Pandasのグラフ描画機能
この記事ではPandasのPlot機能について扱います。
Pandasはデータの加工・集計のためのツールとしてその有用性が広く知られていますが、同時に優れた可視化機能を備えているということは、意外にあまり知られていません。

この機能は Pandas.DataFrame.plot() もしくは Pandas Plot と呼ばれるものです。
Pandas Plotを使いこなすことが出来るようになれば、
- データの読み込み、保持
- データの加工
- データの集計
- データの可視化
というデータ分析の一連のプロセスを全てPandasで完結させることが出来る、つまり分析の「揺りかごから墓場まで」を実現することが出来ます。
Pandasのプロット以外の機能について
この記事ではPandasのデータハンドリングなどに関わる機能は説明しません。
そちらにも興味がある方は下記の記事などを参考にしてください
Python Pandasでのデータ操作の初歩まとめ
http://qiita.com/hik0107/items/d991cc44c2d1778bb82e
Pythonでのデータ分析初心者がまず見るべき情報源のまとめ
http://qiita.com/hik0107/items/0bec82cc09d0e05d5357
Pandas Plotとはなんなのか
Pandas PlotはPandasのデータ保持オブジェクトである "pd.DataFrame" のいちメソッドです。
pd.DataFrame.plot() はmatplotlibの薄いWrapperとして存在する。
pandasのplotは非常に簡単にイケてるプロットを作成する機能がある。
The plot method on Series and DataFrame is just a simple wrapper around plt.plot():
We provide the basics in pandas to easily create decent looking plots
- 公式ドキュメントより
Pandasのplotメソッドでサポートされているグラフの種類は下記の通り
またpandasのver0.17以上であれば、さらに多くの種類のグラフが用意されています。
- bar (barh) : 棒グラフ もしくは 横向き棒グラフ
- hist :ヒストグラム
- box : 箱ひげ図
- kde :確率密度分布
- area : 面積グラフ
- scattter : 散布図
- hexbin :密度情報を表現した六角形型の散布図
- pie :円グラフ
Pandas Plotの文法上の特徴
"Pandas Plot" はPandas.DataFrameという、データオブジェクト自身のメソッドであることに由来して、通常のチャート作成ライブラリとはやや違いがあります。
違いというか、利点と言ってしまってもいいかもしれません。
大抵の場合は相対的に言ってシンプルに記述することが可能です。
