InfluxDB が面白そうなので、本番投入前に fluentd と組み合わせて使うとどうなるのか検証してみました。主に fluent-plugin-influxdb の仕様の確認。検証なので、Mac OS X での手順のみ。
ソースだけ見たいという人は github に置いてあります。
InfluxDB のインストールと起動
$ brew install influxdb
$ ln -sfv /usr/local/opt/influxdb/*.plist ~/Library/LaunchAgents
$ brew services start influxdb
テスト用DBの作成
$ curl -X POST 'http://localhost:8086/db?u=root&p=root' -d '{"name": "test"}'
サンプルプロジェクトの取得
$ git clone https://github.com/hakobera/fluent-influxdb-test
$ cd fluent-influxdb-test
$ bundle install
Fluentd の起動
$ bundle exec fluentd -c conf/fluent.conf
fluent.conf は以下のようになっています。
<source>
type tail
path temp/dummy.log
pos_file temp/dummy.log.pos
tag dummy.test
format ltsv
</source>
<match dummy.*>
type influxdb
host localhost
port 8086
dbname test
user root
password root
time_precision s
</match>
dummer でダミーデータの投入
別のコンソールを開き、dummer でダミーデータを投入します。
$ mkdir temp
$ bundle exec dummer -c conf/dummer.conf
これで、Fluentd 経由で、influxdb にデータが溜まっていきます。
クエリを投げてみる
URLごとのリクエスト回数を10秒毎に集計するクエリを書いてみます。
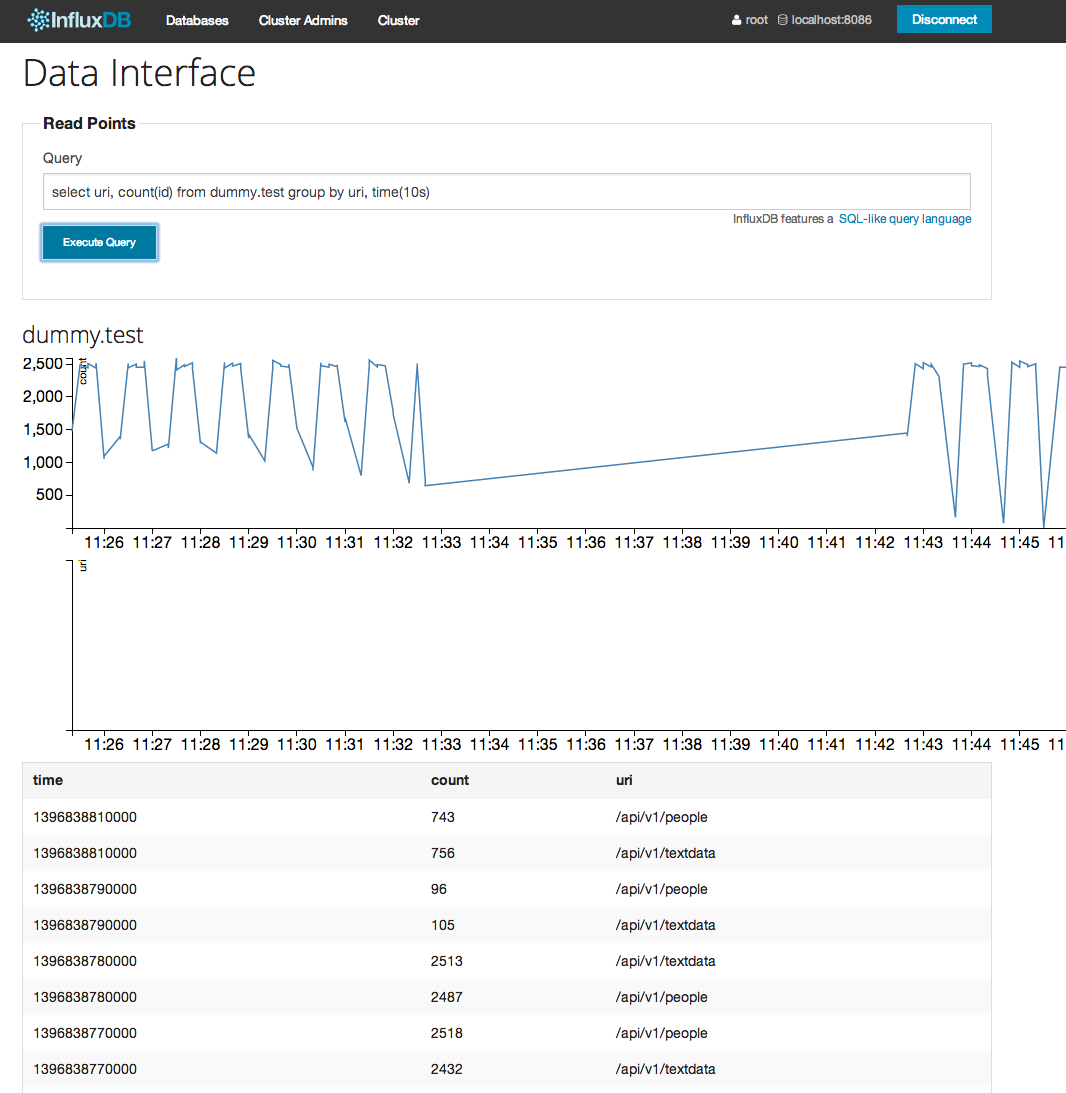
SELECT uri, COUNT(id) FROM dummy.test GROUP BY uri, time(10s)
クエリは HTTP API 経由で、/db/test/series?u=root&p=root&q=QUERY という形式で投げます。curl の場合は、こんな感じ。
$ curl "http://localhost:8086/db/test/series?u=root&p=root&q=SELECT%20uri%2C%20COUNT(id)%20FROM%20dummy.test%20GROUP%20BY%20uri%2C%20time(10s)"
GUI (http://localhost:8083) で確認するとこんな感じ。
わかったこと
- fluent-plugin-influxdb は、タグ名を InfluxDB の series 名にする
今後検証すること
- InfluxDB は、ネストした JSON をサポートしていないので、Flat化する plugin を試す