はじめに
とあるイベント でQuantopianを使うことになったので、[チュートリアル] (https://www.quantopian.com/tutorials/getting-started) をやってみてポイントとなりそうなところをまとめてみました。
噛み砕いた超意訳なので(ツッコミ歓迎)、ちゃんと確認したい方は公式のドキュメントを参照しえてください。
Quantopianの特徴
Quantopianとはなんぞやとかは こちらの記事 を参考にしていただくとして、筆者がこれはいいなと思った機能を列挙するとこんな感じです。
- クラウドに必要な環境が用意されている
- 最低限の記述でアルゴリズムの評価ができる
- 手数料やスリッページ、マーケットインパクトを自動的に計算してくれる(カスタマイズも可能)
- 取引所のカレンダーが予め用意されている(重要!)
- ポートフォリオを指定した割合で調整してくれる(便利!)
- アルゴリズムを共有したりクローンすることができる
- Jupyter Notebookを用いた分析ができる
- コンテストで優れたアルゴリズムには賞金がでる(Over $110,000 awarded!)
使い方
www.quantopian.com からユーザ登録をし、Research - Algorithms - New Algorithm を選択するとIDEがブラウザ上に表示されます。
テンプレートのコードを色々と編集することで、アルゴリズムを作成し、Build Algorithm を選択すると簡単なテストが走ります。詳しく検証する場合は Run Full Backtest を選択します。
コードを記述する際の独自ルール
Quantopian独自の名前空間や関数名のルールがあります。これがわからないといきなり詰んでしまうため、できるだけ手厚く解説してみます。
contextオブジェクト
なにも定義していないのにグローバルなインスタンスが作成されます。
後述する関数はこのインスタンスの属性にアクセスして必要な情報を得ます。グローバル変数(オブジェクト)を作成せず、この context オブジェクトに任意の属性を加えていくのがお作法のようです。
これは筆者の想像ですが、関数に渡すパラメータをすべて引数にしてしまうと、複数の関数で同じパラメータを共有するのに非効率だったり、docstringが膨大な量になり大変なことになったりするのでこのような設計になったのではないかと。
下記は context オブジェクトの設定例です。このように書くことでアップル社のオブジェクトが作成されます。
context.aapl = symbol('AAPL')
dataオブジェクト
contextと同様に、いきなり存在しています。data オブジェクトには価格情報に関するさまざまなAPIが格納されています。
- 指定した銘柄の四本値と出来高
- 指定した銘柄のヒストリカルデータ
- 価格のデータがstaleになっていないかのチェック
- ボリュームを確認して取引可能かをチェック
- 期近先物のデータ
- 先物のつなぎ足のデータ
下記の例では前述で作成したアップルのオブジェクトから直近の株価を取得しています。
data.current(context.aapl, 'price')
LESSON 2 Core Functions
LESSON 1をすっ飛ばしてLESSON 2からやります。理由としては前述した独自ルールに含まれる、こちらを先に理解すべきと判断しました。
