以前、COUNT(DISTINCT(X)) の代わりに GROUP BY して COUNT(X) しようという記事を書きました。
BigQuery で COUNT(DISTINCT(X)) を使わない方が良い理由
が、今は時代が変わりました。BigQuery にいつの間にか、EXACT_COUNT_DISTINCT() 関数が追加されたのです!
Returns the exact number of non-NULL, distinct values for the specified field. For better scalability and performance, use COUNT(DISTINCT field).
さらに non-NULL な値だけを数えてくれるという嬉しい仕様です。
というわけで、前の記事と同じく実際に publicdata:samples.github_timeline にクエリを流して試してみましょう。
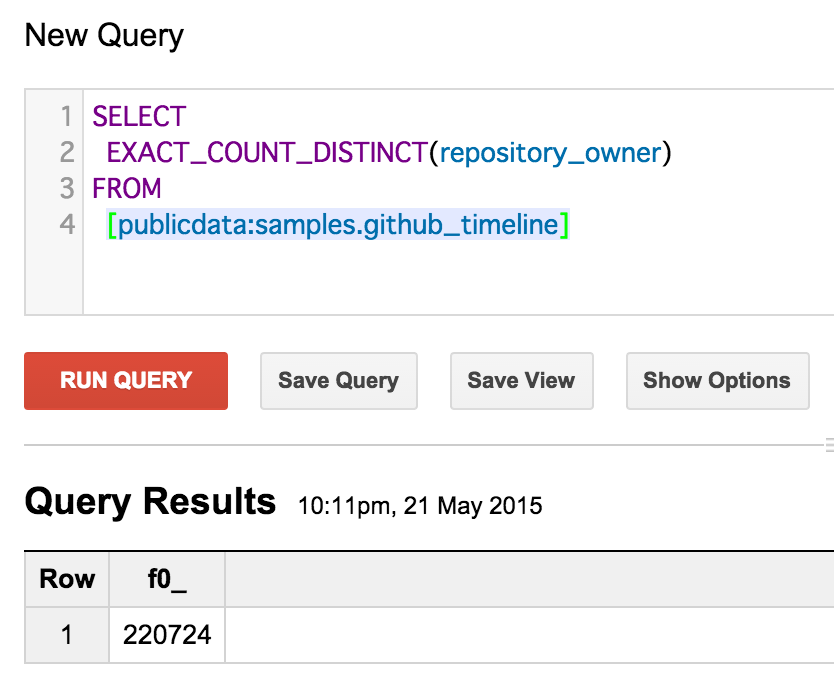
まずは、EXACT_COUNT_DISTINCT を使った場合。
SELECT
EXACT_COUNT_DISTINCT(repository_owner)
FROM
[publicdata:samples.github_timeline]
次に、検証のために GROUP BY して COUNT するパターン。
SELECT COUNT(*)
FROM
(SELECT repository_owner FROM [publicdata:samples.github_timeline]
WHERE repository_owner IS NOT NULL
GROUP EACH BY repository_owner)
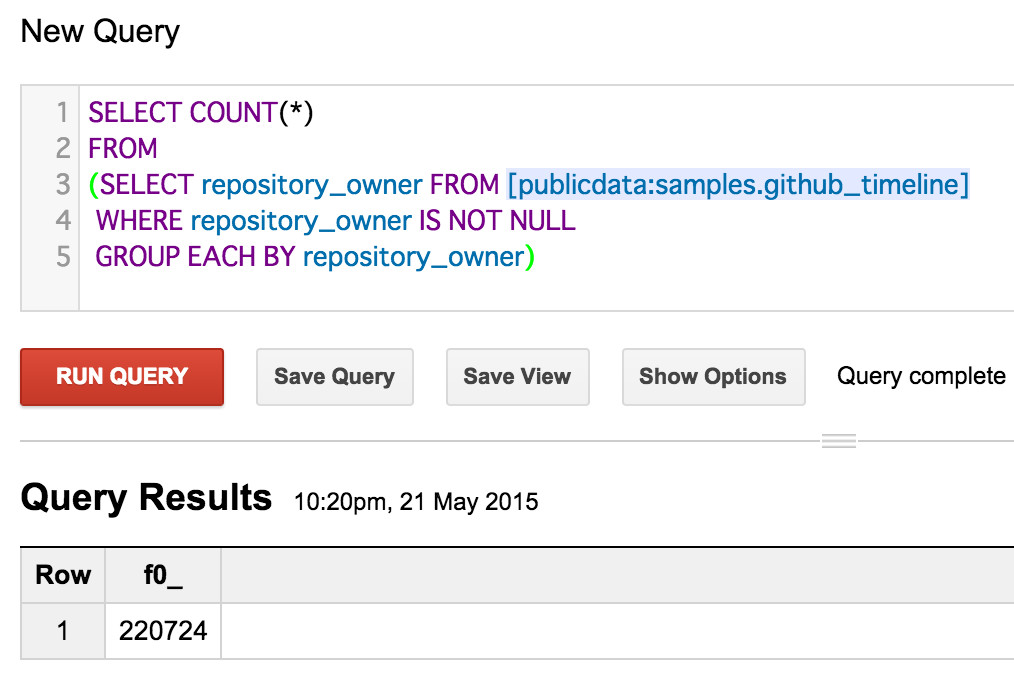
結果が一致してます。素晴らしい!
データ増えてくると GROUP BY する方法の方がスケールする(遅くならない)ようで注意が必要ですが、クエリがシンプルに書けるようになるのでうまく使って行きたいですね。