例として、PandasPlotと同様にMatplotlibのラッパーであるビジュアライズライブラリの seabornと文法を比較してみます。
df.plot.scatter(x='xdata', y='ydata')
sns.jointplot(x='xdata', y='ydata', data=df)
seabornのように data=dfみたいな記述をしなくてよいのが良い!可読性も上がる!
(効果には個人差があります)
また、x軸に使うのがDataFrameのIndexである場合にはさらに簡単です
df.plot.scatter(y='ydata') # xの指定は省略可能
補足-seaborn
seabornについてはよければ下記の記事を参照して下さい
pythonで美しいグラフ描画 -seabornを使えばデータ分析と可視化が捗る
http://qiita.com/hik0107/items/3dc541158fceb3156ee0
各種のチャートの紹介
実際にコードを書いて動かしながら進められるように、データのDLから始めます
# グラフ化に必要なものの準備
import matplotlib
import matplotlib.pyplot as plt
# データの扱いに必要なライブラリ
import pandas as pd
import numpy as np
import datetime as dt
下記のおまじない設定をしておくとチャートが綺麗にかけます
plt.style.use('ggplot')
font = {'family' : 'meiryo'}
matplotlib.rc('font', **font)
こんな感じ適当にデータを作ります
url = 'https://vincentarelbundock.github.io/Rdatasets/csv/robustbase/ambientNOxCH.csv'
df_sample = pd.read_csv(url, parse_dates=1, index_col=1)
# dfの準備
df = df_sample.iloc[:, 1:]
# df_monthlyの準備
df_monthly = df.copy()
df_monthly.index = df_monthly.index.map(lambda x: x.month)
df_monthly = df_monthly.groupby(level=0).sum()
このdfとdf_monthlyで色んなグラフを書いてみます
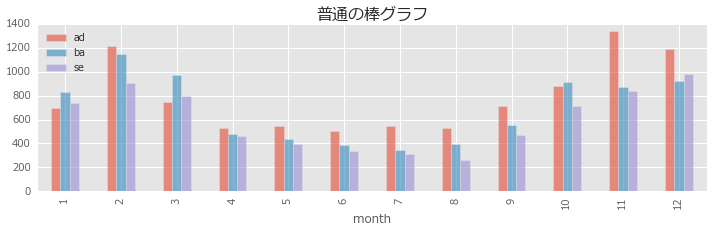
棒グラフ
df_monthly.plot.bar(y=['ad', 'ba', 'se'], alpha=0.6, figsize=(12,3))
plt.title(u'普通の棒グラフ', size=16)
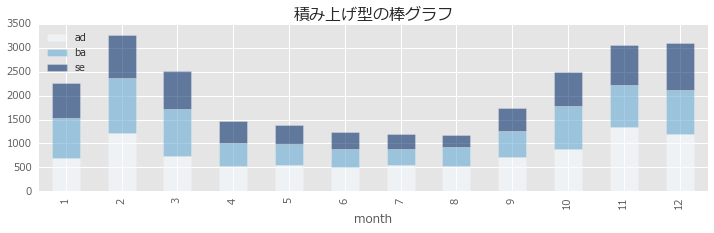
