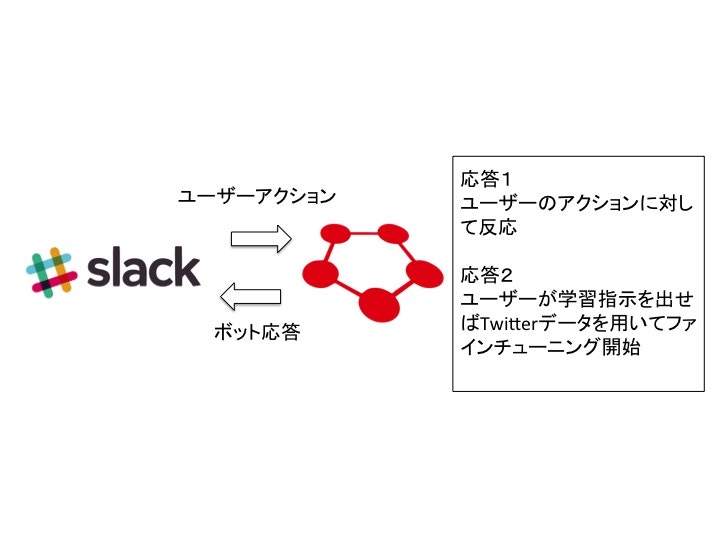
Slackによるbotの応答

下記のリポジトリを使用しました。
Slackの連携に必要な情報の取得
下記のサイトが非常に参考になりました。キーの取得だけでなく、今回はユーザーリストとチャネルの指定方法なども参考になった点が良かったです。
Slackで情報を取得する際のapiサイト
Slackのapiトークンを取得するサイト
Slackでユーザー情報を取得するときに使用
Slackでチャネル情報を取得するときに使用
使用例:ユーザー情報を取得したい場合は下記を入力すると取得可能
機能概要
1:Web SocketによりSlack上の反応を監視
2:特定のキーワードを観測したら、反応
3:反応は今回は応答と学習に分けている
応答の場合のキーワード: chainer:呼びかけの言葉
学習の場合のキーワード: chainer_train
学習はファインチューニングを採用して、事前に学習したモデルに対してさらに学習を進めることでより高度なモデルに変更しています。
def __input_sentence(self):
#1
text = self.__mecab_method(self.data[0]["text"].replace("chainer:", ""))
#2
data = [text]
src_batch = [x + ["</s>"] * (self.generation_limit - len(x) + 1) for x in data]
return src_batch
def __predict_sentence(self, src_batch):
#1
dialogue = EncoderDecoderModelForwardSlack(self.parameter)
#2
src_vocab = Vocabulary.load(self.model_name + '.srcvocab')
trg_vocab = Vocabulary.load(self.model_name + '.trgvocab')
#3
model = EncoderDecoder.load_spec(self.model_name + '.spec')
serializers.load_hdf5(dialogue.model + '.weights', model)
#4
hyp_batch = dialogue.forward(src_batch, None, src_vocab, trg_vocab, model, False, self.generation_limit)
return hyp_batch
上記は応答時のコードの一部を抜粋しています。上記の__input_sentenceで入力されたユーザーの文章をchainerで処理できる形に変更して__predict_sentenceで対応する文章を予測して返しています。
インプットされた文章に関しての処理は
1:Mecabで分割処理
2:確率的勾配法で処理しているので単一の文章でも同様の処理が出来るデータ形式に変更
予測に関しての処理は
1:予測用のモデルを作成
2:入力単語と応答単語の語彙を設定
3:モデルの詠み込み
4:応答仮説の予測です。
#1
self.__setting_parameter()
#2
model = EncoderDecoder.load_spec(self.model_name + '.spec')
dialogue = EncoderDecoderModelForwardSlack(self.parameter)
serializers.load_hdf5(dialogue.model + '.weights', model)
#3
dialogue.encdec = model
dialogue.word2vecFlag = False
dialogue.train()
上記はファインチューニング時のコードの一部を抜粋しています。
1:ファインチューニング時に使用する学習データなどの指定を行なう
2:予め予備学習したモデルの詠み込み
3:モデルを設定して、学習したモデルのパラメータを使用する設定をオンにする。

Twitter関連の処理はTwitterからデータを取得して、SQLiteに保存。SQLiteから学習用のデータを取得するようにしています。
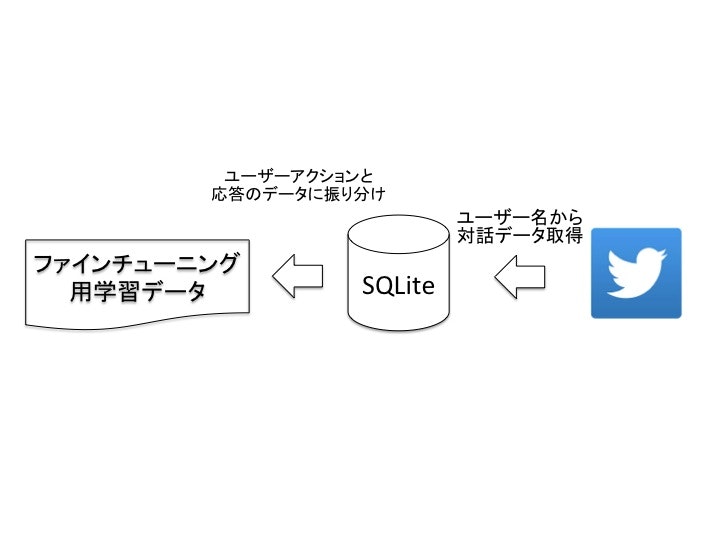
1:Twitterから会話データを取得
2:SQLiteに保存
3:SQLiteから、ユーザーアクションとシステム応答に振り分けておく
直接貯めずにSQLiteに保存することでデータを必要な時に必要な分だけ学習できる仕組みになっており、ファインチューニングに重要な速度性を担保することを考慮しています。
Twitterで会話データの取得方法
1:ユーザー指定でつぶやきを取得。その際にin_reply_to_status_idとin_reply_to_screen_nameを取得
2:取得したin_reply_to_screen_nameでつぶやきを取得しin_reply_to_status_idが一致するつぶやきを取得
3:つぶやきと応答の辞書を作成してSQLiteに保存
総括
今回は冬の長期休暇を利用して、Chainer + Slack + Twitter連携を行なってみました。
Chainerは1.5から少ないコードで強力な機能も簡単に使えるようになってきており、他のニューラルネットのツールも出て来ていますが、個人的には好きなので今後も使っていこうと思っています。
参考