Quantopianのアルゴリズムには3つのコア関数があります。これらは組み込み関数ではなくユーザ自身で定義する必要があります。
initialize()
この名前の関数が必ず必要となります。アルゴリズムのテスト開始時に呼び出されます。引数には context オブジェクトを指定します。
handle_data()
この名前の関数を定義すると、毎分(テスト期間の分毎に)実行されます。価格データを取得したり、ポートフォリオの設定(買ったり、売ったり)をする際に使われます。
引数には context オブジェクトと data オブジェクトを指定します。
日次や週次で実行する場合にはLESSON 7で紹介する schedule_function() 関数を使用します。
before_trading_start()
日次で取引開始前に呼び出されます。当日取引対象とする銘柄を設定する場合などに使われます。
引数には context オブジェクトと data オブジェクトを指定します。
Hello world
チュートリアルに入る前にIDEに慣れておきましょう。
下記のコードを記述して、(Savedとなっていなければ)Save を選択し、Build Algorithm を選択します。
def initialize(context):
print('hello world')
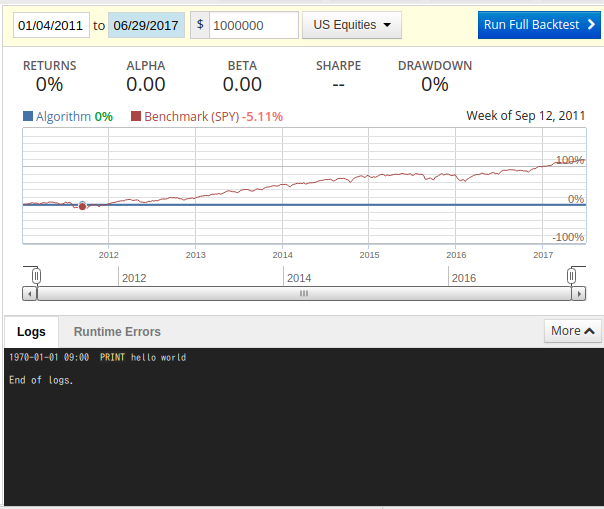
右側のペインに上記のように表示されます。initialize() 関数はアルゴリズム開始時に必ず呼び出されるため print('hello world') が実行されます。標準出力はLogsウィンドウに表示されます。
アルゴリズムの途中経過等をログとして残しておきたい場合には handle_data() 関数にprint を記述おくとよいでしょう。
デフォルトではベンチマークとしてSPY(SPDR S&P 500 ETF)が設定されています。
上記のアルゴリズムではポジションをなにもとっていないため、0%と表示されます。
次にチュートリアルのLESSON 2からアルゴリズムをクローンしてみます。

上記右側の Clone を選択すると、IDEが新しいタブで起動し、アルゴリズムがクローンされます。
Build Algorithm を選択するとアルゴリズムのテストが実行されます。
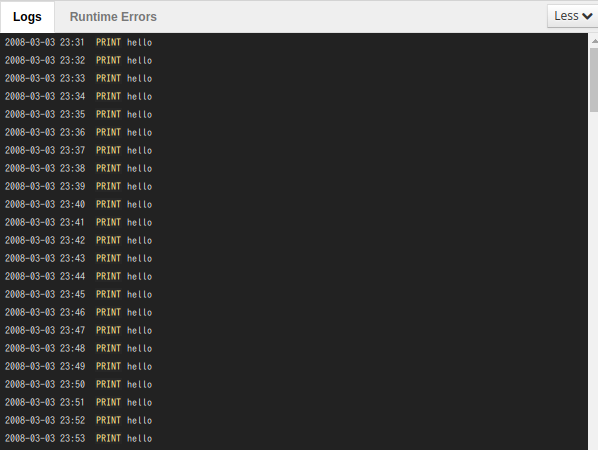
前述したHello worldのときと異なり、分ごとにLogsに出力されてていることがわかります。More を選択するとLogsのウィンドウが大きく表示されます。
LESSON 1 Introduction
チュートリアルのLESSON 1からアルゴリズムをクローンしてみます。
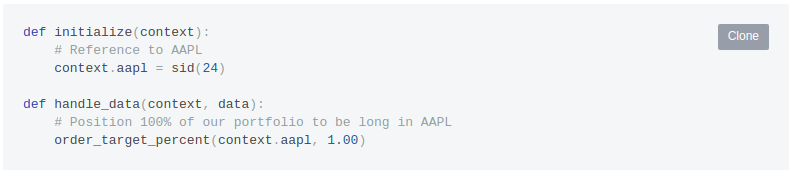
Build Algorithm を選択するとアルゴリズムのテストが実行されます。
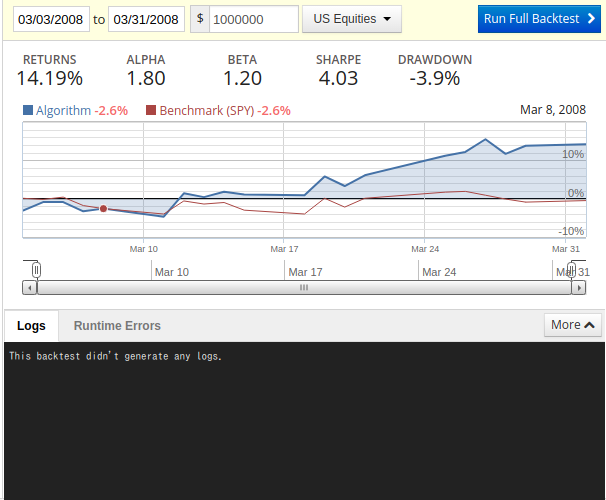
上記のコードではアップル社の株をロングした場合のアルゴリズムです。order_target_percent() の二番目の引数 '1.00' は資金のすべて(100%)を割り当ててることを意味します。order_target_percent() 関数についてはLESSON 4で紹介します。
右側にある Run Full Backtest を選択すると、アルゴリズムの詳しいバックテストが実行されます。
-> LESSON 3