簡潔に言うと、BigQuery の COUNT(DISCTINCT(X)) は正しい値を返さないことがあるので使わない方が良い。(ちゃんと仕様を理解して使おう)
2015/5/28 追記
「GROUP BY して COUNT()」が面倒だという人は、EXACT_COUNT_DISTINCT(X) を使おう。
BigQuery では COUNT(DISTINCT(X)) ではなく EXACT_COUNT_DISTINCT(X) を使おう
BigQuery の DISTINCT の仕様
https://cloud.google.com/bigquery/query-reference?hl=ja#aggfunctions より引用
Returns the total number of non-NULL values in the scope of the function.
If you use the DISTINCT keyword, the function returns the number of distinct values for the specified field. Note that the returned value for DISTINCT is a statistical approximation and is not guaranteed to be exact.
If you require greater accuracy from COUNT(DISTINCT), you can specify a second parameter, n, which gives the threshold below which exact results are guaranteed. By default, n is 1000, but if you give a larger n, you will get exact results for COUNT(DISTINCT) up to that value of n. However, giving larger values of n will reduce scalability of this operator and may substantially increase query execution time or cause the query to fail.
要するに、オプションで指定した精度(デフォルトで1000)以上の数字は概算値が返るということです。よって概算値が欲しいというケース以外で DISTINCT を使うのは正確性という意味で良くないのです。
例
実際に publicdata:samples.github_timeline にクエリを流して試してみましょう。
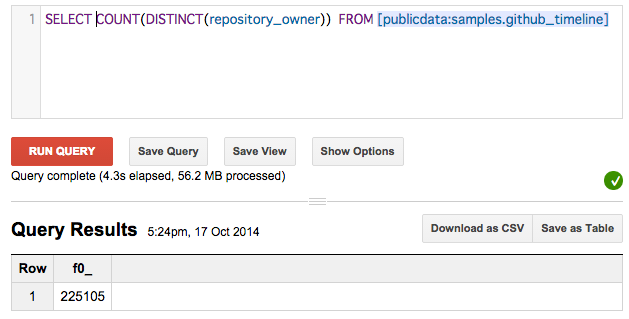
精度デフォルト(=1000)
SELECT COUNT(DISTINCT(repository_owner)) FROM [publicdata:samples.github_timeline]
/* => 225,105 */
精度 100,000
SELECT COUNT(DISTINCT(repository_owner), 1000000) FROM [publicdata:samples.github_timeline]
/* => 220,724 */
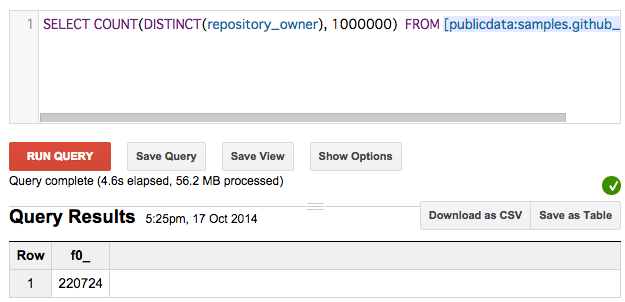
ここでは数字が100万以下なので、後者が正確な値。
精度を上げていけば正確な値が得られるとはいえ、実際に実行してみるまで桁数なんてわからないし、データが増えていくたびに精度を調整してくなんてやりたくない。
回避策
この問題に対するBigQuery的な正解は、GROUP EACH BY と COUNT(*) を組み合わせて使うこと。
https://cloud.google.com/bigquery/query-reference?hl=ja#aggfunctions より引用
To compute the exact number of distinct values in a scalable fashion, consider using GROUP EACH BY on the relevant field(s) and then applying COUNT(*). This approach is more scalable but might incur a slight up-front performance penalty.
SELECT COUNT(*)
FROM
(SELECT repository_owner FROM [publicdata:samples.github_timeline]
WHERE repository_owner IS NOT NULL
GROUP EACH BY repository_owner)
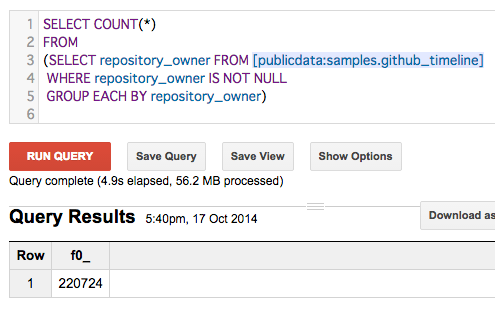
集計対象列が NULLABLE な場合、WHERE X IS NOT NULL を忘れずに。NULLABLE ではない場合は、WHERE 句は不要です。
まとめ
BigQuery で DISTINCT したい時は、「GROUP EACH BY して、COUNT を取る」を覚えておきましょう。