はじめに
形態素解析といえば MeCab、Kuromoji が有名ですが、中でもTinySegmenterの軽量さにはビビってました。
ところが知らぬ間に、楽天さんが、さらにすごいやつをリリースしていました!

https://github.com/rakuten-nlp/rakutenma
- ピュア JavaScript
- 日本語/中国語(簡体字) 対応
- 品詞付き
これはランボーに入れちゃうしかないです!
ランボーとは:http://qiita.com/exabugs/items/e868df55333d0805acb2
AWS設定
Step 1: Lambda設定
-
ランボーのLambda関数を、差し替えます。
-
Lambdaは npm モジュール含みのzipを扱えるのですが、RakutenMA フルパッケージだと 50MByte を超えてしまいます。
-
以下の最小構成なら、zip で 2MByte 弱でいけちゃう
- rakutenma.js
- hanzenkaku.js
- model_ja.min.json (辞書)
-
Lambda関数は以下になります。
(一式はこちら GitHub : https://github.com/exabugs/Lambot-MA )
var fs = require("fs");
var RakutenMA = require("./rakutenma/rakutenma");
var HanZenKaku = require("./rakutenma/hanzenkaku").HanZenKaku;
var model = JSON.parse(fs.readFileSync("./rakutenma/model_ja.min.json"));
rma = new RakutenMA(model);
rma.featset = RakutenMA.default_featset_ja;
rma.hash_func = RakutenMA.create_hash_func(15);
exports.handler = function(event, context) {
// han->zen
var text = series([HanZenKaku.h2z, HanZenKaku.hw2fw, HanZenKaku.hs2fs], event.text);
var tokens = rma.tokenize(text);
tokens = tokens.reduce(function (memo, token) {
// remove white space tokens.
if (token[1] !== 'W') {
// zen->han
token[0] = series([HanZenKaku.fs2hs, HanZenKaku.fw2hw], token[0]);
memo.push(token);
}
return memo;
}, []);
text = tokens.join("\n");
context.done(null, {text: text});
};
// utility
function series(array, input) {
return array.reduce(function (input, func) {
return func(input);
}, input);
}
Step 2: Configure function
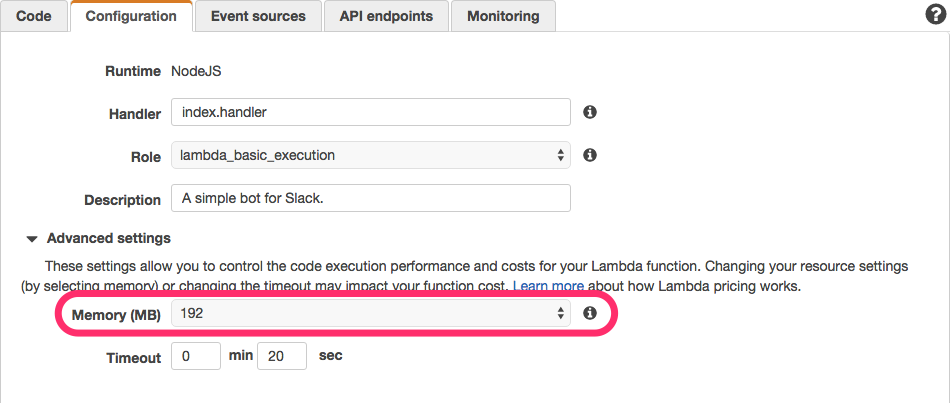
- Memory: 使用メモリを 128 → 192 に増やす必要があります。
確認
Slackで確認してみます。おぉ、ランボーで形態素解析できています!
東京都-京都 問題も、大丈夫ですね。
ランボーが徐々に賢くなってきました。

まとめ
- AWS Lambda 上に、形態素解析が可能な Slack用 ボット (ランボー) を構築しました。
- ランボーは低料金でオートスケール、かつ、インフラ管理が不要です。
- Lambdaでは実行環境(コンテナ)が再利用されるようなので、重めの初期化処理があったとしても、レスポンスが速いです。
注意
- RakutenMA
- min辞書では学習は不可のようです。
- アルファベット6文字以上の連続は処理がおかしい?