3つのカテゴリを合わせて一本のバーにしたい場合は
df_monthly.plot.bar(y=['ad', 'ba', 'se'], alpha=0.6, figsize=(12,3), stacked=True, cmap='Blues')
plt.title(u'積み上げ型の棒グラフ', size=16)
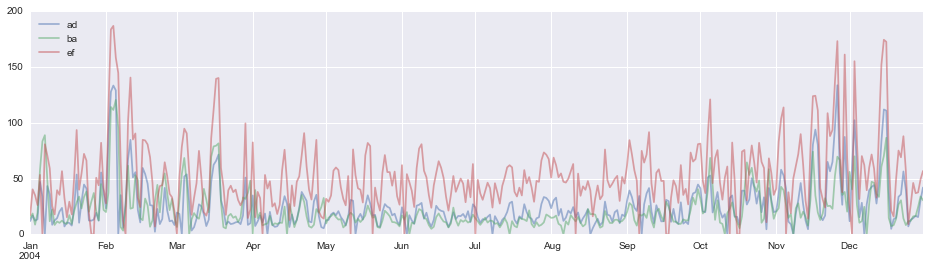
時系列グラフ
df.plot( y=['ad', 'ba', 'ef'], figsize=(16,4), alpha=0.5)
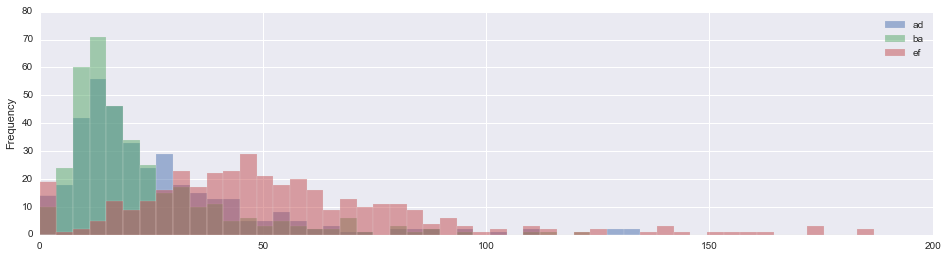
ヒストグラム
ax= df.plot( y=['ad', 'ba', 'ef'], bins=50, alpha=0.5, figsize=(16,4), kind='hist')
散布図
色を塗り分けたり、サイズを描き分けたり色々出来る
fig, axes = plt.subplots(2, 2, figsize=(14, 10), sharey=True)
# 1.普通のプロット
df[0:150].plot(x='ad', y='ba', kind='scatter', ax=axes.flatten()[0])
# 2.離散値を色で表す
df[0:150].plot(x='ad', y='ba', kind='scatter', c='ef', cmap='Blues', ax=axes.flatten()[1])
# 3.離散値をバブルサイズで表す(ちょっと数は減らしてる)
df[0:150].plot.scatter(x='ad', y='ba', s=(df['su']-20)*3, ax=axes.flatten()[2])
# 4.両方同時に使う
df[0:150].plot.scatter(x='ad', y='ba', s=(df['su']-20)*3, c='ef', ax=axes.flatten()[3])
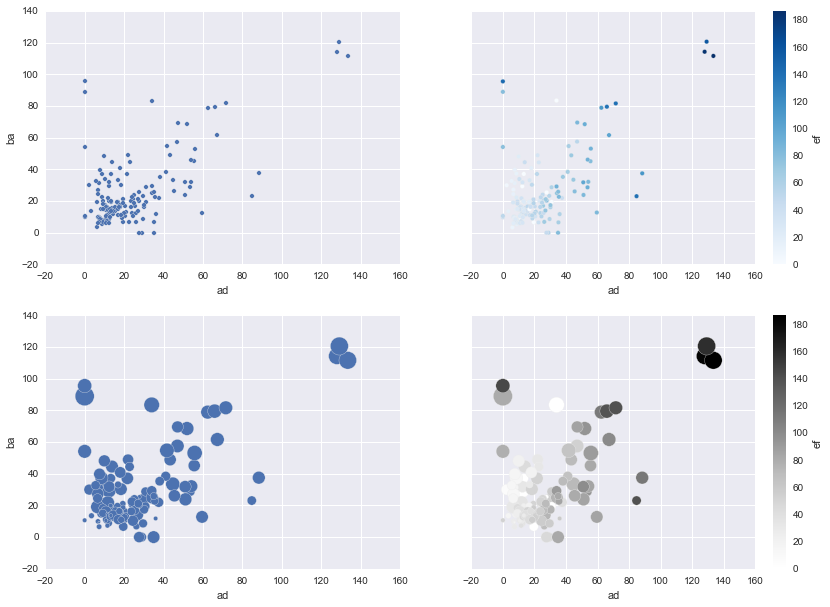
なんかカッコイイ!
散布図とちょっと違うがこういうのもある
Hexabinというらしいです。
df[0:150].plot(x='ad', y='ba',kind='hexbin', gridsize=20)
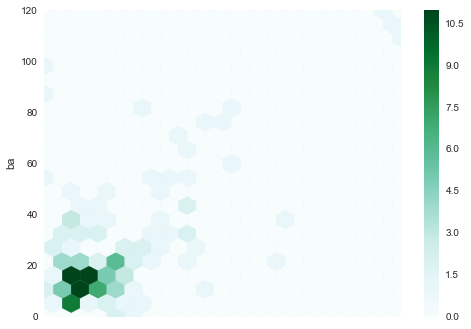
その他
円グラフ(あんまり使わない)
df_monthly.plot( kind='pie', y = 'se')
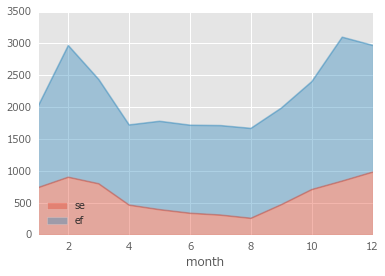
エリアチャート(あんまり使わない)
df_monthly.plot(y=['se', 'ef'], kind='area', stacked=True, alpha=0.4)
まとめ
Pandasのプロット機能マジ便利。
データの読み込みから分析、グラフ化まで一気に出来て最高。