背景
リアルタイムに値の変わるデータがWEB上にありました。その値を定期的にチェックするプログラムを作ることになったわけですが、ページにログインする必要があったりと、スクレイピングのコードを書くのが面倒でした。その対策としてseleniumを使ってWebブラウザを操作し、スクレイピングをすることにしました。その過程を備忘録的にまとめていきます。
なお、手元のPCを使い、Webブラウザをバッチ処理で自動実行しても良かったのですが、、、普段使いの自身のPC上で、勝手にWebブラウザが立ち上げるのは邪魔だったので、レンタルサーバ上(Ubuntu16.04)で勝手に動かすようにします。
より具体的には以下のイメージになります。
(1)python経由でWebブラウザを立ち上げる → Part1で説明
(2)seleniumでWebブラウザを操作し、WEBデータを処理する → Part2(本投稿)で説明
(3)処理したデータをmongoDBに格納する → Part3で説明
(4)(1)〜(3)を実行するpyプログラムをcronで自動実行する → Part3で説明
(5)値に一定の変動があった場合メールで知らせる → おまけ編で説明
前回はUbuntu上でpythonからWebブラウザ(PhantomJS)を起動するところまでを書きましたが、
今回は、実際にスクレイピングしてほしい情報を入手したいと思います。
Step1) ログインのあるWebページをseleniumで自動的にログインする
前回の「目的」にも書いた通り、私の本来の目的は、ログインがあるWebページにおいて、ログイン後のデータを定期的に取得してDBに格納することです。実際にデータを自動取得するページについては、ここでは書けませんので、例としてQiitaに自動ログインするpythonプログラムを以下に示します。
import time
from selenium import webdriver
URL = "https://qiita.com/"
USERID = "<YOUR_USER_ID>"
PASS = "<YOUR_PASSWORD>"
# PhantomJSの自動起動とQiitaへのアクセス
browser = webdriver.PhantomJS(executable_path='<path/to/phantomjs>')
browser.get(URL)
time.sleep(3)
# ログインページ
browser.find_element_by_id("identity").send_keys(USERID)
browser.find_element_by_id("password").send_keys(PASS)
browser.find_element_by_xpath('//input[@name="commit"]').click()
time.sleep(5)
print(browser.title)
browser.close()
display.stop()
上記を実行後、「ホーム - Qiita」と出力されます。ログイン後の自身のアカウントのトップ画面にアクセスできていることが分かります。
Step2) BeautifulSoup4をインストールする
せっかくなので、PhantomJSでアクセスしたページをスクレイピングします。pythonでスクレイピングをする方法はいくつかありますが、今回はBeautifulSoup4で行います。
インストール自体は簡単で、
pip3 install bs4
でOKです。
Step3) ログイン後の画面をスクレイピングする
Qiitaログイン後のトップ画面をスクレイピングしてみましょう。
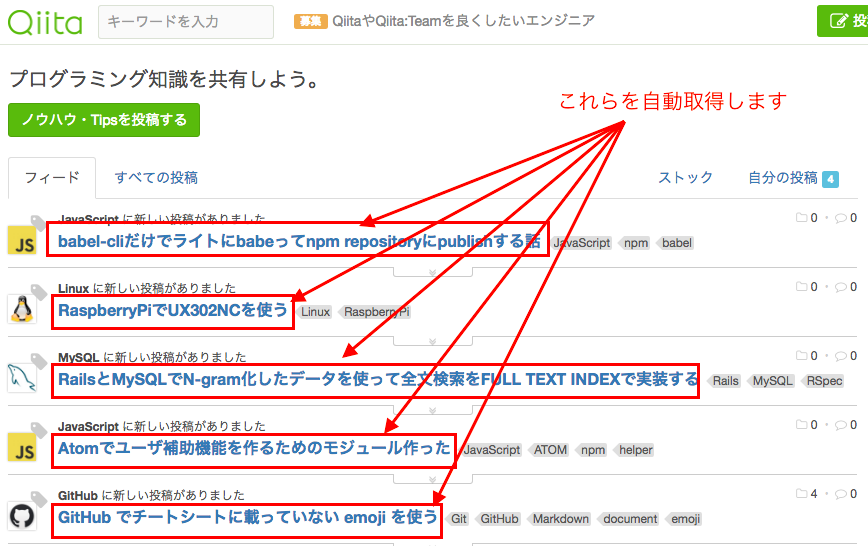
Qiitaログイン後、トップ画面では、フィードタブに最新の投稿一覧が表示されています。最大20個表示されますが、この20個のタイトルを自動取得するプログラムを作ってみましょう。(実用的な意味はあまり無く、あくまで例としてです。。)
▼具体的には、以下の画面のフィードにある投稿名を取得します。
▼プログラムコードは以下のようになりました。
import time
from selenium import webdriver
from bs4 import BeautifulSoup
URL = "https://qiita.com/"
USERID = "<YOUR_USER_ID>"
PASS = "<YOUR_PASSWORD>"
# PhantomJSの自動起動とQiitaへのアクセス
browser = webdriver.PhantomJS(executable_path='<path/to/phantomjs>')
browser.get(URL)
time.sleep(3)
# ログインページ
browser.find_element_by_id("identity").send_keys(USERID)
browser.find_element_by_id("password").send_keys(PASS)
browser.find_element_by_xpath('//input[@name="commit"]').click()
time.sleep(5)
# ホーム画面の投稿一覧の取得
html = browser.page_source.encode('utf-8')
soup = BeautifulSoup(html, "lxml")
posts_source = soup.select(".item-box-title > h1 > a")
# 投稿名の出力
i = 1
for post in posts_source:
print(str(i) + ":" + post.text.strip())
i += 1
browser.close()
display.stop()
▼プログラムの実行結果は、以下のような表示になればOKです。
1:babel-cliだけでライトにbabeってnpm repositoryにpublishする話
2:RaspberryPiでUX302NCを使う
3:RailsとMySQLでN-gram化したデータを使って全文検索をFULL TEXT INDEXで実装する
4:Atomでユーザ補助機能を作るためのモジュール作った
5:GitHub でチートシートに載っていない emoji を使う
....
上記のプログラムコードを見ると分かりますが、selenium経由でブラウザを操作している時、現在開いているページのソースは、
browser.page_source
で取得しました。必要に応じてサンプルのようにencodeメソッドでエンコードしてください。
取得したHTMLコードは、BeautifulSoupオブジェクトに変えて、指定したタグの値を取ってくるようにします。サンプルでは、
posts_source = soup.select(".item-box-title > h1 > a")
で、 div.item-box-titleの子要素のh1タグの子要素aを取ってきています。
BeautifulSoupのスクレイピングの仕方は以下の2サイトが詳しいのでご参照ください。
Qiitaのホーム画面から情報を自動取得するプログラムを例にしましたが、上記のコードを一通り動かすだけでも、このコードが応用範囲が広いことが分かると思います。
今のところ、ブラウザを自動実行して、特定のデータを取得するところまでできました。あとはそのプログラムをCRON等で定期的に実行するだけです。詳細は次回に続きます。